 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWatch, Listen, Understand, Mislead: Tri-modal Adversarial Attacks on Short Videos for Content Appropriateness Evaluation
Jul 16, 2025Multimodal Large Language Models (MLLMs) are increasingly used for content moderation, yet their robustness in short-form video contexts remains underexplored. Current safety evaluations often rely on unimodal attacks, failing to address combined attack vulnerabilities. In this paper, we introduce a comprehensive framework for evaluating the tri-modal safety of MLLMs. First, we present the Short-Video Multimodal Adversarial (SVMA) dataset, comprising diverse short-form videos with human-guided synthetic adversarial attacks. Second, we propose ChimeraBreak, a novel tri-modal attack strategy that simultaneously challenges visual, auditory, and semantic reasoning pathways. Extensive experiments on state-of-the-art MLLMs reveal significant vulnerabilities with high Attack Success Rates (ASR). Our findings uncover distinct failure modes, showing model biases toward misclassifying benign or policy-violating content. We assess results using LLM-as-a-judge, demonstrating attack reasoning efficacy. Our dataset and findings provide crucial insights for developing more robust and safe MLLMs.
MIMIC: Multimodal Islamophobic Meme Identification and Classification
Dec 01, 2024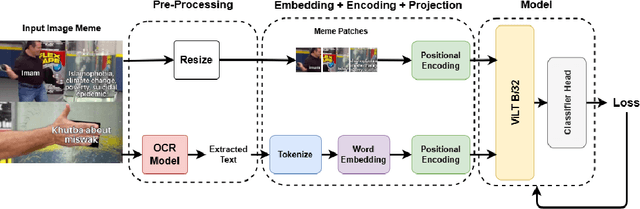

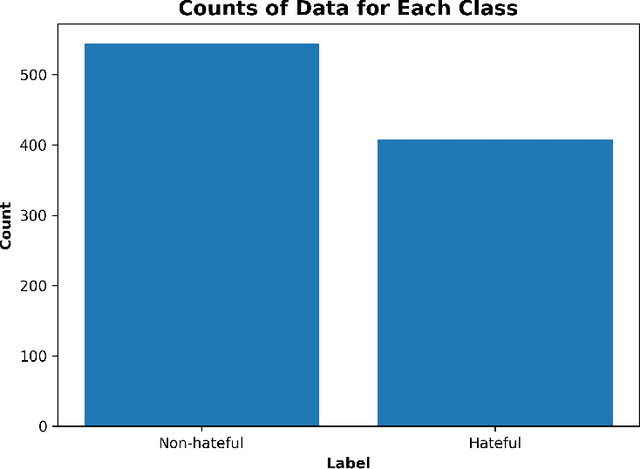
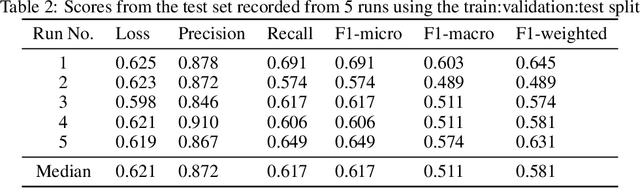
Anti-Muslim hate speech has emerged within memes, characterized by context-dependent and rhetorical messages using text and images that seemingly mimic humor but convey Islamophobic sentiments. This work presents a novel dataset and proposes a classifier based on the Vision-and-Language Transformer (ViLT) specifically tailored to identify anti-Muslim hate within memes by integrating both visual and textual representations. Our model leverages joint modal embeddings between meme images and incorporated text to capture nuanced Islamophobic narratives that are unique to meme culture, providing both high detection accuracy and interoperability.
Transcribing Bengali Text with Regional Dialects to IPA using District Guided Tokens
Apr 02, 2024Accurate transcription of Bengali text to the International Phonetic Alphabet (IPA) is a challenging task due to the complex phonology of the language and context-dependent sound changes. This challenge is even more for regional Bengali dialects due to unavailability of standardized spelling conventions for these dialects, presence of local and foreign words popular in those regions and phonological diversity across different regions. This paper presents an approach to this sequence-to-sequence problem by introducing the District Guided Tokens (DGT) technique on a new dataset spanning six districts of Bangladesh. The key idea is to provide the model with explicit information about the regional dialect or "district" of the input text before generating the IPA transcription. This is achieved by prepending a district token to the input sequence, effectively guiding the model to understand the unique phonetic patterns associated with each district. The DGT technique is applied to fine-tune several transformer-based models, on this new dataset. Experimental results demonstrate the effectiveness of DGT, with the ByT5 model achieving superior performance over word-based models like mT5, BanglaT5, and umT5. This is attributed to ByT5's ability to handle a high percentage of out-of-vocabulary words in the test set. The proposed approach highlights the importance of incorporating regional dialect information into ubiquitous natural language processing systems for languages with diverse phonological variations. The following work was a result of the "Bhashamul" challenge, which is dedicated to solving the problem of Bengali text with regional dialects to IPA transcription https://www.kaggle.com/competitions/regipa/. The training and inference notebooks are available through the competition link.