 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised Auditory and Semantic Entrainment Models with Deep Neural Networks
Dec 22, 2023


Speakers tend to engage in adaptive behavior, known as entrainment, when they become similar to their interlocutor in various aspects of speaking. We present an unsupervised deep learning framework that derives meaningful representation from textual features for developing semantic entrainment. We investigate the model's performance by extracting features using different variations of the BERT model (DistilBERT and XLM-RoBERTa) and Google's universal sentence encoder (USE) embeddings on two human-human (HH) corpora (The Fisher Corpus English Part 1, Columbia games corpus) and one human-machine (HM) corpus (Voice Assistant Conversation Corpus (VACC)). In addition to semantic features we also trained DNN-based models utilizing two auditory embeddings (TRIpLet Loss network (TRILL) vectors, Low-level descriptors (LLD) features) and two units of analysis (Inter pausal unit and Turn). The results show that semantic entrainment can be assessed with our model, that models can distinguish between HH and HM interactions and that the two units of analysis for extracting acoustic features provide comparable findings.
Speech vocoding for laboratory phonology
Sep 15, 2016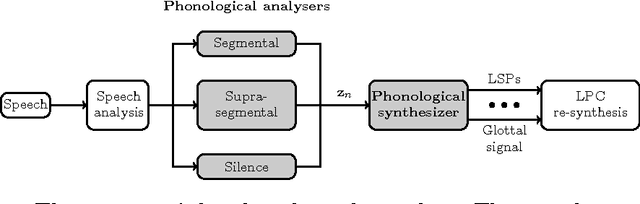
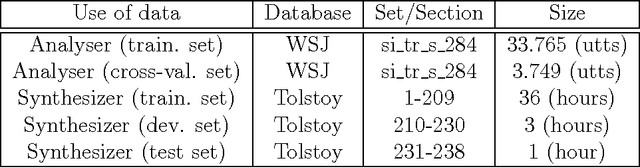
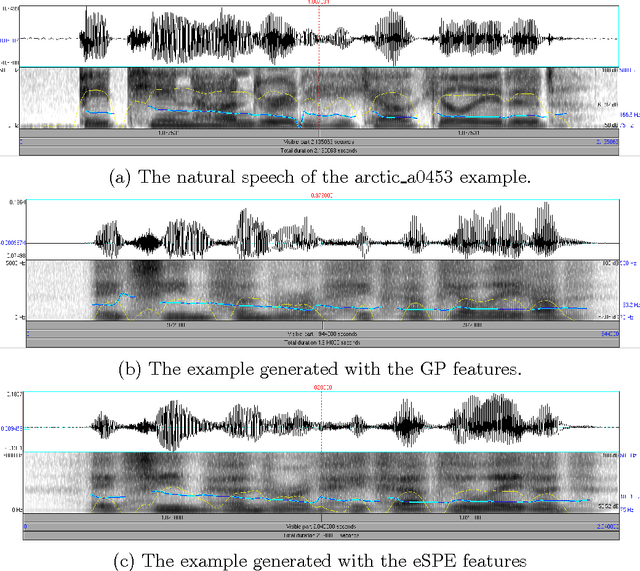
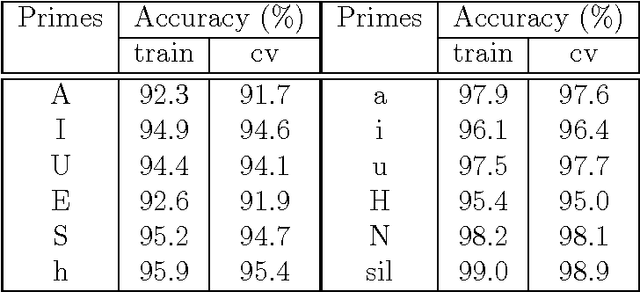
Using phonological speech vocoding, we propose a platform for exploring relations between phonology and speech processing, and in broader terms, for exploring relations between the abstract and physical structures of a speech signal. Our goal is to make a step towards bridging phonology and speech processing and to contribute to the program of Laboratory Phonology. We show three application examples for laboratory phonology: compositional phonological speech modelling, a comparison of phonological systems and an experimental phonological parametric text-to-speech (TTS) system. The featural representations of the following three phonological systems are considered in this work: (i) Government Phonology (GP), (ii) the Sound Pattern of English (SPE), and (iii) the extended SPE (eSPE). Comparing GP- and eSPE-based vocoded speech, we conclude that the latter achieves slightly better results than the former. However, GP - the most compact phonological speech representation - performs comparably to the systems with a higher number of phonological features. The parametric TTS based on phonological speech representation, and trained from an unlabelled audiobook in an unsupervised manner, achieves intelligibility of 85% of the state-of-the-art parametric speech synthesis. We envision that the presented approach paves the way for researchers in both fields to form meaningful hypotheses that are explicitly testable using the concepts developed and exemplified in this paper. On the one hand, laboratory phonologists might test the applied concepts of their theoretical models, and on the other hand, the speech processing community may utilize the concepts developed for the theoretical phonological models for improvements of the current state-of-the-art applications.