 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMany Dialects, Many Languages, One Cultural Lens: Evaluating Multilingual VLMs for Bengali Culture Understanding Across Historically Linked Languages and Regional Dialects
Mar 22, 2026Bangla culture is richly expressed through region, dialect, history, food, politics, media, and everyday visual life, yet it remains underrepresented in multimodal evaluation. To address this gap, we introduce BanglaVerse, a culturally grounded benchmark for evaluating multilingual vision-language models (VLMs) on Bengali culture across historically linked languages and regional dialects. Built from 1,152 manually curated images across nine domains, the benchmark supports visual question answering and captioning, and is expanded into four languages and five Bangla dialects, yielding ~32.3K artifacts. Our experiments show that evaluating only standard Bangla overestimates true model capability: performance drops under dialectal variation, especially for caption generation, while historically linked languages such as Hindi and Urdu retain some cultural meaning but remain weaker for structured reasoning. Across domains, the main bottleneck is missing cultural knowledge rather than visual grounding alone, with knowledge-intensive categories. These findings position BanglaVerse as a more realistic test bed for measuring culturally grounded multimodal understanding under linguistic variation.
Route, Retrieve, Reflect, Repair: Self-Improving Agentic Framework for Visual Detection and Linguistic Reasoning in Medical Imaging
Jan 13, 2026Medical image analysis increasingly relies on large vision-language models (VLMs), yet most systems remain single-pass black boxes that offer limited control over reasoning, safety, and spatial grounding. We propose R^4, an agentic framework that decomposes medical imaging workflows into four coordinated agents: a Router that configures task- and specialization-aware prompts from the image, patient history, and metadata; a Retriever that uses exemplar memory and pass@k sampling to jointly generate free-text reports and bounding boxes; a Reflector that critiques each draft-box pair for key clinical error modes (negation, laterality, unsupported claims, contradictions, missing findings, and localization errors); and a Repairer that iteratively revises both narrative and spatial outputs under targeted constraints while curating high-quality exemplars for future cases. Instantiated on chest X-ray analysis with multiple modern VLM backbones and evaluated on report generation and weakly supervised detection, R^4 consistently boosts LLM-as-a-Judge scores by roughly +1.7-+2.5 points and mAP50 by +2.5-+3.5 absolute points over strong single-VLM baselines, without any gradient-based fine-tuning. These results show that agentic routing, reflection, and repair can turn strong but brittle VLMs into more reliable and better grounded tools for clinical image interpretation. Our code can be found at: https://github.com/faiyazabdullah/MultimodalMedAgent
Can LLMs Solve My Grandma's Riddle? Evaluating Multilingual Large Language Models on Reasoning Traditional Bangla Tricky Riddles
Dec 23, 2025Large Language Models (LLMs) show impressive performance on many NLP benchmarks, yet their ability to reason in figurative, culturally grounded, and low-resource settings remains underexplored. We address this gap for Bangla by introducing BanglaRiddleEval, a benchmark of 1,244 traditional Bangla riddles instantiated across four tasks (4,976 riddle-task artifacts in total). Using an LLM-based pipeline, we generate Chain-of-Thought explanations, semantically coherent distractors, and fine-grained ambiguity annotations, and evaluate a diverse suite of open-source and closed-source models under different prompting strategies. Models achieve moderate semantic overlap on generative QA but low correctness, MCQ accuracy peaks at only about 56% versus an 83% human baseline, and ambiguity resolution ranges from roughly 26% to 68%, with high-quality explanations confined to the strongest models. These results show that current LLMs capture some cues needed for Bangla riddle reasoning but remain far from human-level performance, establishing BanglaRiddleEval as a challenging new benchmark for low-resource figurative reasoning. All data, code, and evaluation scripts are available on GitHub: https://github.com/Labib1610/BanglaRiddleEval.
Do Multi-Agents Solve Better Than Single? Evaluating Agentic Frameworks for Diagram-Grounded Geometry Problem Solving and Reasoning
Dec 18, 2025Diagram-grounded geometry problem solving is a critical benchmark for multimodal large language models (MLLMs), yet the benefits of multi-agent design over single-agent remain unclear. We systematically compare single-agent and multi-agent pipelines on four visual math benchmarks: Geometry3K, MathVerse, OlympiadBench, and We-Math. For open-source models, multi-agent consistently improves performance. For example, Qwen-2.5-VL (7B) gains +6.8 points and Qwen-2.5-VL (32B) gains +3.3 on Geometry3K, and both Qwen-2.5-VL variants see further gains on OlympiadBench and We-Math. In contrast, the closed-source Gemini-2.0-Flash generally performs better in single-agent mode on classic benchmarks, while multi-agent yields only modest improvements on the newer We-Math dataset. These findings show that multi-agent pipelines provide clear benefits for open-source models and can assist strong proprietary systems on newer, less familiar benchmarks, but agentic decomposition is not universally optimal. All code, data, and reasoning files are available at https://github.com/faiyazabdullah/Interpreter-Solver
MathMist: A Parallel Multilingual Benchmark Dataset for Mathematical Problem Solving and Reasoning
Oct 16, 2025Mathematical reasoning remains one of the most challenging domains for large language models (LLMs), requiring not only linguistic understanding but also structured logical deduction and numerical precision. While recent LLMs demonstrate strong general-purpose reasoning abilities, their mathematical competence across diverse languages remains underexplored. Existing benchmarks primarily focus on English or a narrow subset of high-resource languages, leaving significant gaps in assessing multilingual and cross-lingual mathematical reasoning. To address this, we introduce MathMist, a parallel multilingual benchmark for mathematical problem solving and reasoning. MathMist encompasses over 21K aligned question-answer pairs across seven languages, representing a balanced coverage of high-, medium-, and low-resource linguistic settings. The dataset captures linguistic variety, multiple types of problem settings, and solution synthesizing capabilities. We systematically evaluate a diverse suite of models, including open-source small and medium LLMs, proprietary systems, and multilingual-reasoning-focused models, under zero-shot, chain-of-thought (CoT), and code-switched reasoning paradigms. Our results reveal persistent deficiencies in LLMs' ability to perform consistent and interpretable mathematical reasoning across languages, with pronounced degradation in low-resource settings. All the codes and data are available at GitHub: https://github.com/mahbubhimel/MathMist
Ready to Translate, Not to Represent? Bias and Performance Gaps in Multilingual LLMs Across Language Families and Domains
Oct 09, 2025The rise of Large Language Models (LLMs) has redefined Machine Translation (MT), enabling context-aware and fluent translations across hundreds of languages and textual domains. Despite their remarkable capabilities, LLMs often exhibit uneven performance across language families and specialized domains. Moreover, recent evidence reveals that these models can encode and amplify different biases present in their training data, posing serious concerns for fairness, especially in low-resource languages. To address these gaps, we introduce Translation Tangles, a unified framework and dataset for evaluating the translation quality and fairness of open-source LLMs. Our approach benchmarks 24 bidirectional language pairs across multiple domains using different metrics. We further propose a hybrid bias detection pipeline that integrates rule-based heuristics, semantic similarity filtering, and LLM-based validation. We also introduce a high-quality, bias-annotated dataset based on human evaluations of 1,439 translation-reference pairs. The code and dataset are accessible on GitHub: https://github.com/faiyazabdullah/TranslationTangles
VisText-Mosquito: A Multimodal Dataset and Benchmark for AI-Based Mosquito Breeding Site Detection and Reasoning
Jun 17, 2025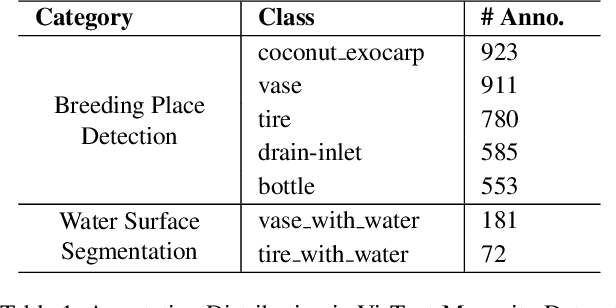

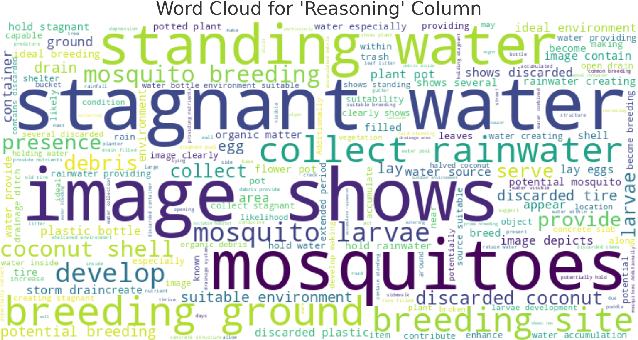
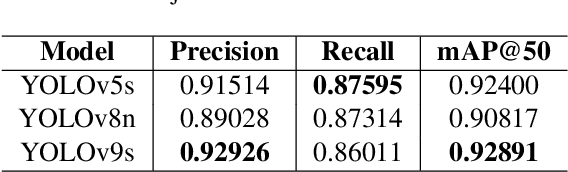
Mosquito-borne diseases pose a major global health risk, requiring early detection and proactive control of breeding sites to prevent outbreaks. In this paper, we present VisText-Mosquito, a multimodal dataset that integrates visual and textual data to support automated detection, segmentation, and reasoning for mosquito breeding site analysis. The dataset includes 1,828 annotated images for object detection, 142 images for water surface segmentation, and natural language reasoning texts linked to each image. The YOLOv9s model achieves the highest precision of 0.92926 and mAP@50 of 0.92891 for object detection, while YOLOv11n-Seg reaches a segmentation precision of 0.91587 and mAP@50 of 0.79795. For reasoning generation, our fine-tuned BLIP model achieves a final loss of 0.0028, with a BLEU score of 54.7, BERTScore of 0.91, and ROUGE-L of 0.87. This dataset and model framework emphasize the theme "Prevention is Better than Cure", showcasing how AI-based detection can proactively address mosquito-borne disease risks. The dataset and implementation code are publicly available at GitHub: https://github.com/adnanul-islam-jisun/VisText-Mosquito
MIMIC: Multimodal Islamophobic Meme Identification and Classification
Dec 01, 2024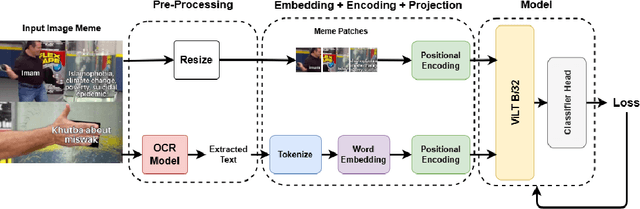

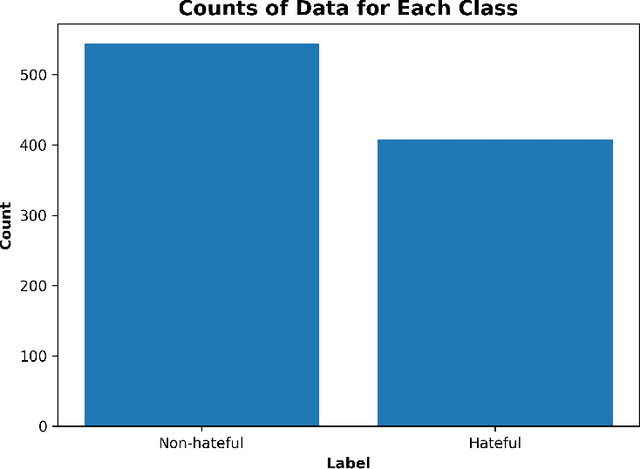
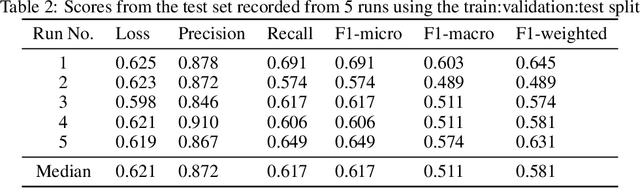
Anti-Muslim hate speech has emerged within memes, characterized by context-dependent and rhetorical messages using text and images that seemingly mimic humor but convey Islamophobic sentiments. This work presents a novel dataset and proposes a classifier based on the Vision-and-Language Transformer (ViLT) specifically tailored to identify anti-Muslim hate within memes by integrating both visual and textual representations. Our model leverages joint modal embeddings between meme images and incorporated text to capture nuanced Islamophobic narratives that are unique to meme culture, providing both high detection accuracy and interoperability.
MosquitoMiner: A Light Weight Rover for Detecting and Eliminating Mosquito Breeding Sites
Sep 12, 2024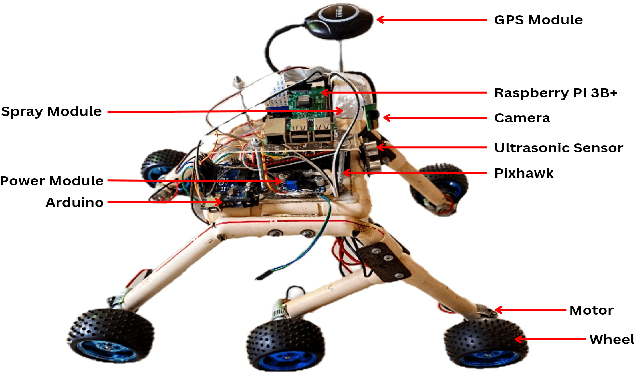
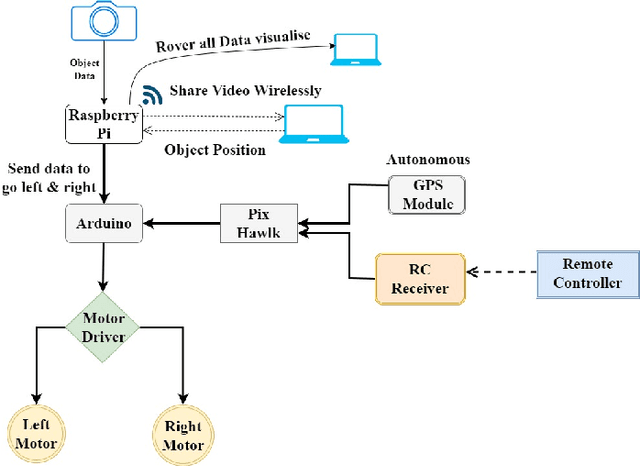


In this paper, we present a novel approach to the development and deployment of an autonomous mosquito breeding place detector rover with the object and obstacle detection capabilities to control mosquitoes. Mosquito-borne diseases continue to pose significant health threats globally, with conventional control methods proving slow and inefficient. Amidst rising concerns over the rapid spread of these diseases, there is an urgent need for innovative and efficient strategies to manage mosquito populations and prevent disease transmission. To mitigate the limitations of manual labor and traditional methods, our rover employs autonomous control strategies. Leveraging our own custom dataset, the rover can autonomously navigate along a pre-defined path, identifying and mitigating potential breeding grounds with precision. It then proceeds to eliminate these breeding grounds by spraying a chemical agent, effectively eradicating mosquito habitats. Our project demonstrates the effectiveness that is absent in traditional ways of controlling and safeguarding public health. The code for this project is available on GitHub at - https://github.com/faiyazabdullah/MosquitoMiner
MosquitoFusion: A Multiclass Dataset for Real-Time Detection of Mosquitoes, Swarms, and Breeding Sites Using Deep Learning
Apr 01, 2024

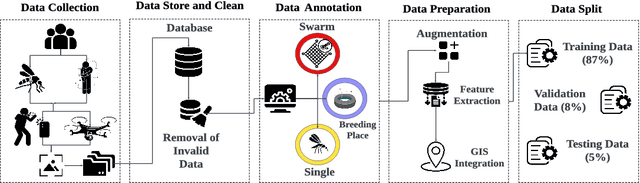
In this paper, we present an integrated approach to real-time mosquito detection using our multiclass dataset (MosquitoFusion) containing 1204 diverse images and leverage cutting-edge technologies, specifically computer vision, to automate the identification of Mosquitoes, Swarms, and Breeding Sites. The pre-trained YOLOv8 model, trained on this dataset, achieved a mean Average Precision (mAP@50) of 57.1%, with precision at 73.4% and recall at 50.5%. The integration of Geographic Information Systems (GIS) further enriches the depth of our analysis, providing valuable insights into spatial patterns. The dataset and code are available at https://github.com/faiyazabdullah/MosquitoFusion.