 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEVIMO2: An Event Camera Dataset for Motion Segmentation, Optical Flow, Structure from Motion, and Visual Inertial Odometry in Indoor Scenes with Monocular or Stereo Algorithms
Paper and Code

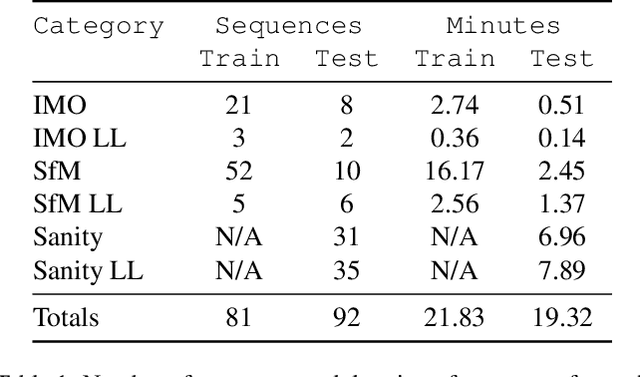


A new event camera dataset, EVIMO2, is introduced that improves on the popular EVIMO dataset by providing more data, from better cameras, in more complex scenarios. As with its predecessor, EVIMO2 provides labels in the form of per-pixel ground truth depth and segmentation as well as camera and object poses. All sequences use data from physical cameras and many sequences feature multiple independently moving objects. Typically, such labeled data is unavailable in physical event camera datasets. Thus, EVIMO2 will serve as a challenging benchmark for existing algorithms and rich training set for the development of new algorithms. In particular, EVIMO2 is suited for supporting research in motion and object segmentation, optical flow, structure from motion, and visual (inertial) odometry in both monocular or stereo configurations. EVIMO2 consists of 41 minutes of data from three 640$\times$480 event cameras, one 2080$\times$1552 classical color camera, inertial measurements from two six axis inertial measurement units, and millimeter accurate object poses from a Vicon motion capture system. The dataset's 173 sequences are arranged into three categories. 3.75 minutes of independently moving household objects, 22.55 minutes of static scenes, and 14.85 minutes of basic motions in shallow scenes. Some sequences were recorded in low-light conditions where conventional cameras fail. Depth and segmentation are provided at 60 Hz for the event cameras and 30 Hz for the classical camera. The masks can be regenerated using open-source code up to rates as high as 200 Hz. This technical report briefly describes EVIMO2. The full documentation is available online. Videos of individual sequences can be sampled on the download page.