 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMIMIC: Multimodal Islamophobic Meme Identification and Classification
Dec 01, 2024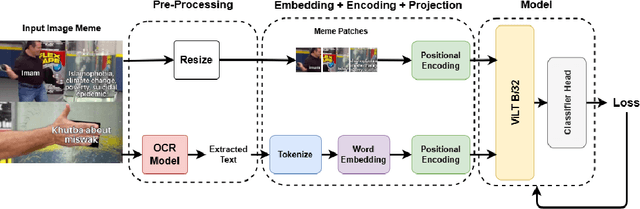

Anti-Muslim hate speech has emerged within memes, characterized by context-dependent and rhetorical messages using text and images that seemingly mimic humor but convey Islamophobic sentiments. This work presents a novel dataset and proposes a classifier based on the Vision-and-Language Transformer (ViLT) specifically tailored to identify anti-Muslim hate within memes by integrating both visual and textual representations. Our model leverages joint modal embeddings between meme images and incorporated text to capture nuanced Islamophobic narratives that are unique to meme culture, providing both high detection accuracy and interoperability.
DPCSpell: A Transformer-based Detector-Purificator-Corrector Framework for Spelling Error Correction of Bangla and Resource Scarce Indic Languages
Nov 07, 2022



Spelling error correction is the task of identifying and rectifying misspelled words in texts. It is a potential and active research topic in Natural Language Processing because of numerous applications in human language understanding. The phonetically or visually similar yet semantically distinct characters make it an arduous task in any language. Earlier efforts on spelling error correction in Bangla and resource-scarce Indic languages focused on rule-based, statistical, and machine learning-based methods which we found rather inefficient. In particular, machine learning-based approaches, which exhibit superior performance to rule-based and statistical methods, are ineffective as they correct each character regardless of its appropriateness. In this work, we propose a novel detector-purificator-corrector framework based on denoising transformers by addressing previous issues. Moreover, we present a method for large-scale corpus creation from scratch which in turn resolves the resource limitation problem of any left-to-right scripted language. The empirical outcomes demonstrate the effectiveness of our approach that outperforms previous state-of-the-art methods by a significant margin for Bangla spelling error correction. The models and corpus are publicly available at https://tinyurl.com/DPCSpell.