 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEarnings-22: A Practical Benchmark for Accents in the Wild
Paper and Code

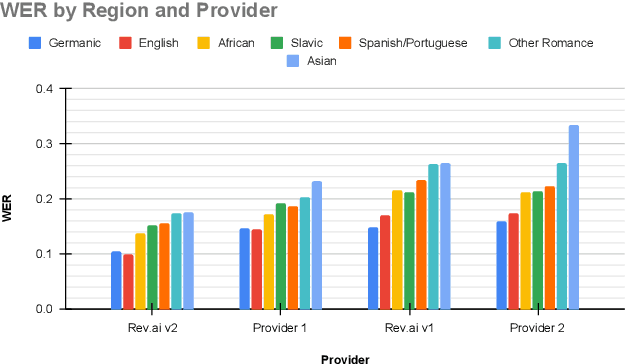
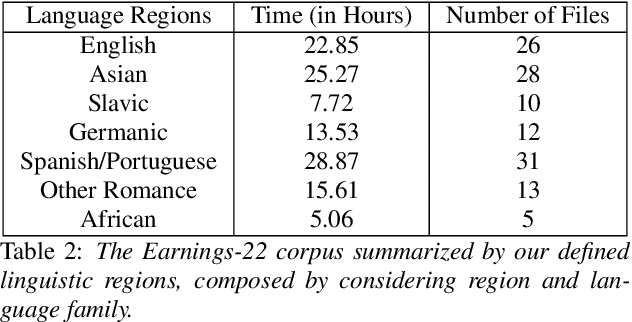

Modern automatic speech recognition (ASR) systems have achieved superhuman Word Error Rate (WER) on many common corpora despite lacking adequate performance on speech in the wild. Beyond that, there is a lack of real-world, accented corpora to properly benchmark academic and commercial models. To ensure this type of speech is represented in ASR benchmarking, we present Earnings-22, a 125 file, 119 hour corpus of English-language earnings calls gathered from global companies. We run a comparison across 4 commercial models showing the variation in performance when taking country of origin into consideration. Looking at hypothesis transcriptions, we explore errors common to all ASR systems tested. By examining Individual Word Error Rate (IWER), we find that key speech features impact model performance more for certain accents than others. Earnings-22 provides a free-to-use benchmark of real-world, accented audio to bridge academic and industrial research.