 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContext-aware Video Anomaly Detection in Long-Term Datasets
Apr 11, 2024



Video anomaly detection research is generally evaluated on short, isolated benchmark videos only a few minutes long. However, in real-world environments, security cameras observe the same scene for months or years at a time, and the notion of anomalous behavior critically depends on context, such as the time of day, day of week, or schedule of events. Here, we propose a context-aware video anomaly detection algorithm, Trinity, specifically targeted to these scenarios. Trinity is especially well-suited to crowded scenes in which individuals cannot be easily tracked, and anomalies are due to speed, direction, or absence of group motion. Trinity is a contrastive learning framework that aims to learn alignments between context, appearance, and motion, and uses alignment quality to classify videos as normal or anomalous. We evaluate our algorithm on both conventional benchmarks and a public webcam-based dataset we collected that spans more than three months of activity.
A Broad Study on the Transferability of Visual Representations with Contrastive Learning
Apr 01, 2021
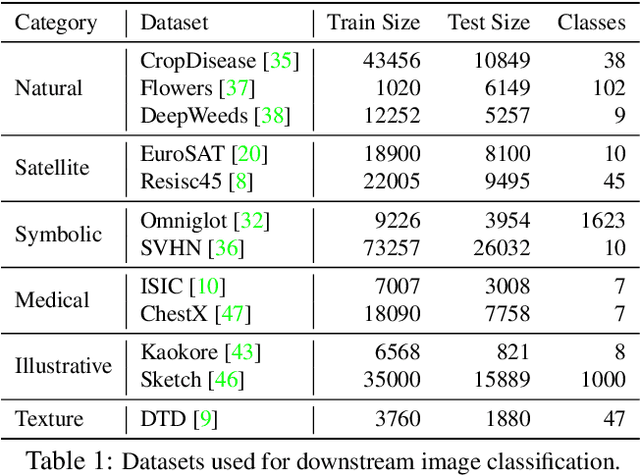

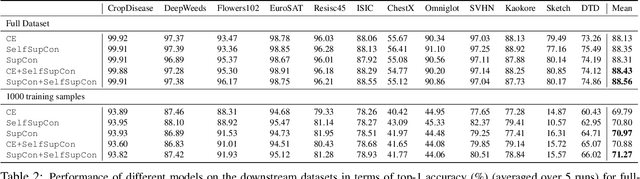
Tremendous progress has been made in visual representation learning, notably with the recent success of self-supervised contrastive learning methods. Supervised contrastive learning has also been shown to outperform its cross-entropy counterparts by leveraging labels for choosing where to contrast. However, there has been little work to explore the transfer capability of contrastive learning to a different domain. In this paper, we conduct a comprehensive study on the transferability of learned representations of different contrastive approaches for linear evaluation, full-network transfer, and few-shot recognition on 12 downstream datasets from different domains, and object detection tasks on MSCOCO and VOC0712. The results show that the contrastive approaches learn representations that are easily transferable to a different downstream task. We further observe that the joint objective of self-supervised contrastive loss with cross-entropy/supervised-contrastive loss leads to better transferability of these models over their supervised counterparts. Our analysis reveals that the representations learned from the contrastive approaches contain more low/mid-level semantics than cross-entropy models, which enables them to quickly adapt to a new task. Our codes and models will be publicly available to facilitate future research on transferability of visual representations.