 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInformation Theoretic Analysis of DNN-HMM Acoustic Modeling
Paper and Code
Nov 08, 2017
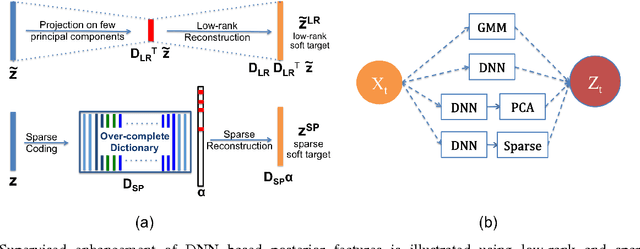


We propose an information theoretic framework for quantitative assessment of acoustic modeling for hidden Markov model (HMM) based automatic speech recognition (ASR). Acoustic modeling yields the probabilities of HMM sub-word states for a short temporal window of speech acoustic features. We cast ASR as a communication channel where the input sub-word probabilities convey the information about the output HMM state sequence. The quality of the acoustic model is thus quantified in terms of the information transmitted through this channel. The process of inferring the most likely HMM state sequence from the sub-word probabilities is known as decoding. HMM based decoding assumes that an acoustic model yields accurate state-level probabilities and the data distribution given the underlying hidden state is independent of any other state in the sequence. We quantify 1) the acoustic model accuracy and 2) its robustness to mismatch between data and the HMM conditional independence assumption in terms of some mutual information quantities. In this context, exploiting deep neural network (DNN) posterior probabilities leads to a simple and straightforward analysis framework to assess shortcomings of the acoustic model for HMM based decoding. This analysis enables us to evaluate the Gaussian mixture acoustic model (GMM) and the importance of many hidden layers in DNNs without any need of explicit speech recognition. In addition, it sheds light on the contribution of low-dimensional models to enhance acoustic modeling for better compliance with the HMM based decoding requirements.