 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Code-Switching ASR with Code-Mixing Guided Synthetic Speech
Jun 14, 2026Code-switch (CS) Automatic Speech Recognition (ASR) remains challenging due to limited availability of high quality CS text-speech pairs for training. Although synthetic data augmentation via Text-to-speech (TTS) has been explored, existing CS TTS approaches primarily optimise reconstruction fidelity and do not explicitly enforce language-boundary consistency, thereby limiting their effectiveness for CS ASR augmentation. This paper proposes a code-mixing guided preference-learning framework that steers synthetic speech generation toward improved code-switching fidelity using the Code Mixing Index (CMI). Experiments on the SEAME Mandarin-English conversational corpus demonstrate that the proposed method enhances the utility of synthetic data for ASR fine-tuning. Specifically, when fine-tuning Whisper Large, the proposed approach reduces Mixed Error Rate (MER) from 12.1%/17.8% to 8.9%/14.2% on the DevMAN and DevSGE sets, respectively.
On Speaker Attribution with SURT
Jan 28, 2024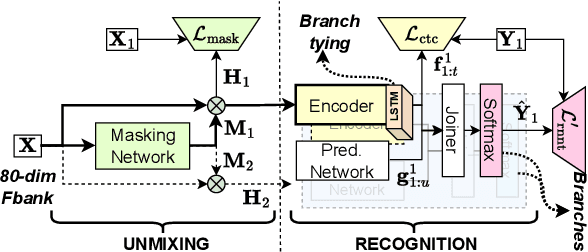
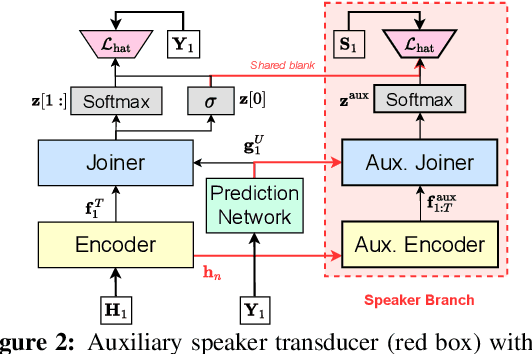

The Streaming Unmixing and Recognition Transducer (SURT) has recently become a popular framework for continuous, streaming, multi-talker speech recognition (ASR). With advances in architecture, objectives, and mixture simulation methods, it was demonstrated that SURT can be an efficient streaming method for speaker-agnostic transcription of real meetings. In this work, we push this framework further by proposing methods to perform speaker-attributed transcription with SURT, for both short mixtures and long recordings. We achieve this by adding an auxiliary speaker branch to SURT, and synchronizing its label prediction with ASR token prediction through HAT-style blank factorization. In order to ensure consistency in relative speaker labels across different utterance groups in a recording, we propose "speaker prefixing" -- appending each chunk with high-confidence frames of speakers identified in previous chunks, to establish the relative order. We perform extensive ablation experiments on synthetic LibriSpeech mixtures to validate our design choices, and demonstrate the efficacy of our final model on the AMI corpus.
DNN Speaker Tracking with Embeddings
Jul 13, 2020
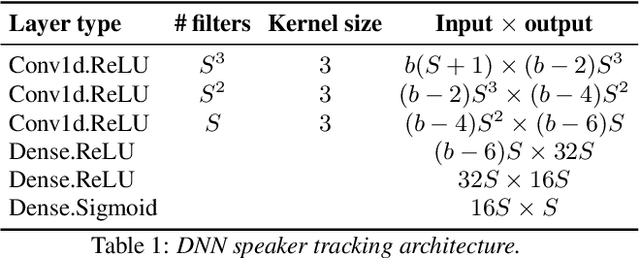

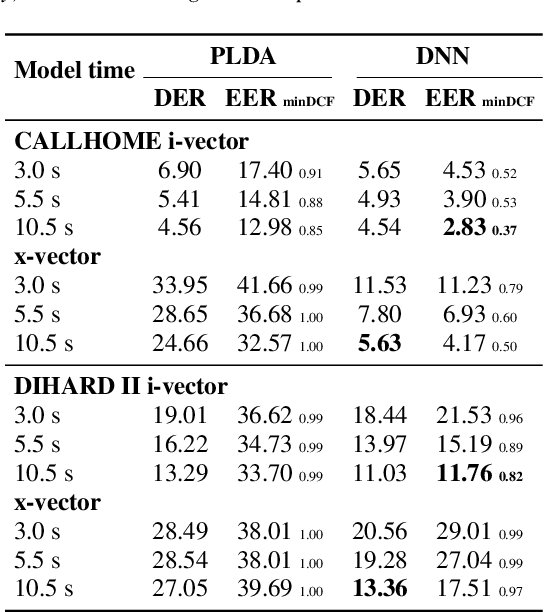
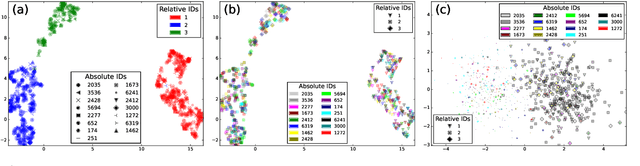
In multi-speaker applications is common to have pre-computed models from enrolled speakers. Using these models to identify the instances in which these speakers intervene in a recording is the task of speaker tracking. In this paper, we propose a novel embedding-based speaker tracking method. Specifically, our design is based on a convolutional neural network that mimics a typical speaker verification PLDA (probabilistic linear discriminant analysis) classifier and finds the regions uttered by the target speakers in an online fashion. The system was studied from two different perspectives: diarization and tracking; results on both show a significant improvement over the PLDA baseline under the same experimental conditions. Two standard public datasets, CALLHOME and DIHARD II single channel, were modified to create two-speaker subsets with overlapping and non-overlapping regions. We evaluate the robustness of our supervised approach with models generated from different segment lengths. A relative improvement of 17% in DER for DIHARD II single channel shows promising performance. Furthermore, to make the baseline system similar to speaker tracking, non-target speakers were added to the recordings. Even in these adverse conditions, our approach is robust enough to outperform the PLDA baseline.
Building Corpora for Single-Channel Speech Separation Across Multiple Domains
Nov 06, 2018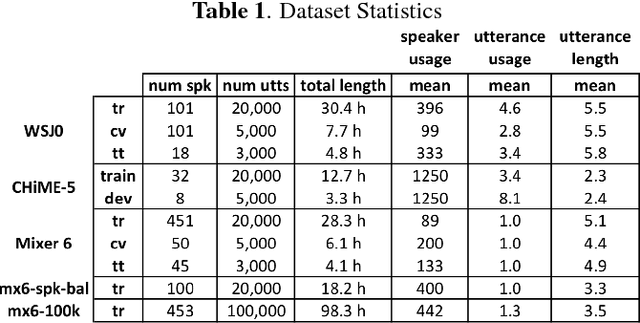
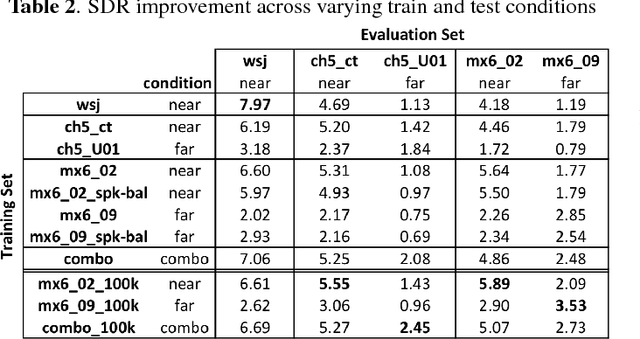
To date, the bulk of research on single-channel speech separation has been conducted using clean, near-field, read speech, which is not representative of many modern applications. In this work, we develop a procedure for constructing high-quality synthetic overlap datasets, necessary for most deep learning-based separation frameworks. We produced datasets that are more representative of realistic applications using the CHiME-5 and Mixer 6 corpora and evaluate standard methods on this data to demonstrate the shortcomings of current source-separation performance. We also demonstrate the value of a wide variety of data in training robust models that generalize well to multiple conditions.