 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSceneCalib: Automatic Targetless Calibration of Cameras and Lidars in Autonomous Driving
Apr 11, 2023



Accurate camera-to-lidar calibration is a requirement for sensor data fusion in many 3D perception tasks. In this paper, we present SceneCalib, a novel method for simultaneous self-calibration of extrinsic and intrinsic parameters in a system containing multiple cameras and a lidar sensor. Existing methods typically require specially designed calibration targets and human operators, or they only attempt to solve for a subset of calibration parameters. We resolve these issues with a fully automatic method that requires no explicit correspondences between camera images and lidar point clouds, allowing for robustness to many outdoor environments. Furthermore, the full system is jointly calibrated with explicit cross-camera constraints to ensure that camera-to-camera and camera-to-lidar extrinsic parameters are consistent.
Learning to Read through Machine Teaching
Jul 02, 2020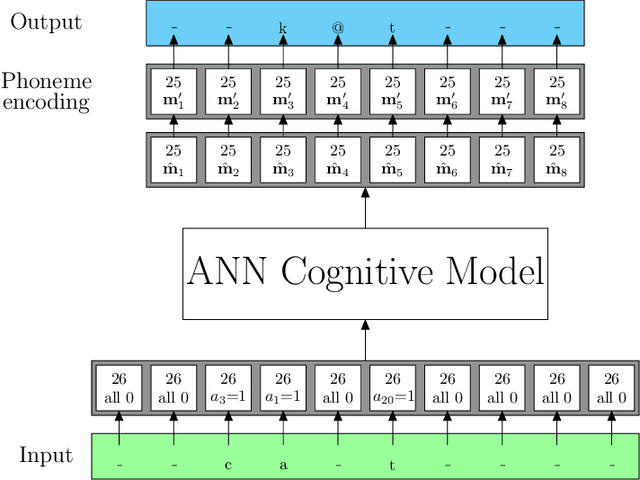

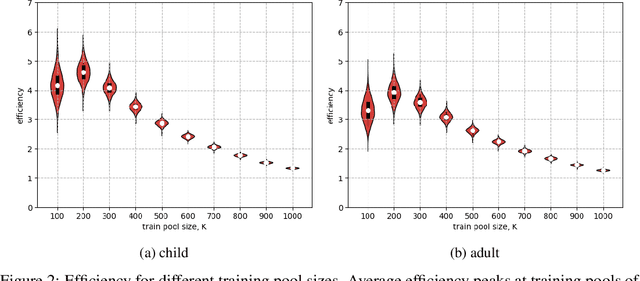
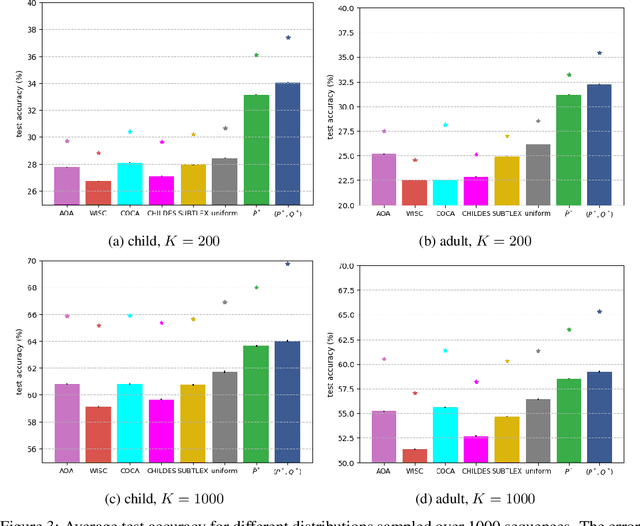
Learning to read words aloud is a major step towards becoming a reader. Many children struggle with the task because of the inconsistencies of English spelling-sound correspondences. Curricula vary enormously in how these patterns are taught. Children are nonetheless expected to master the system in limited time (by grade 4). We used a cognitively interesting neural network architecture to examine whether the sequence of learning trials could be structured to facilitate learning. This is a hard combinatorial optimization problem even for a modest number of learning trials (e.g., 10K). We show how this sequence optimization problem can be posed as optimizing over a time varying distribution i.e., defining probability distributions over words at different steps in training. We then use stochastic gradient descent to find an optimal time-varying distribution and a corresponding optimal training sequence. We observed significant improvement on generalization accuracy compared to baseline conditions (random sequences; sequences biased by word frequency). These findings suggest an approach to improving learning outcomes in domains where performance depends on ability to generalize beyond limited training experience.
Should Adversarial Attacks Use Pixel p-Norm?
Jun 06, 2019


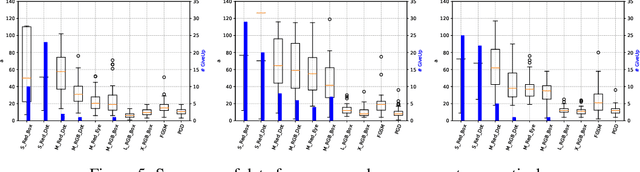
Adversarial attacks aim to confound machine learning systems, while remaining virtually imperceptible to humans. Attacks on image classification systems are typically gauged in terms of $p$-norm distortions in the pixel feature space. We perform a behavioral study, demonstrating that the pixel $p$-norm for any $0\le p \le \infty$, and several alternative measures including earth mover's distance, structural similarity index, and deep net embedding, do not fit human perception. Our result has the potential to improve the understanding of adversarial attack and defense strategies.