 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Scoping Review of Deep Learning for Urban Visual Pollution and Proposal of a Real-Time Monitoring Framework with a Visual Pollution Index
Feb 10, 2026Urban Visual Pollution (UVP) has emerged as a critical concern, yet research on automatic detection and application remains fragmented. This scoping review maps the existing deep learning-based approaches for detecting, classifying, and designing a comprehensive application framework for visual pollution management. Following the PRISMA-ScR guidelines, seven academic databases (Scopus, Web of Science, IEEE Xplore, ACM DL, ScienceDirect, SpringerNatureLink, and Wiley) were systematically searched and reviewed, and 26 articles were found. Most research focuses on specific pollutant categories and employs variations of YOLO, Faster R-CNN, and EfficientDet architectures. Although several datasets exist, they are limited to specific areas and lack standardized taxonomies. Few studies integrate detection into real-time application systems, yet they tend to be geographically skewed. We proposed a framework for monitoring visual pollution that integrates a visual pollution index to assess the severity of visual pollution for a certain area. This review highlights the need for a unified UVP management system that incorporates pollutant taxonomy, a cross-city benchmark dataset, a generalized deep learning model, and an assessment index that supports sustainable urban aesthetics and enhances the well-being of urban dwellers.
Improved Bug Localization with AI Agents Leveraging Hypothesis and Dynamic Cognition
Jan 18, 2026Software bugs cost technology providers (e.g., AT&T) billions annually and cause developers to spend roughly 50% of their time on bug resolution. Traditional methods for bug localization often analyze the suspiciousness of code components (e.g., methods, documents) in isolation, overlooking their connections with other components in the codebase. Recent advances in Large Language Models (LLMs) and agentic AI techniques have shown strong potential for code understanding, but still lack causal reasoning during code exploration and struggle to manage growing context effectively, limiting their capability. In this paper, we present a novel agentic technique for bug localization -- CogniGent -- that overcomes the limitations above by leveraging multiple AI agents capable of causal reasoning, call-graph-based root cause analysis and context engineering. It emulates developers-inspired debugging practices (a.k.a., dynamic cognitive debugging) and conducts hypothesis testing to support bug localization. We evaluate CogniGent on a curated dataset of 591 bug reports using three widely adopted performance metrics and compare it against six established baselines from the literature. Experimental results show that our technique consistently outperformed existing traditional and LLM-based techniques, achieving MAP improvements of 23.33-38.57% at the document and method levels. Similar gains were observed in MRR, with increases of 25.14-53.74% at both granularity levels. Statistical significance tests also confirm the superiority of our technique. By addressing the reasoning, dependency, and context limitations, CogniGent advances the state of bug localization, bridging human-like cognition with agentic automation for improved performance.
Imitation Game: Reproducing Deep Learning Bugs Leveraging an Intelligent Agent
Dec 17, 2025Despite their wide adoption in various domains (e.g., healthcare, finance, software engineering), Deep Learning (DL)-based applications suffer from many bugs, failures, and vulnerabilities. Reproducing these bugs is essential for their resolution, but it is extremely challenging due to the inherent nondeterminism of DL models and their tight coupling with hardware and software environments. According to recent studies, only about 3% of DL bugs can be reliably reproduced using manual approaches. To address these challenges, we present RepGen, a novel, automated, and intelligent approach for reproducing deep learning bugs. RepGen constructs a learning-enhanced context from a project, develops a comprehensive plan for bug reproduction, employs an iterative generate-validate-refine mechanism, and thus generates such code using an LLM that reproduces the bug at hand. We evaluate RepGen on 106 real-world deep learning bugs and achieve a reproduction rate of 80.19%, a 19.81% improvement over the state-of-the-art measure. A developer study involving 27 participants shows that RepGen improves the success rate of DL bug reproduction by 23.35%, reduces the time to reproduce by 56.8%, and lowers participants' cognitive load.
Taxonomy of Faults in Attention-Based Neural Networks
Aug 06, 2025Attention mechanisms are at the core of modern neural architectures, powering systems ranging from ChatGPT to autonomous vehicles and driving a major economic impact. However, high-profile failures, such as ChatGPT's nonsensical outputs or Google's suspension of Gemini's image generation due to attention weight errors, highlight a critical gap: existing deep learning fault taxonomies might not adequately capture the unique failures introduced by attention mechanisms. This gap leaves practitioners without actionable diagnostic guidance. To address this gap, we present the first comprehensive empirical study of faults in attention-based neural networks (ABNNs). Our work is based on a systematic analysis of 555 real-world faults collected from 96 projects across ten frameworks, including GitHub, Hugging Face, and Stack Overflow. Through our analysis, we develop a novel taxonomy comprising seven attention-specific fault categories, not captured by existing work. Our results show that over half of the ABNN faults arise from mechanisms unique to attention architectures. We further analyze the root causes and manifestations of these faults through various symptoms. Finally, by analyzing symptom-root cause associations, we identify four evidence-based diagnostic heuristics that explain 33.0% of attention-specific faults, offering the first systematic diagnostic guidance for attention-based models.
Can Hessian-Based Insights Support Fault Diagnosis in Attention-based Models?
Jun 09, 2025As attention-based deep learning models scale in size and complexity, diagnosing their faults becomes increasingly challenging. In this work, we conduct an empirical study to evaluate the potential of Hessian-based analysis for diagnosing faults in attention-based models. Specifically, we use Hessian-derived insights to identify fragile regions (via curvature analysis) and parameter interdependencies (via parameter interaction analysis) within attention mechanisms. Through experiments on three diverse models (HAN, 3D-CNN, DistilBERT), we show that Hessian-based metrics can localize instability and pinpoint fault sources more effectively than gradients alone. Our empirical findings suggest that these metrics could significantly improve fault diagnosis in complex neural architectures, potentially improving software debugging practices.
Improved IR-based Bug Localization with Intelligent Relevance Feedback
Jan 17, 2025Software bugs pose a significant challenge during development and maintenance, and practitioners spend nearly 50% of their time dealing with bugs. Many existing techniques adopt Information Retrieval (IR) to localize a reported bug using textual and semantic relevance between bug reports and source code. However, they often struggle to bridge a critical gap between bug reports and code that requires in-depth contextual understanding, which goes beyond textual or semantic relevance. In this paper, we present a novel technique for bug localization - BRaIn - that addresses the contextual gaps by assessing the relevance between bug reports and code with Large Language Models (LLM). It then leverages the LLM's feedback (a.k.a., Intelligent Relevance Feedback) to reformulate queries and re-rank source documents, improving bug localization. We evaluate BRaIn using a benchmark dataset, Bench4BL, and three performance metrics and compare it against six baseline techniques from the literature. Our experimental results show that BRaIn outperforms baselines by 87.6%, 89.5%, and 48.8% margins in MAP, MRR, and HIT@K, respectively. Additionally, it can localize approximately 52% of bugs that cannot be localized by the baseline techniques due to the poor quality of corresponding bug reports. By addressing the contextual gaps and introducing Intelligent Relevance Feedback, BRaIn advances not only theory but also improves IR-based bug localization.
Towards Enhancing the Reproducibility of Deep Learning Bugs: An Empirical Study
Jan 05, 2024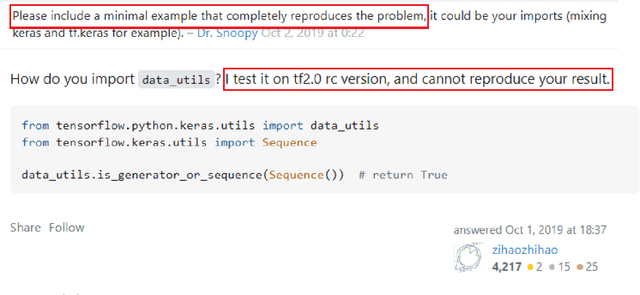
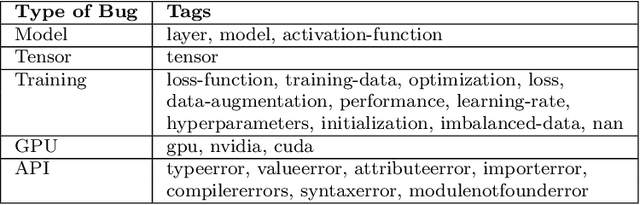
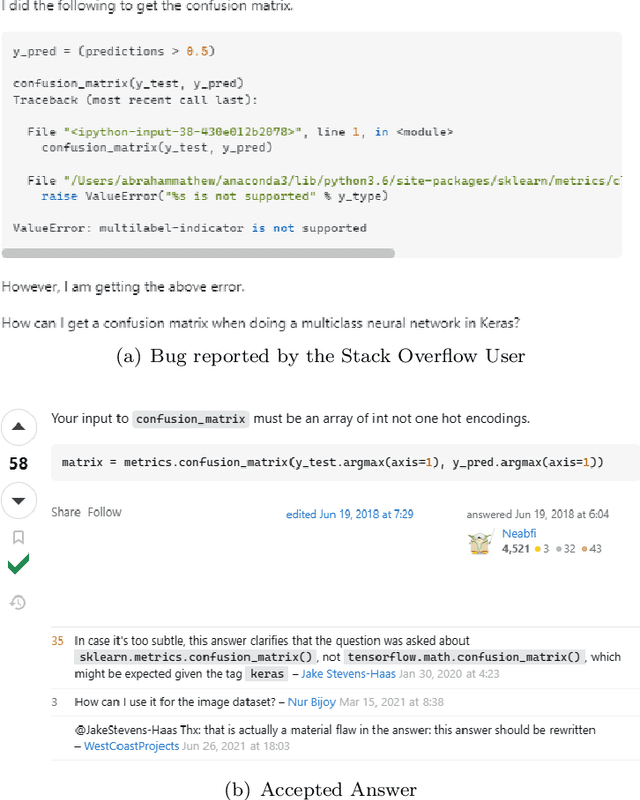
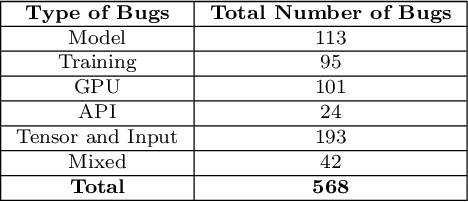
Context: Deep learning has achieved remarkable progress in various domains. However, like traditional software systems, deep learning systems contain bugs, which can have severe impacts, as evidenced by crashes involving autonomous vehicles. Despite substantial advancements in deep learning techniques, little research has focused on reproducing deep learning bugs, which hinders resolving them. Existing literature suggests that only 3% of deep learning bugs are reproducible, underscoring the need for further research. Objective: This paper examines the reproducibility of deep learning bugs. We identify edit actions and useful information that could improve deep learning bug reproducibility. Method: First, we construct a dataset of 668 deep learning bugs from Stack Overflow and Defects4ML across 3 frameworks and 22 architectures. Second, we select 102 bugs using stratified sampling and try to determine their reproducibility. While reproducing these bugs, we identify edit actions and useful information necessary for their reproduction. Third, we used the Apriori algorithm to identify useful information and edit actions required to reproduce specific bug types. Finally, we conduct a user study with 22 developers to assess the effectiveness of our findings in real-life settings. Results: We successfully reproduced 85 bugs and identified ten edit actions and five useful information categories that can help us reproduce deep learning bugs. Our findings improved bug reproducibility by 22.92% and reduced reproduction time by 24.35% based on our user study. Conclusions: Our research addresses the critical issue of deep learning bug reproducibility. Practitioners and researchers can leverage our findings to improve deep learning bug reproducibility.
Predicting Line-Level Defects by Capturing Code Contexts with Hierarchical Transformers
Dec 19, 2023
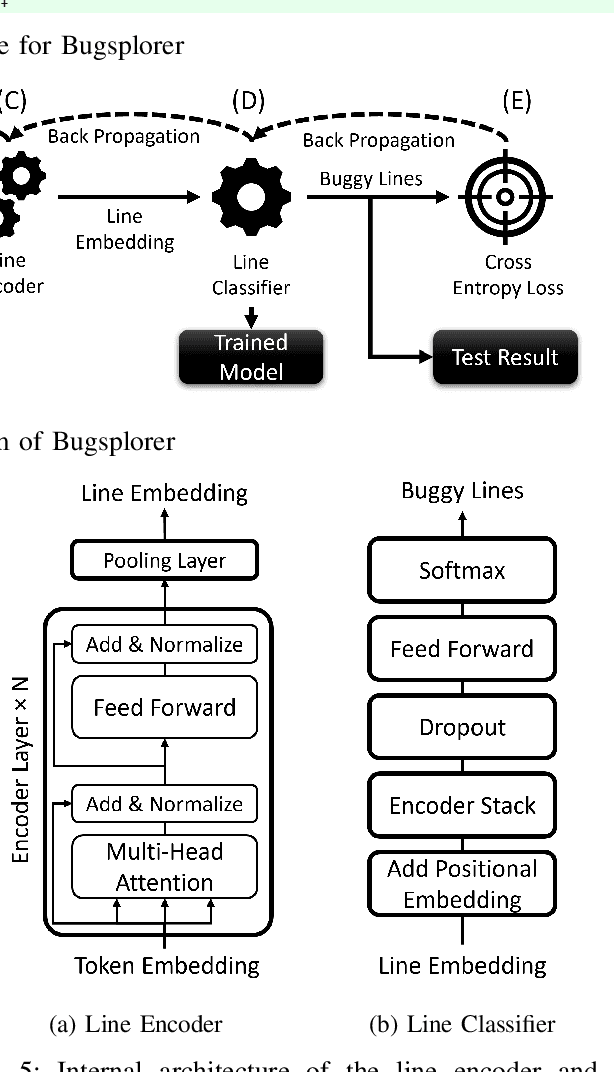

Software defects consume 40% of the total budget in software development and cost the global economy billions of dollars every year. Unfortunately, despite the use of many software quality assurance (SQA) practices in software development (e.g., code review, continuous integration), defects may still exist in the official release of a software product. Therefore, prioritizing SQA efforts for the vulnerable areas of the codebase is essential to ensure the high quality of a software release. Predicting software defects at the line level could help prioritize the SQA effort but is a highly challenging task given that only ~3% of lines of a codebase could be defective. Existing works on line-level defect prediction often fall short and cannot fully leverage the line-level defect information. In this paper, we propose Bugsplorer, a novel deep-learning technique for line-level defect prediction. It leverages a hierarchical structure of transformer models to represent two types of code elements: code tokens and code lines. Unlike the existing techniques that are optimized for file-level defect prediction, Bugsplorer is optimized for a line-level defect prediction objective. Our evaluation with five performance metrics shows that Bugsplorer has a promising capability of predicting defective lines with 26-72% better accuracy than that of the state-of-the-art technique. It can rank the first 20% defective lines within the top 1-3% suspicious lines. Thus, Bugsplorer has the potential to significantly reduce SQA costs by ranking defective lines higher.
A Systematic Literature Review of Automated Query Reformulations in Source Code Search
Aug 22, 2021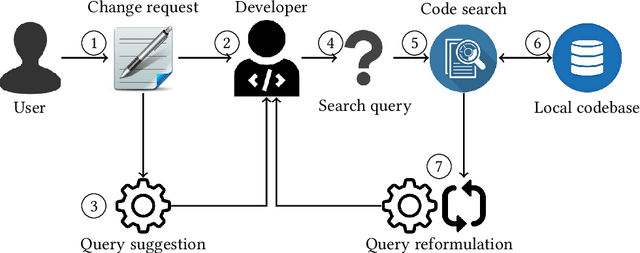
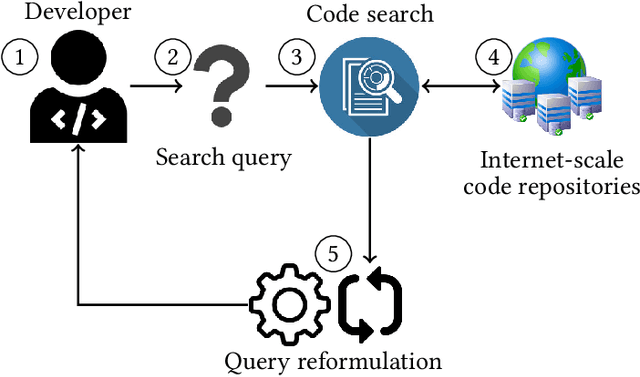

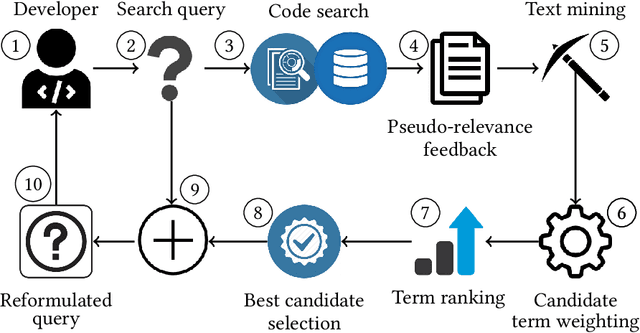
Software developers often fix critical bugs to ensure the reliability of their software. They might also need to add new features to their software at a regular interval to stay competitive in the market. These bugs and features are reported as change requests (i.e., technical documents written by software users). Developers consult these documents to implement the required changes in the software code. As a part of change implementation, they often choose a few important keywords from a change request as an ad hoc query. Then they execute the query with a code search engine (e.g., Lucene) and attempt to find out the exact locations within the software code that need to be changed. Unfortunately, even experienced developers often fail to choose the right queries. As a consequence, the developers often experience difficulties in detecting the appropriate locations within the code and spend the majority of their time in numerous trials and errors. There have been many studies that attempt to support developers in constructing queries by automatically reformulating their ad hoc queries. In this systematic literature review, we carefully select 70 primary studies on query reformulations from 2,970 candidate studies, perform an in-depth qualitative analysis using the Grounded Theory approach, and then answer six important research questions. Our investigation has reported several major findings. First, to date, eight major methodologies (e.g., term weighting, query-term co-occurrence analysis, thesaurus lookup) have been adopted in query reformulation. Second, the existing studies suffer from several major limitations (e.g., lack of generalizability, vocabulary mismatch problem, weak evaluation, the extra burden on the developers) that might prevent their wide adoption. Finally, we discuss several open issues in search query reformulations and suggest multiple future research opportunities.
Generating Cyber Threat Intelligence to Discover Potential Security Threats Using Classification and Topic Modeling
Aug 19, 2021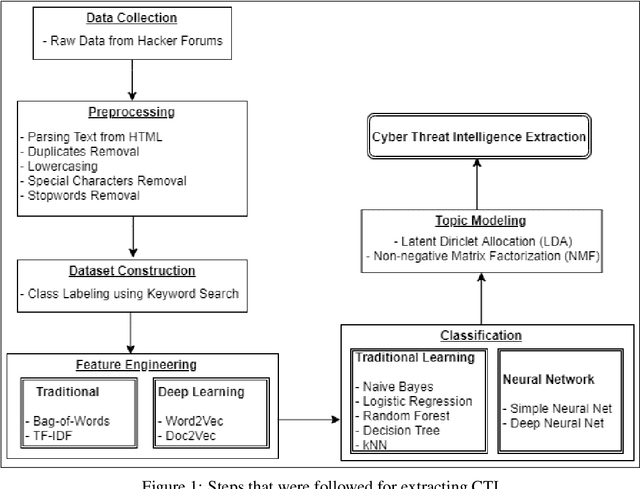

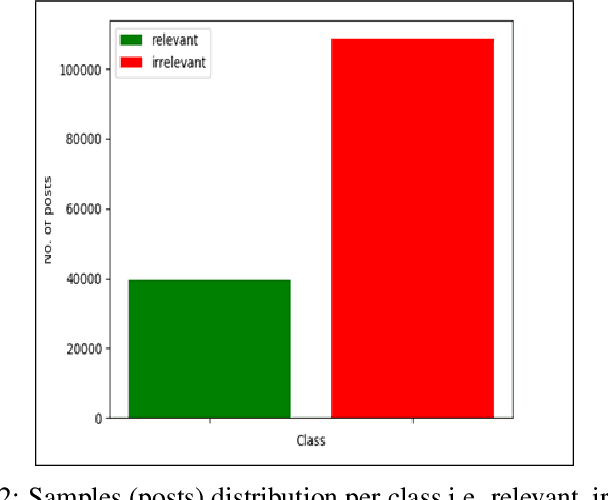

Due to the variety of cyber-attacks or threats, the cybersecurity community enhances the traditional security control mechanisms to an advanced level so that automated tools can encounter potential security threats. Very recently, Cyber Threat Intelligence (CTI) has been presented as one of the proactive and robust mechanisms because of its automated cybersecurity threat prediction. Generally, CTI collects and analyses data from various sources e.g., online security forums, social media where cyber enthusiasts, analysts, even cybercriminals discuss cyber or computer security-related topics and discovers potential threats based on the analysis. As the manual analysis of every such discussion (posts on online platforms) is time-consuming, inefficient, and susceptible to errors, CTI as an automated tool can perform uniquely to detect cyber threats. In this paper, we identify and explore relevant CTI from hacker forums utilizing different supervised (classification) and unsupervised learning (topic modeling) techniques. To this end, we collect data from a real hacker forum and constructed two datasets: a binary dataset and a multi-class dataset. We then apply several classifiers along with deep neural network-based classifiers and use them on the datasets to compare their performances. We also employ the classifiers on a labeled leaked dataset as our ground truth. We further explore the datasets using unsupervised techniques. For this purpose, we leverage two topic modeling algorithms namely Latent Dirichlet Allocation (LDA) and Non-negative Matrix Factorization (NMF).