Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMIMIC: Multimodal Islamophobic Meme Identification and Classification
Paper and Code
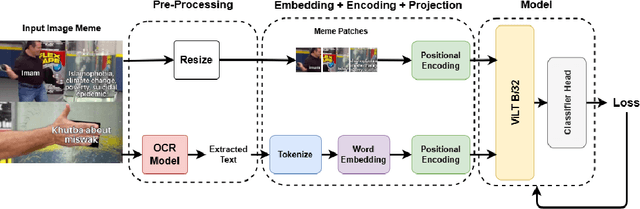

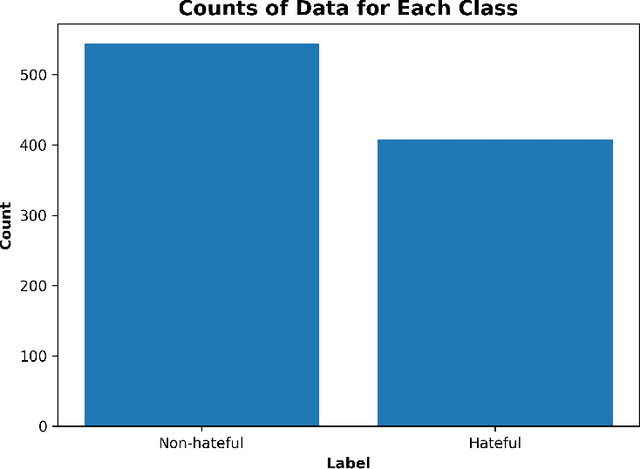
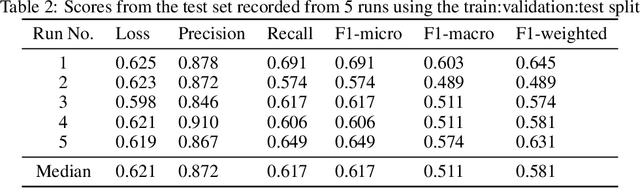
Anti-Muslim hate speech has emerged within memes, characterized by context-dependent and rhetorical messages using text and images that seemingly mimic humor but convey Islamophobic sentiments. This work presents a novel dataset and proposes a classifier based on the Vision-and-Language Transformer (ViLT) specifically tailored to identify anti-Muslim hate within memes by integrating both visual and textual representations. Our model leverages joint modal embeddings between meme images and incorporated text to capture nuanced Islamophobic narratives that are unique to meme culture, providing both high detection accuracy and interoperability.
* Accepted (Poster) - NeurIPS 2024 Workshop MusIML
View paper on