Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBuilding Corpora for Single-Channel Speech Separation Across Multiple Domains
Paper and Code
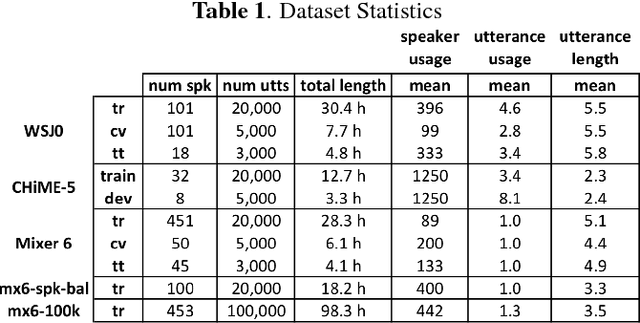
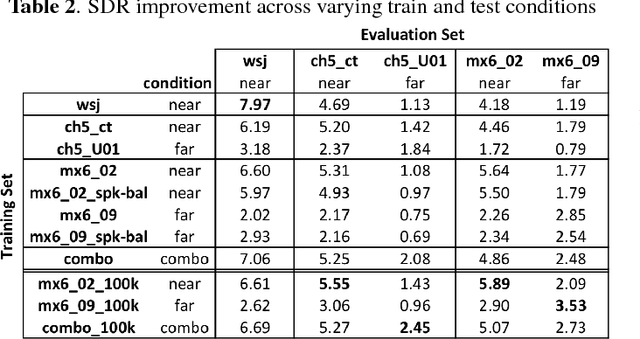
To date, the bulk of research on single-channel speech separation has been conducted using clean, near-field, read speech, which is not representative of many modern applications. In this work, we develop a procedure for constructing high-quality synthetic overlap datasets, necessary for most deep learning-based separation frameworks. We produced datasets that are more representative of realistic applications using the CHiME-5 and Mixer 6 corpora and evaluate standard methods on this data to demonstrate the shortcomings of current source-separation performance. We also demonstrate the value of a wide variety of data in training robust models that generalize well to multiple conditions.
* This work has been submitted to the IEEE for possible publication.
Copyright may be transferred without notice, after which this version may no
longer be accessible
View paper on