 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Review on Generative Adversarial Networks for Data Augmentation in Person Re-Identification Systems
Feb 21, 2023Interest in automatic people re-identification systems has significantly grown in recent years, mainly for developing surveillance and smart shops software. Due to the variability in person posture, different lighting conditions, and occluded scenarios, together with the poor quality of the images obtained by different cameras, it is currently an unsolved problem. In machine learning-based computer vision applications with reduced data sets, one possibility to improve the performance of re-identification system is through the augmentation of the set of images or videos available for training the neural models. Currently, one of the most robust ways to generate synthetic information for data augmentation, whether it is video, images or text, are the generative adversarial networks. This article reviews the most relevant recent approaches to improve the performance of person re-identification models through data augmentation, using generative adversarial networks. We focus on three categories of data augmentation approaches: style transfer, pose transfer, and random generation.
Survey on reinforcement learning for language processing
Apr 12, 2021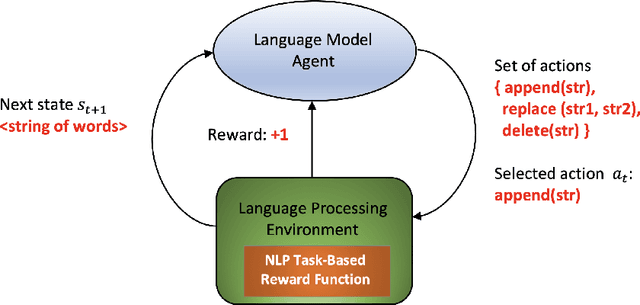

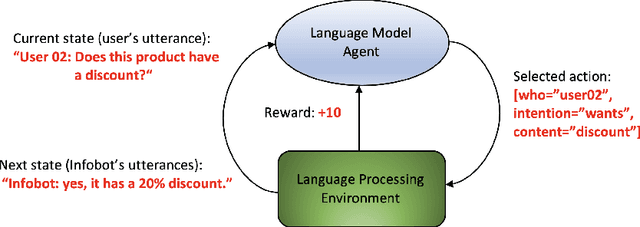
In recent years some researchers have explored the use of reinforcement learning (RL) algorithms as key components in the solution of various natural language processing tasks. For instance, some of these algorithms leveraging deep neural learning have found their way into conversational systems. This paper reviews the state of the art of RL methods for their possible use for different problems of natural language processing, focusing primarily on conversational systems, mainly due to their growing relevance. We provide detailed descriptions of the problems as well as discussions of why RL is well-suited to solve them. Also, we analyze the advantages and limitations of these methods. Finally, we elaborate on promising research directions in natural language processing that might benefit from reinforcement learning.
DNN Speaker Tracking with Embeddings
Jul 13, 2020
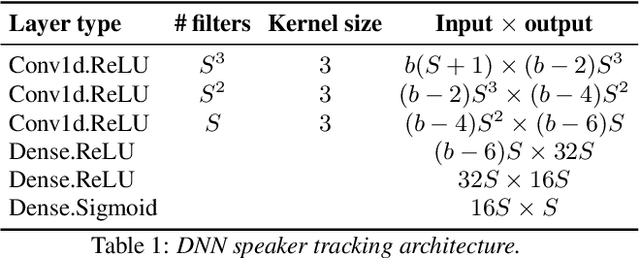

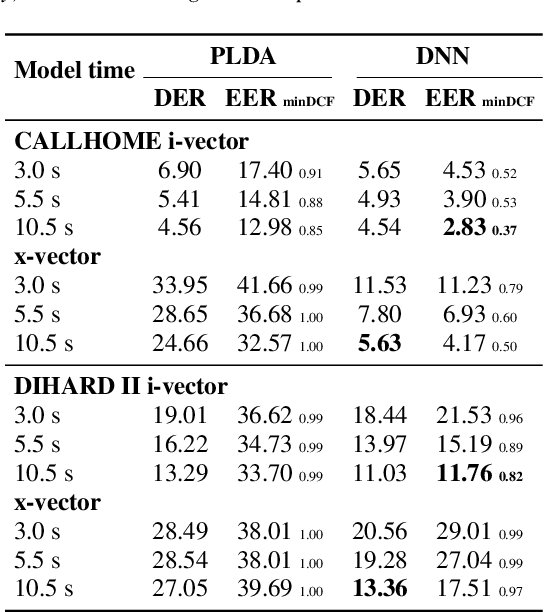
In multi-speaker applications is common to have pre-computed models from enrolled speakers. Using these models to identify the instances in which these speakers intervene in a recording is the task of speaker tracking. In this paper, we propose a novel embedding-based speaker tracking method. Specifically, our design is based on a convolutional neural network that mimics a typical speaker verification PLDA (probabilistic linear discriminant analysis) classifier and finds the regions uttered by the target speakers in an online fashion. The system was studied from two different perspectives: diarization and tracking; results on both show a significant improvement over the PLDA baseline under the same experimental conditions. Two standard public datasets, CALLHOME and DIHARD II single channel, were modified to create two-speaker subsets with overlapping and non-overlapping regions. We evaluate the robustness of our supervised approach with models generated from different segment lengths. A relative improvement of 17% in DER for DIHARD II single channel shows promising performance. Furthermore, to make the baseline system similar to speaker tracking, non-target speakers were added to the recordings. Even in these adverse conditions, our approach is robust enough to outperform the PLDA baseline.