 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Forgotten Role of Search Queries in IR-based Bug Localization: An Empirical Study
Aug 11, 2021
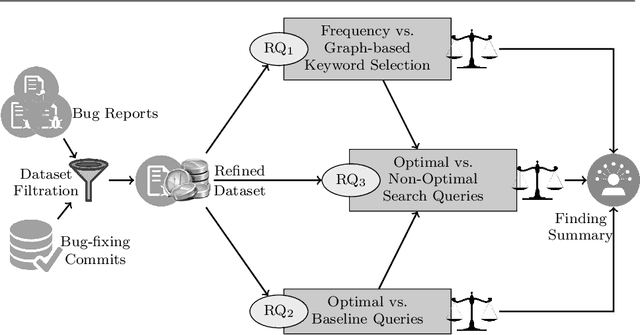
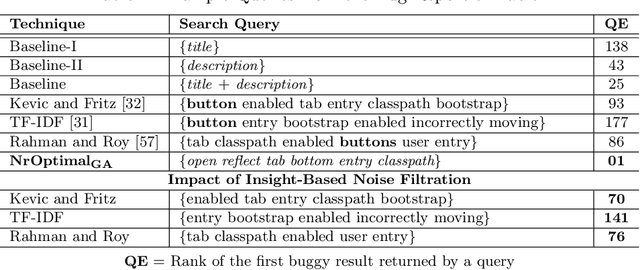
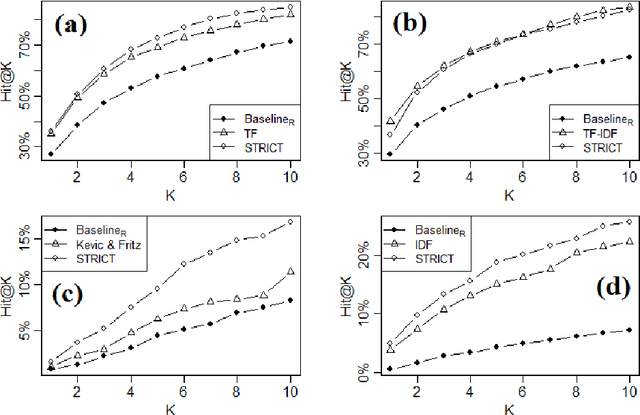
Being light-weight and cost-effective, IR-based approaches for bug localization have shown promise in finding software bugs. However, the accuracy of these approaches heavily depends on their used bug reports. A significant number of bug reports contain only plain natural language texts. According to existing studies, IR-based approaches cannot perform well when they use these bug reports as search queries. On the other hand, there is a piece of recent evidence that suggests that even these natural language-only reports contain enough good keywords that could help localize the bugs successfully. On one hand, these findings suggest that natural language-only bug reports might be a sufficient source for good query keywords. On the other hand, they cast serious doubt on the query selection practices in the IR-based bug localization. In this article, we attempted to clear the sky on this aspect by conducting an in-depth empirical study that critically examines the state-of-the-art query selection practices in IR-based bug localization. In particular, we use a dataset of 2,320 bug reports, employ ten existing approaches from the literature, exploit the Genetic Algorithm-based approach to construct optimal, near-optimal search queries from these bug reports, and then answer three research questions. We confirmed that the state-of-the-art query construction approaches are indeed not sufficient for constructing appropriate queries (for bug localization) from certain natural language-only bug reports although they contain such queries. We also demonstrate that optimal queries and non-optimal queries chosen from bug report texts are significantly different in terms of several keyword characteristics, which has led us to actionable insights. Furthermore, we demonstrate 27%--34% improvement in the performance of non-optimal queries through the application of our actionable insights to them.
* 57 pages