 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Online Learning Efficiency Through Heterogeneous Resource Integration with a Multi-Agent RAG System
Feb 06, 2025


Efficient online learning requires seamless access to diverse resources such as videos, code repositories, documentation, and general web content. This poster paper introduces early-stage work on a Multi-Agent Retrieval-Augmented Generation (RAG) System designed to enhance learning efficiency by integrating these heterogeneous resources. Using specialized agents tailored for specific resource types (e.g., YouTube tutorials, GitHub repositories, documentation websites, and search engines), the system automates the retrieval and synthesis of relevant information. By streamlining the process of finding and combining knowledge, this approach reduces manual effort and enhances the learning experience. A preliminary user study confirmed the system's strong usability and moderate-high utility, demonstrating its potential to improve the efficiency of knowledge acquisition.
Information Theoretic Analysis of DNN-HMM Acoustic Modeling
Nov 08, 2017
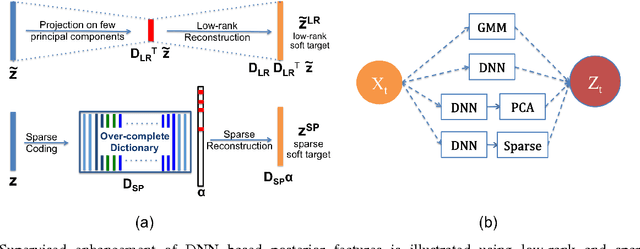


We propose an information theoretic framework for quantitative assessment of acoustic modeling for hidden Markov model (HMM) based automatic speech recognition (ASR). Acoustic modeling yields the probabilities of HMM sub-word states for a short temporal window of speech acoustic features. We cast ASR as a communication channel where the input sub-word probabilities convey the information about the output HMM state sequence. The quality of the acoustic model is thus quantified in terms of the information transmitted through this channel. The process of inferring the most likely HMM state sequence from the sub-word probabilities is known as decoding. HMM based decoding assumes that an acoustic model yields accurate state-level probabilities and the data distribution given the underlying hidden state is independent of any other state in the sequence. We quantify 1) the acoustic model accuracy and 2) its robustness to mismatch between data and the HMM conditional independence assumption in terms of some mutual information quantities. In this context, exploiting deep neural network (DNN) posterior probabilities leads to a simple and straightforward analysis framework to assess shortcomings of the acoustic model for HMM based decoding. This analysis enables us to evaluate the Gaussian mixture acoustic model (GMM) and the importance of many hidden layers in DNNs without any need of explicit speech recognition. In addition, it sheds light on the contribution of low-dimensional models to enhance acoustic modeling for better compliance with the HMM based decoding requirements.
Low-rank and Sparse Soft Targets to Learn Better DNN Acoustic Models
Oct 18, 2016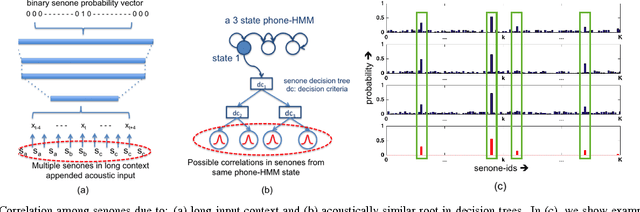

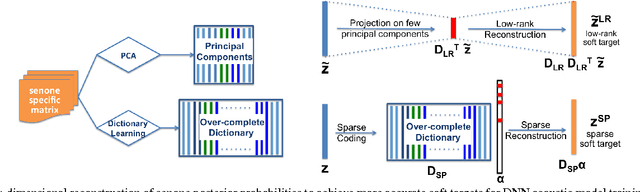
Conventional deep neural networks (DNN) for speech acoustic modeling rely on Gaussian mixture models (GMM) and hidden Markov model (HMM) to obtain binary class labels as the targets for DNN training. Subword classes in speech recognition systems correspond to context-dependent tied states or senones. The present work addresses some limitations of GMM-HMM senone alignments for DNN training. We hypothesize that the senone probabilities obtained from a DNN trained with binary labels can provide more accurate targets to learn better acoustic models. However, DNN outputs bear inaccuracies which are exhibited as high dimensional unstructured noise, whereas the informative components are structured and low-dimensional. We exploit principle component analysis (PCA) and sparse coding to characterize the senone subspaces. Enhanced probabilities obtained from low-rank and sparse reconstructions are used as soft-targets for DNN acoustic modeling, that also enables training with untranscribed data. Experiments conducted on AMI corpus shows 4.6% relative reduction in word error rate.
On Structured Sparsity of Phonological Posteriors for Linguistic Parsing
Aug 30, 2016
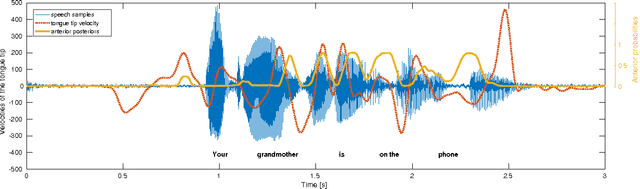
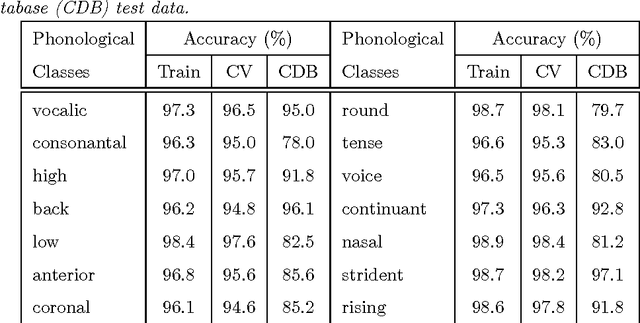
The speech signal conveys information on different time scales from short time scale or segmental, associated to phonological and phonetic information to long time scale or supra segmental, associated to syllabic and prosodic information. Linguistic and neurocognitive studies recognize the phonological classes at segmental level as the essential and invariant representations used in speech temporal organization. In the context of speech processing, a deep neural network (DNN) is an effective computational method to infer the probability of individual phonological classes from a short segment of speech signal. A vector of all phonological class probabilities is referred to as phonological posterior. There are only very few classes comprising a short term speech signal; hence, the phonological posterior is a sparse vector. Although the phonological posteriors are estimated at segmental level, we claim that they convey supra-segmental information. Specifically, we demonstrate that phonological posteriors are indicative of syllabic and prosodic events. Building on findings from converging linguistic evidence on the gestural model of Articulatory Phonology as well as the neural basis of speech perception, we hypothesize that phonological posteriors convey properties of linguistic classes at multiple time scales, and this information is embedded in their support (index) of active coefficients. To verify this hypothesis, we obtain a binary representation of phonological posteriors at the segmental level which is referred to as first-order sparsity structure; the high-order structures are obtained by the concatenation of first-order binary vectors. It is then confirmed that the classification of supra-segmental linguistic events, the problem known as linguistic parsing, can be achieved with high accuracy using asimple binary pattern matching of first-order or high-order structures.
Composition of Deep and Spiking Neural Networks for Very Low Bit Rate Speech Coding
Aug 29, 2016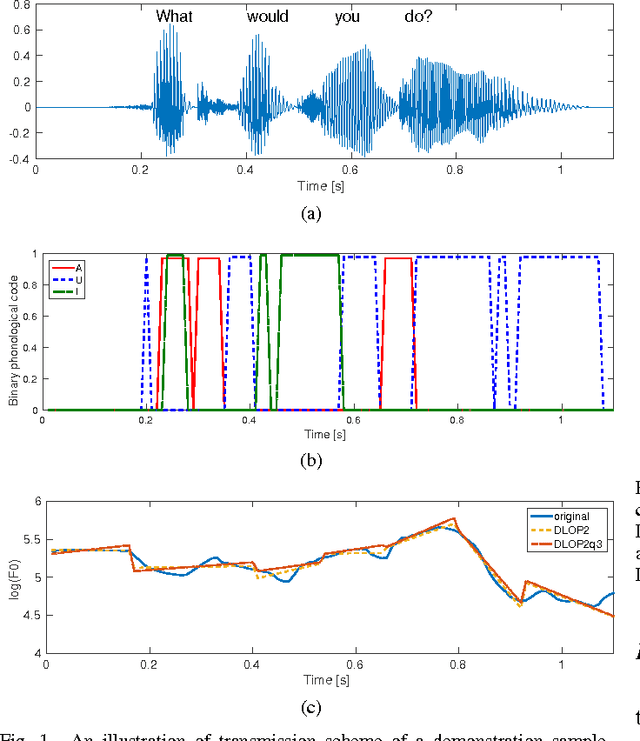
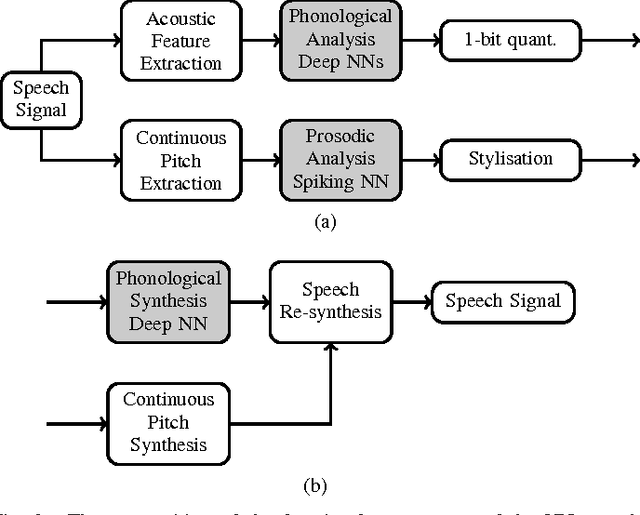
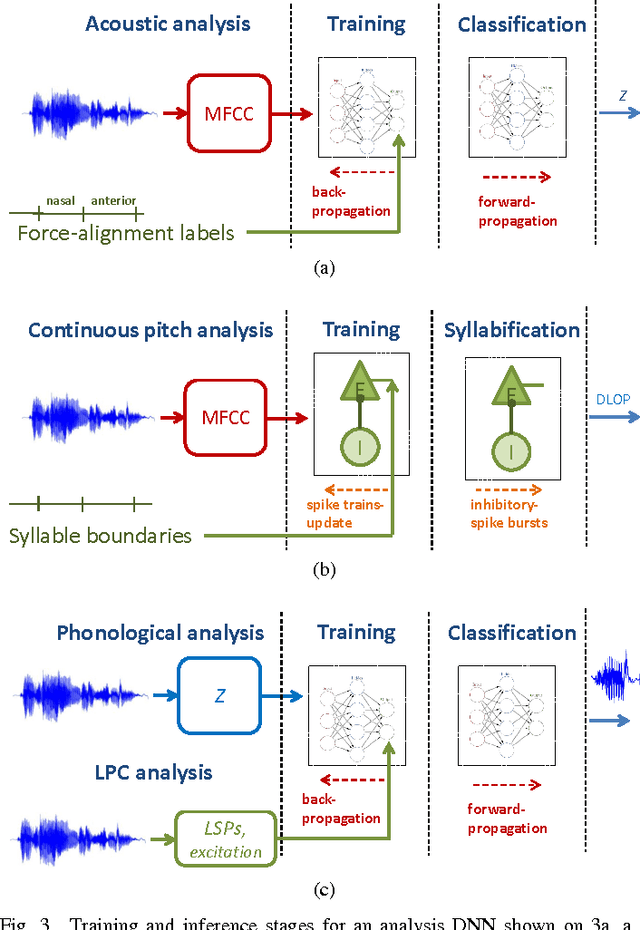

Most current very low bit rate (VLBR) speech coding systems use hidden Markov model (HMM) based speech recognition/synthesis techniques. This allows transmission of information (such as phonemes) segment by segment that decreases the bit rate. However, the encoder based on a phoneme speech recognition may create bursts of segmental errors. Segmental errors are further propagated to optional suprasegmental (such as syllable) information coding. Together with the errors of voicing detection in pitch parametrization, HMM-based speech coding creates speech discontinuities and unnatural speech sound artefacts. In this paper, we propose a novel VLBR speech coding framework based on neural networks (NNs) for end-to-end speech analysis and synthesis without HMMs. The speech coding framework relies on phonological (sub-phonetic) representation of speech, and it is designed as a composition of deep and spiking NNs: a bank of phonological analysers at the transmitter, and a phonological synthesizer at the receiver, both realised as deep NNs, and a spiking NN as an incremental and robust encoder of syllable boundaries for coding of continuous fundamental frequency (F0). A combination of phonological features defines much more sound patterns than phonetic features defined by HMM-based speech coders, and the finer analysis/synthesis code contributes into smoother encoded speech. Listeners significantly prefer the NN-based approach due to fewer discontinuities and speech artefacts of the encoded speech. A single forward pass is required during the speech encoding and decoding. The proposed VLBR speech coding operates at a bit rate of approximately 360 bits/s.
Exploiting Low-dimensional Structures to Enhance DNN Based Acoustic Modeling in Speech Recognition
Jan 22, 2016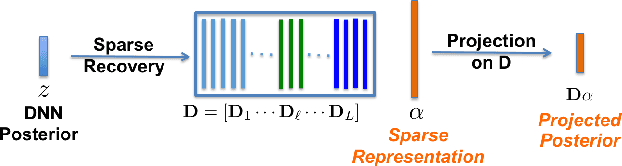
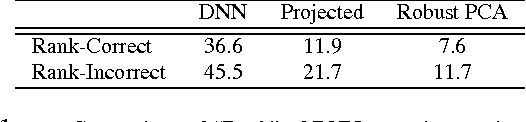
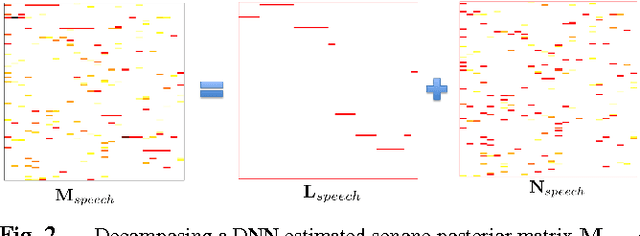
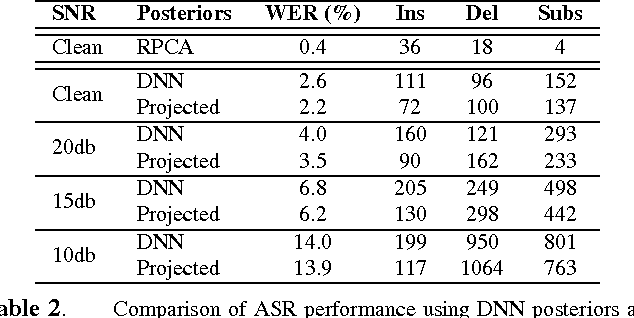
We propose to model the acoustic space of deep neural network (DNN) class-conditional posterior probabilities as a union of low-dimensional subspaces. To that end, the training posteriors are used for dictionary learning and sparse coding. Sparse representation of the test posteriors using this dictionary enables projection to the space of training data. Relying on the fact that the intrinsic dimensions of the posterior subspaces are indeed very small and the matrix of all posteriors belonging to a class has a very low rank, we demonstrate how low-dimensional structures enable further enhancement of the posteriors and rectify the spurious errors due to mismatch conditions. The enhanced acoustic modeling method leads to improvements in continuous speech recognition task using hybrid DNN-HMM (hidden Markov model) framework in both clean and noisy conditions, where upto 15.4% relative reduction in word error rate (WER) is achieved.
Ad Hoc Microphone Array Calibration: Euclidean Distance Matrix Completion Algorithm and Theoretical Guarantees
Aug 31, 2014

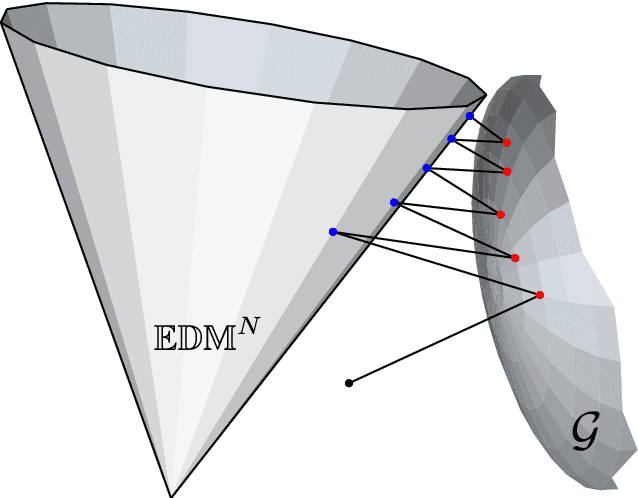
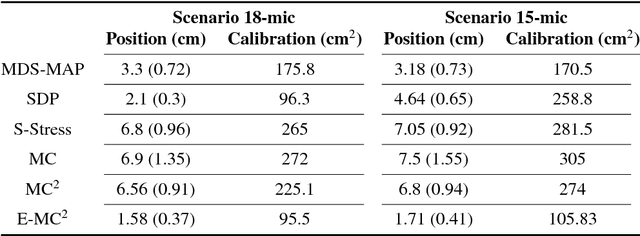
This paper addresses the problem of ad hoc microphone array calibration where only partial information about the distances between microphones is available. We construct a matrix consisting of the pairwise distances and propose to estimate the missing entries based on a novel Euclidean distance matrix completion algorithm by alternative low-rank matrix completion and projection onto the Euclidean distance space. This approach confines the recovered matrix to the EDM cone at each iteration of the matrix completion algorithm. The theoretical guarantees of the calibration performance are obtained considering the random and locally structured missing entries as well as the measurement noise on the known distances. This study elucidates the links between the calibration error and the number of microphones along with the noise level and the ratio of missing distances. Thorough experiments on real data recordings and simulated setups are conducted to demonstrate these theoretical insights. A significant improvement is achieved by the proposed Euclidean distance matrix completion algorithm over the state-of-the-art techniques for ad hoc microphone array calibration.
Structured Sparsity Models for Multiparty Speech Recovery from Reverberant Recordings
Oct 25, 2012
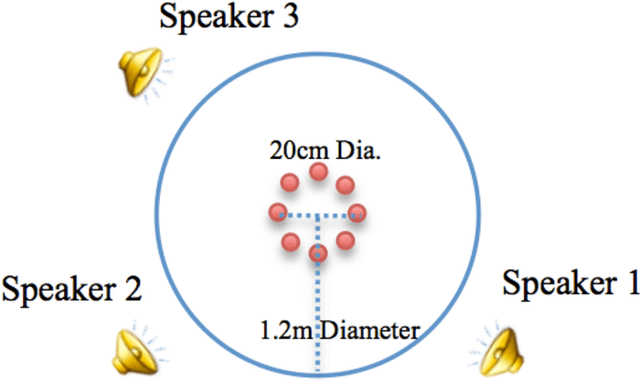
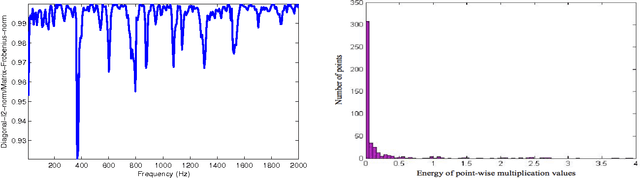
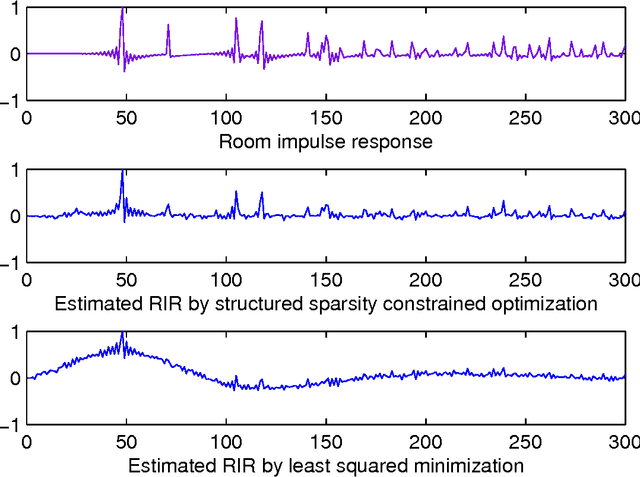
We tackle the multi-party speech recovery problem through modeling the acoustic of the reverberant chambers. Our approach exploits structured sparsity models to perform room modeling and speech recovery. We propose a scheme for characterizing the room acoustic from the unknown competing speech sources relying on localization of the early images of the speakers by sparse approximation of the spatial spectra of the virtual sources in a free-space model. The images are then clustered exploiting the low-rank structure of the spectro-temporal components belonging to each source. This enables us to identify the early support of the room impulse response function and its unique map to the room geometry. To further tackle the ambiguity of the reflection ratios, we propose a novel formulation of the reverberation model and estimate the absorption coefficients through a convex optimization exploiting joint sparsity model formulated upon spatio-spectral sparsity of concurrent speech representation. The acoustic parameters are then incorporated for separating individual speech signals through either structured sparse recovery or inverse filtering the acoustic channels. The experiments conducted on real data recordings demonstrate the effectiveness of the proposed approach for multi-party speech recovery and recognition.