 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Swiss German Dictionary: Variation in Speech and Writing
Mar 31, 2020
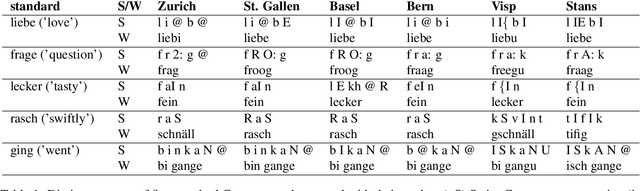

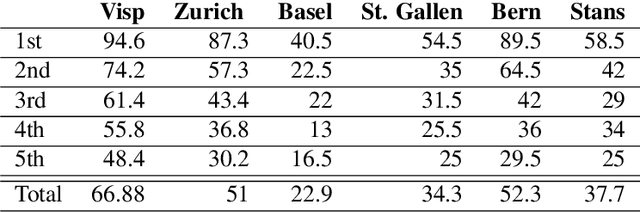
We introduce a dictionary containing forms of common words in various Swiss German dialects normalized into High German. As Swiss German is, for now, a predominantly spoken language, there is a significant variation in the written forms, even between speakers of the same dialect. To alleviate the uncertainty associated with this diversity, we complement the pairs of Swiss German - High German words with the Swiss German phonetic transcriptions (SAMPA). This dictionary becomes thus the first resource to combine large-scale spontaneous translation with phonetic transcriptions. Moreover, we control for the regional distribution and insure the equal representation of the major Swiss dialects. The coupling of the phonetic and written Swiss German forms is powerful. We show that they are sufficient to train a Transformer-based phoneme to grapheme model that generates credible novel Swiss German writings. In addition, we show that the inverse mapping - from graphemes to phonemes - can be modeled with a transformer trained with the novel dictionary. This generation of pronunciations for previously unknown words is key in training extensible automated speech recognition (ASR) systems, which are key beneficiaries of this dictionary.
Alleviating Sequence Information Loss with Data Overlapping and Prime Batch Sizes
Sep 18, 2019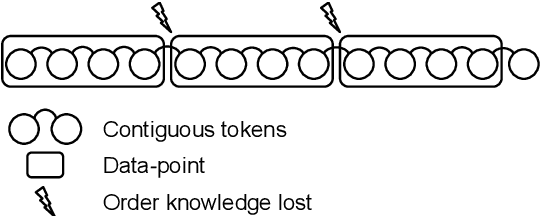

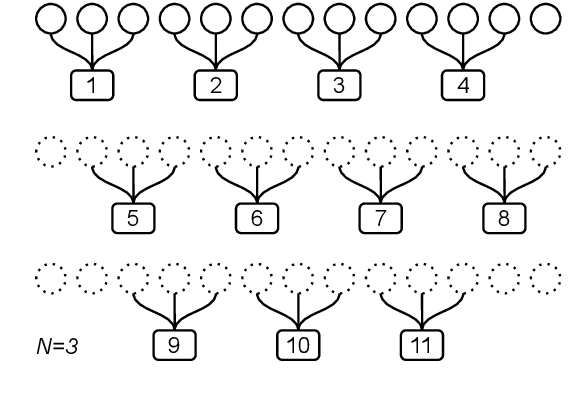

In sequence modeling tasks the token order matters, but this information can be partially lost due to the discretization of the sequence into data points. In this paper, we study the imbalance between the way certain token pairs are included in data points and others are not. We denote this a token order imbalance (TOI) and we link the partial sequence information loss to a diminished performance of the system as a whole, both in text and speech processing tasks. We then provide a mechanism to leverage the full token order information -Alleviated TOI- by iteratively overlapping the token composition of data points. For recurrent networks, we use prime numbers for the batch size to avoid redundancies when building batches from overlapped data points. The proposed method achieved state of the art performance in both text and speech related tasks.
Speech vocoding for laboratory phonology
Sep 15, 2016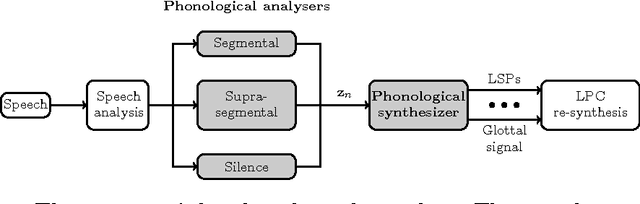
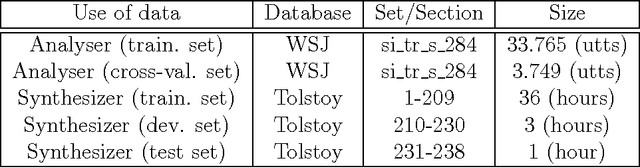
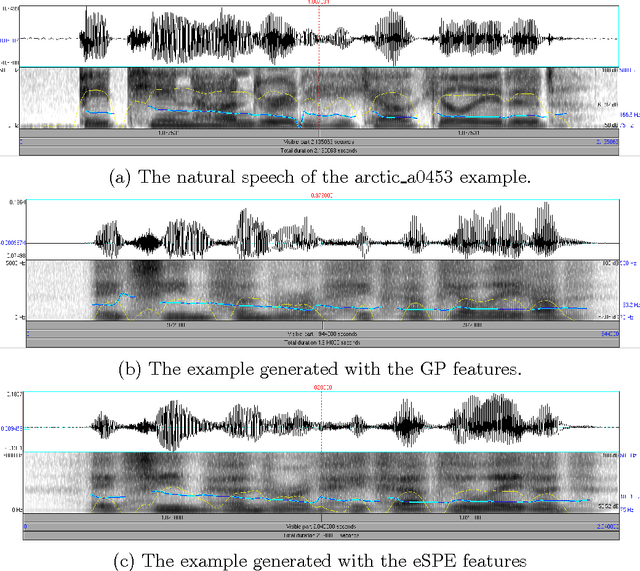
Using phonological speech vocoding, we propose a platform for exploring relations between phonology and speech processing, and in broader terms, for exploring relations between the abstract and physical structures of a speech signal. Our goal is to make a step towards bridging phonology and speech processing and to contribute to the program of Laboratory Phonology. We show three application examples for laboratory phonology: compositional phonological speech modelling, a comparison of phonological systems and an experimental phonological parametric text-to-speech (TTS) system. The featural representations of the following three phonological systems are considered in this work: (i) Government Phonology (GP), (ii) the Sound Pattern of English (SPE), and (iii) the extended SPE (eSPE). Comparing GP- and eSPE-based vocoded speech, we conclude that the latter achieves slightly better results than the former. However, GP - the most compact phonological speech representation - performs comparably to the systems with a higher number of phonological features. The parametric TTS based on phonological speech representation, and trained from an unlabelled audiobook in an unsupervised manner, achieves intelligibility of 85% of the state-of-the-art parametric speech synthesis. We envision that the presented approach paves the way for researchers in both fields to form meaningful hypotheses that are explicitly testable using the concepts developed and exemplified in this paper. On the one hand, laboratory phonologists might test the applied concepts of their theoretical models, and on the other hand, the speech processing community may utilize the concepts developed for the theoretical phonological models for improvements of the current state-of-the-art applications.
Composition of Deep and Spiking Neural Networks for Very Low Bit Rate Speech Coding
Aug 29, 2016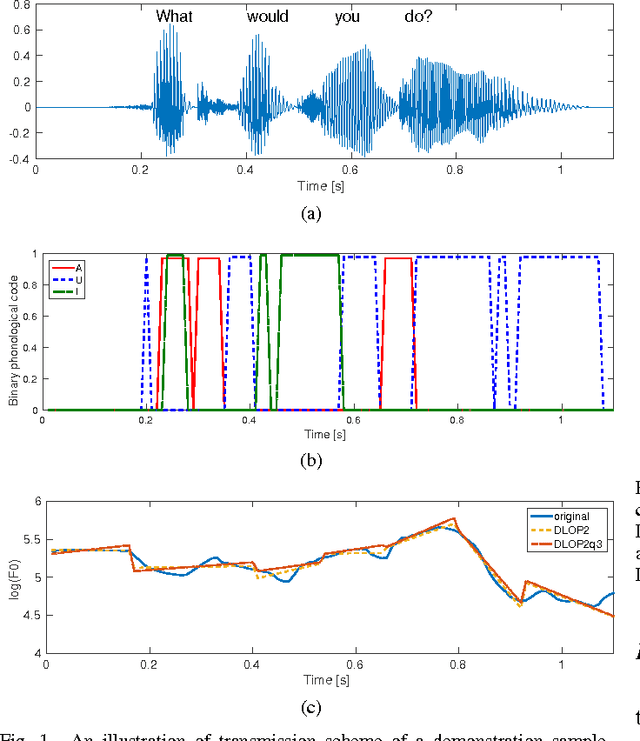
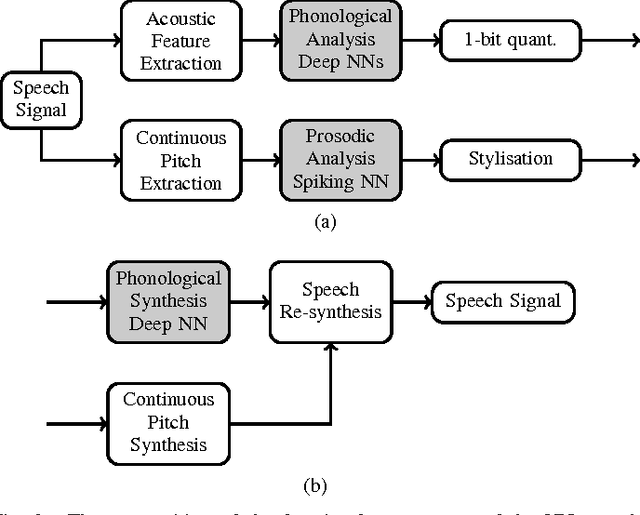
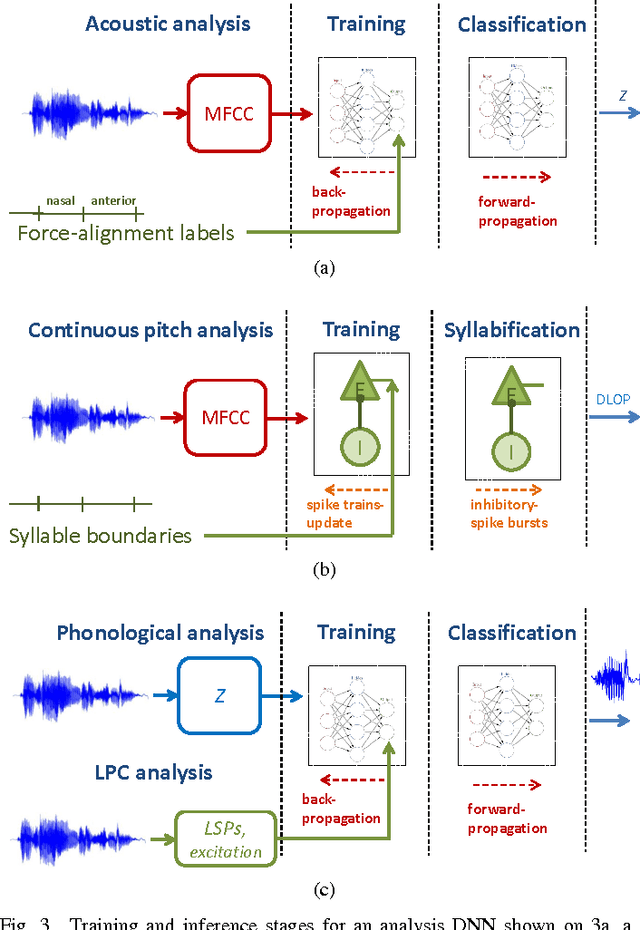

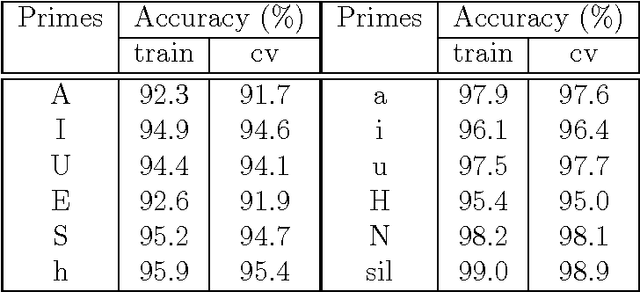
Most current very low bit rate (VLBR) speech coding systems use hidden Markov model (HMM) based speech recognition/synthesis techniques. This allows transmission of information (such as phonemes) segment by segment that decreases the bit rate. However, the encoder based on a phoneme speech recognition may create bursts of segmental errors. Segmental errors are further propagated to optional suprasegmental (such as syllable) information coding. Together with the errors of voicing detection in pitch parametrization, HMM-based speech coding creates speech discontinuities and unnatural speech sound artefacts. In this paper, we propose a novel VLBR speech coding framework based on neural networks (NNs) for end-to-end speech analysis and synthesis without HMMs. The speech coding framework relies on phonological (sub-phonetic) representation of speech, and it is designed as a composition of deep and spiking NNs: a bank of phonological analysers at the transmitter, and a phonological synthesizer at the receiver, both realised as deep NNs, and a spiking NN as an incremental and robust encoder of syllable boundaries for coding of continuous fundamental frequency (F0). A combination of phonological features defines much more sound patterns than phonetic features defined by HMM-based speech coders, and the finer analysis/synthesis code contributes into smoother encoded speech. Listeners significantly prefer the NN-based approach due to fewer discontinuities and speech artefacts of the encoded speech. A single forward pass is required during the speech encoding and decoding. The proposed VLBR speech coding operates at a bit rate of approximately 360 bits/s.