 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAligning a medium-size GPT model in English to a small closed domain in Spanish using reinforcement learning
Apr 03, 2023In this paper, we propose a methodology to align a medium-sized GPT model, originally trained in English for an open domain, to a small closed domain in Spanish. The application for which the model is finely tuned is the question answering task. To achieve this we also needed to train and implement another neural network (which we called the reward model) that could score and determine whether an answer is appropriate for a given question. This component served to improve the decoding and generation of the answers of the system. Numerical metrics such as BLEU and perplexity were used to evaluate the model, and human judgment was also used to compare the decoding technique with others. Finally, the results favored the proposed method, and it was determined that it is feasible to use a reward model to align the generation of responses.
Recent Advances in Software Effort Estimation using Machine Learning
Mar 06, 2023An increasing number of software companies have already realized the importance of storing project-related data as valuable sources of information for training prediction models. Such kind of modeling opens the door for the implementation of tailored strategies to increase the accuracy in effort estimation of whole teams of engineers. In this article we review the most recent machine learning approaches used to estimate software development efforts for both, non-agile and agile methodologies. We analyze the benefits of adopting an agile methodology in terms of effort estimation possibilities, such as the modeling of programming patterns and misestimation patterns by individual engineers. We conclude with an analysis of current and future trends, regarding software effort estimation through data-driven predictive models.
A Review on Generative Adversarial Networks for Data Augmentation in Person Re-Identification Systems
Feb 21, 2023Interest in automatic people re-identification systems has significantly grown in recent years, mainly for developing surveillance and smart shops software. Due to the variability in person posture, different lighting conditions, and occluded scenarios, together with the poor quality of the images obtained by different cameras, it is currently an unsolved problem. In machine learning-based computer vision applications with reduced data sets, one possibility to improve the performance of re-identification system is through the augmentation of the set of images or videos available for training the neural models. Currently, one of the most robust ways to generate synthetic information for data augmentation, whether it is video, images or text, are the generative adversarial networks. This article reviews the most relevant recent approaches to improve the performance of person re-identification models through data augmentation, using generative adversarial networks. We focus on three categories of data augmentation approaches: style transfer, pose transfer, and random generation.
Robot path planning using deep reinforcement learning
Feb 17, 2023Autonomous navigation is challenging for mobile robots, especially in an unknown environment. Commonly, the robot requires multiple sensors to map the environment, locate itself, and make a plan to reach the target. However, reinforcement learning methods offer an alternative to map-free navigation tasks by learning the optimal actions to take. In this article, deep reinforcement learning agents are implemented using variants of the deep Q networks method, the D3QN and rainbow algorithms, for both the obstacle avoidance and the goal-oriented navigation task. The agents are trained and evaluated in a simulated environment. Furthermore, an analysis of the changes in the behaviour and performance of the agents caused by modifications in the reward function is conducted.
Survey on reinforcement learning for language processing
Apr 12, 2021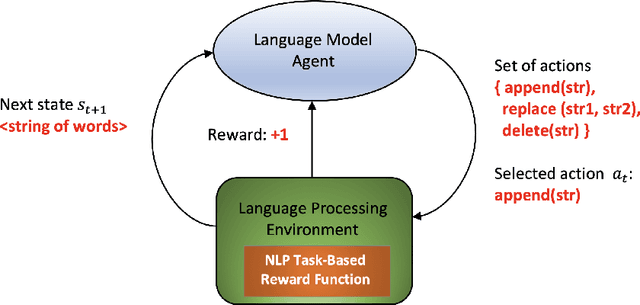

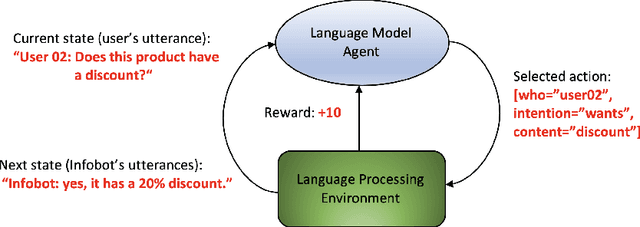
In recent years some researchers have explored the use of reinforcement learning (RL) algorithms as key components in the solution of various natural language processing tasks. For instance, some of these algorithms leveraging deep neural learning have found their way into conversational systems. This paper reviews the state of the art of RL methods for their possible use for different problems of natural language processing, focusing primarily on conversational systems, mainly due to their growing relevance. We provide detailed descriptions of the problems as well as discussions of why RL is well-suited to solve them. Also, we analyze the advantages and limitations of these methods. Finally, we elaborate on promising research directions in natural language processing that might benefit from reinforcement learning.