 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBayesian HMM clustering of x-vector sequences in speaker diarization: theory, implementation and analysis on standard tasks
Paper and Code

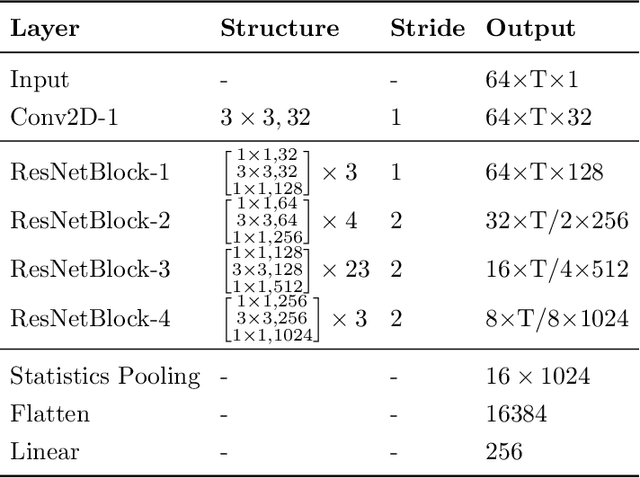

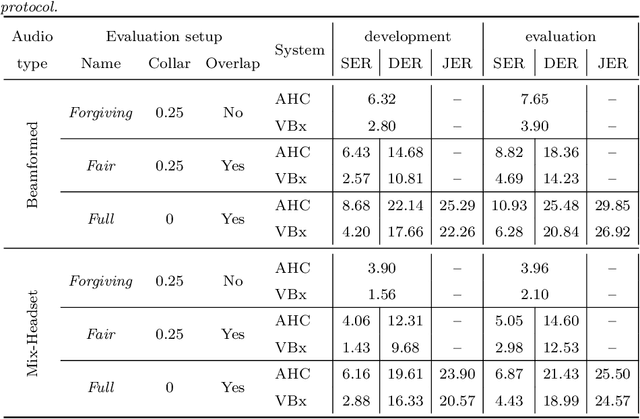
The recently proposed VBx diarization method uses a Bayesian hidden Markov model to find speaker clusters in a sequence of x-vectors. In this work we perform an extensive comparison of performance of the VBx diarization with other approaches in the literature and we show that VBx achieves superior performance on three of the most popular datasets for evaluating diarization: CALLHOME, AMI and DIHARDII datasets. Further, we present for the first time the derivation and update formulae for the VBx model, focusing on the efficiency and simplicity of this model as compared to the previous and more complex BHMM model working on frame-by-frame standard Cepstral features. Together with this publication, we release the recipe for training the x-vector extractors used in our experiments on both wide and narrowband data, and the VBx recipes that attain state-of-the-art performance on all three datasets. Besides, we point out the lack of a standardized evaluation protocol for AMI dataset and we propose a new protocol for both Beamformed and Mix-Headset audios based on the official AMI partitions and transcriptions.