 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDNN Speaker Tracking with Embeddings
Paper and Code

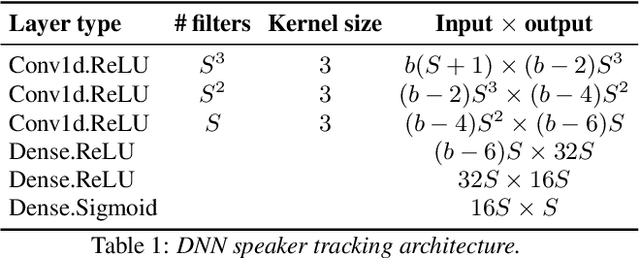

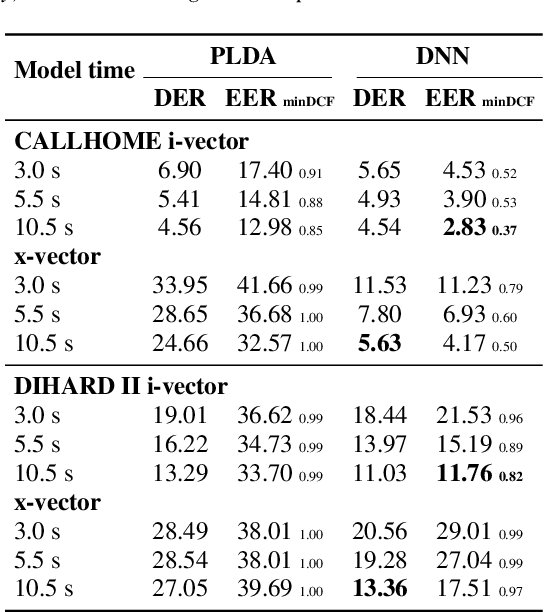
In multi-speaker applications is common to have pre-computed models from enrolled speakers. Using these models to identify the instances in which these speakers intervene in a recording is the task of speaker tracking. In this paper, we propose a novel embedding-based speaker tracking method. Specifically, our design is based on a convolutional neural network that mimics a typical speaker verification PLDA (probabilistic linear discriminant analysis) classifier and finds the regions uttered by the target speakers in an online fashion. The system was studied from two different perspectives: diarization and tracking; results on both show a significant improvement over the PLDA baseline under the same experimental conditions. Two standard public datasets, CALLHOME and DIHARD II single channel, were modified to create two-speaker subsets with overlapping and non-overlapping regions. We evaluate the robustness of our supervised approach with models generated from different segment lengths. A relative improvement of 17% in DER for DIHARD II single channel shows promising performance. Furthermore, to make the baseline system similar to speaker tracking, non-target speakers were added to the recordings. Even in these adverse conditions, our approach is robust enough to outperform the PLDA baseline.