 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComparing CTC and LFMMI for out-of-domain adaptation of wav2vec 2.0 acoustic model
Apr 06, 2021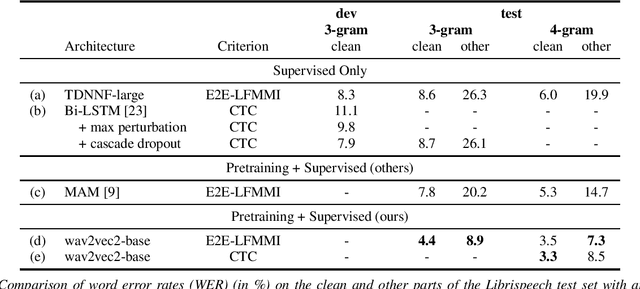
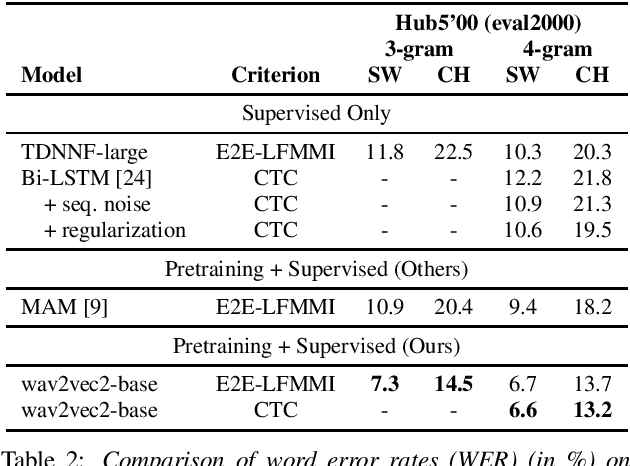
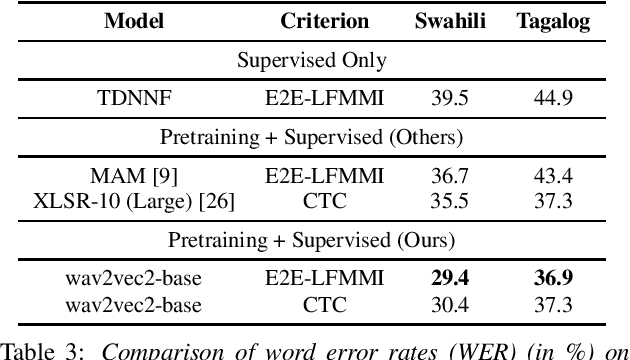
In this work, we investigate if the wav2vec 2.0 self-supervised pretraining helps mitigate the overfitting issues with connectionist temporal classification (CTC) training to reduce its performance gap with flat-start lattice-free MMI (E2E-LFMMI) for automatic speech recognition with limited training data. Towards that objective, we use the pretrained wav2vec 2.0 BASE model and fine-tune it on three different datasets including out-of-domain (Switchboard) and cross-lingual (Babel) scenarios. Our results show that for supervised adaptation of the wav2vec 2.0 model, both E2E-LFMMI and CTC achieve similar results; significantly outperforming the baselines trained only with supervised data. Fine-tuning the wav2vec 2.0 model with E2E-LFMMI and CTC we obtain the following relative WER improvements over the supervised baseline trained with E2E-LFMMI. We get relative improvements of 40% and 44% on the clean-set and 64% and 58% on the test set of Librispeech (100h) respectively. On Switchboard (300h) we obtain relative improvements of 33% and 35% respectively. Finally, for Babel languages, we obtain relative improvements of 26% and 23% on Swahili (38h) and 18% and 17% on Tagalog (84h) respectively.
Lattice-Free MMI Adaptation Of Self-Supervised Pretrained Acoustic Models
Dec 28, 2020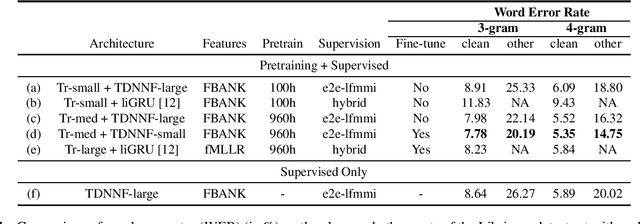
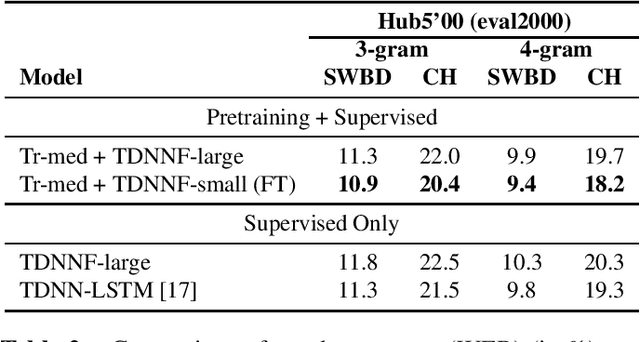
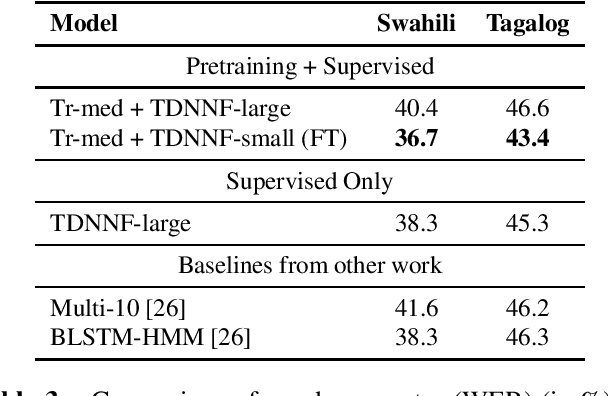
In this work, we propose lattice-free MMI (LFMMI) for supervised adaptation of self-supervised pretrained acoustic model. We pretrain a Transformer model on thousand hours of untranscribed Librispeech data followed by supervised adaptation with LFMMI on three different datasets. Our results show that fine-tuning with LFMMI, we consistently obtain relative WER improvements of 10% and 35.3% on the clean and other test sets of Librispeech (100h), 10.8% on Switchboard (300h), and 4.3% on Swahili (38h) and 4.4% on Tagalog (84h) compared to the baseline trained only with supervised data.
Neural Network based End-to-End Query by Example Spoken Term Detection
Nov 19, 2019
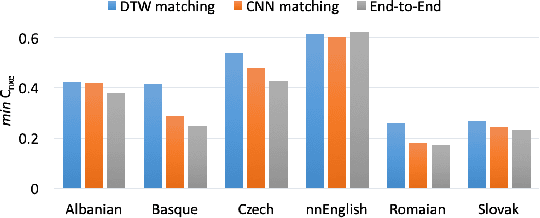
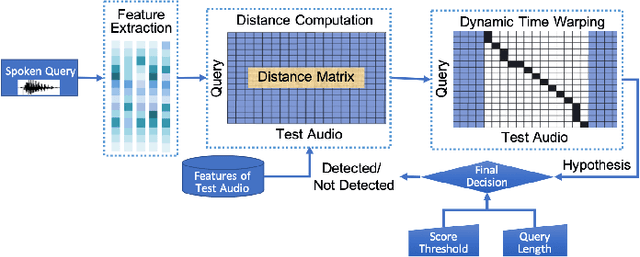
This paper focuses on the problem of query by example spoken term detection (QbE-STD) in zero-resource scenario. State-of-the-art approaches primarily rely on dynamic time warping (DTW) based template matching techniques using phone posterior or bottleneck features extracted from a deep neural network (DNN). We use both monolingual and multilingual bottleneck features, and show that multilingual features perform increasingly better with more training languages. Previously, it has been shown that the DTW based matching can be replaced with a CNN based matching while using posterior features. Here, we show that the CNN based matching outperforms DTW based matching using bottleneck features as well. In this case, the feature extraction and pattern matching stages of our QbE-STD system are optimized independently of each other. We propose to integrate these two stages in a fully neural network based end-to-end learning framework to enable joint optimization of those two stages simultaneously. The proposed approaches are evaluated on two challenging multilingual datasets: Spoken Web Search 2013 and Query by Example Search on Speech Task 2014, demonstrating in each case significant improvements.
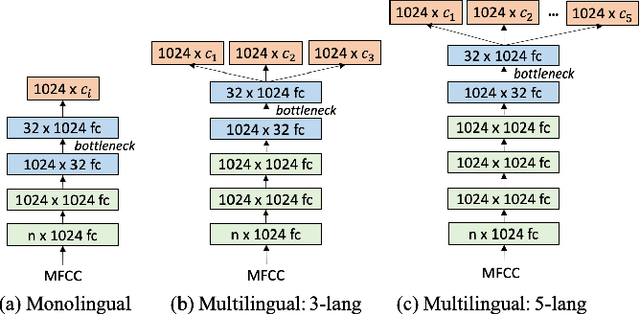
Multilingual Bottleneck Features for Query by Example Spoken Term Detection
Jun 30, 2019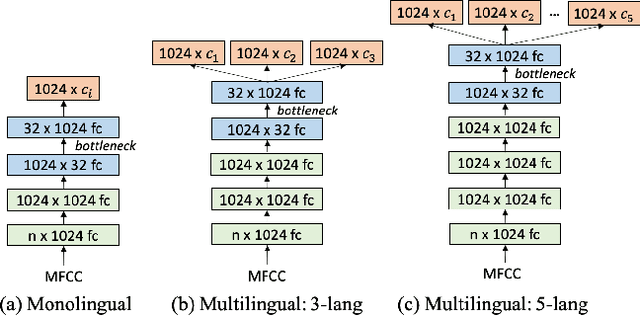
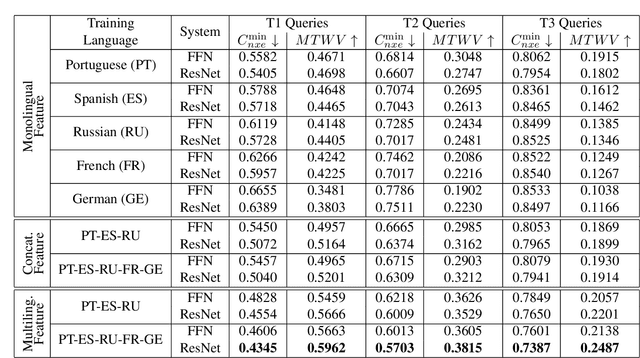
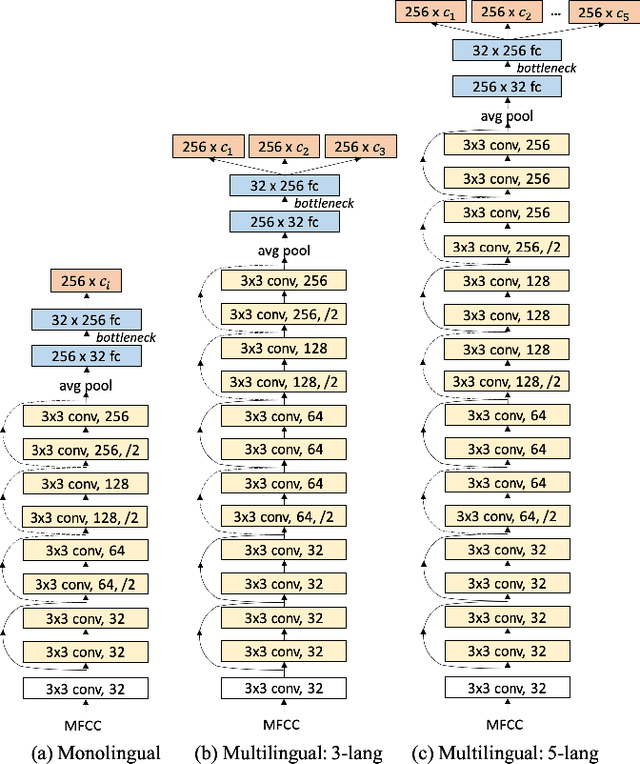

State of the art solutions to query by example spoken term detection (QbE-STD) usually rely on bottleneck feature representation of the query and audio document to perform dynamic time warping (DTW) based template matching. Here, we present a study on QbE-STD performance using several monolingual as well as multilingual bottleneck features extracted from feed forward networks. Then, we propose to employ residual networks (ResNet) to estimate the bottleneck features and show significant improvements over the corresponding feed forward network based features. The neural networks are trained on GlobalPhone corpus and QbE-STD experiments are performed on a very challenging QUESST 2014 database.
Information Theoretic Analysis of DNN-HMM Acoustic Modeling
Nov 08, 2017
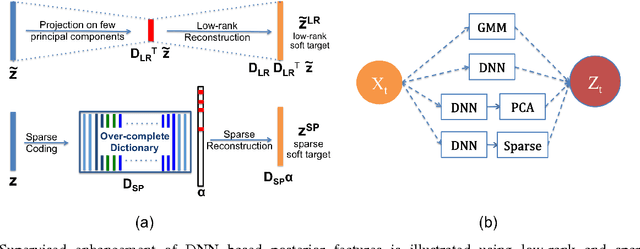


We propose an information theoretic framework for quantitative assessment of acoustic modeling for hidden Markov model (HMM) based automatic speech recognition (ASR). Acoustic modeling yields the probabilities of HMM sub-word states for a short temporal window of speech acoustic features. We cast ASR as a communication channel where the input sub-word probabilities convey the information about the output HMM state sequence. The quality of the acoustic model is thus quantified in terms of the information transmitted through this channel. The process of inferring the most likely HMM state sequence from the sub-word probabilities is known as decoding. HMM based decoding assumes that an acoustic model yields accurate state-level probabilities and the data distribution given the underlying hidden state is independent of any other state in the sequence. We quantify 1) the acoustic model accuracy and 2) its robustness to mismatch between data and the HMM conditional independence assumption in terms of some mutual information quantities. In this context, exploiting deep neural network (DNN) posterior probabilities leads to a simple and straightforward analysis framework to assess shortcomings of the acoustic model for HMM based decoding. This analysis enables us to evaluate the Gaussian mixture acoustic model (GMM) and the importance of many hidden layers in DNNs without any need of explicit speech recognition. In addition, it sheds light on the contribution of low-dimensional models to enhance acoustic modeling for better compliance with the HMM based decoding requirements.
On Structured Sparsity of Phonological Posteriors for Linguistic Parsing
Aug 30, 2016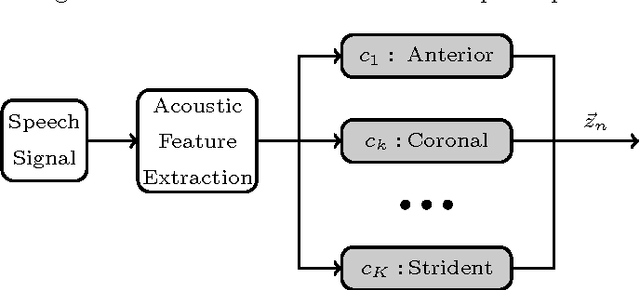
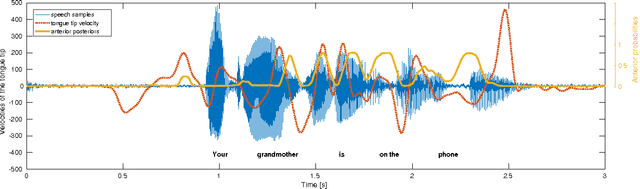
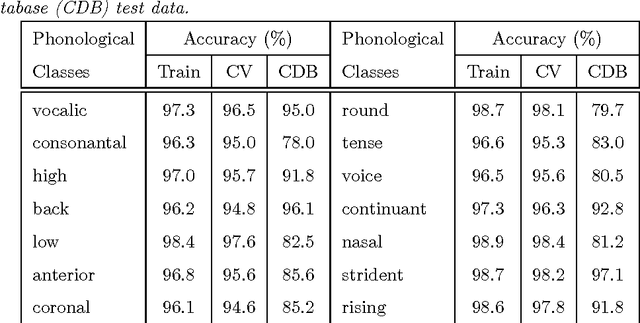
The speech signal conveys information on different time scales from short time scale or segmental, associated to phonological and phonetic information to long time scale or supra segmental, associated to syllabic and prosodic information. Linguistic and neurocognitive studies recognize the phonological classes at segmental level as the essential and invariant representations used in speech temporal organization. In the context of speech processing, a deep neural network (DNN) is an effective computational method to infer the probability of individual phonological classes from a short segment of speech signal. A vector of all phonological class probabilities is referred to as phonological posterior. There are only very few classes comprising a short term speech signal; hence, the phonological posterior is a sparse vector. Although the phonological posteriors are estimated at segmental level, we claim that they convey supra-segmental information. Specifically, we demonstrate that phonological posteriors are indicative of syllabic and prosodic events. Building on findings from converging linguistic evidence on the gestural model of Articulatory Phonology as well as the neural basis of speech perception, we hypothesize that phonological posteriors convey properties of linguistic classes at multiple time scales, and this information is embedded in their support (index) of active coefficients. To verify this hypothesis, we obtain a binary representation of phonological posteriors at the segmental level which is referred to as first-order sparsity structure; the high-order structures are obtained by the concatenation of first-order binary vectors. It is then confirmed that the classification of supra-segmental linguistic events, the problem known as linguistic parsing, can be achieved with high accuracy using asimple binary pattern matching of first-order or high-order structures.
Structured Sparsity Models for Multiparty Speech Recovery from Reverberant Recordings
Oct 25, 2012
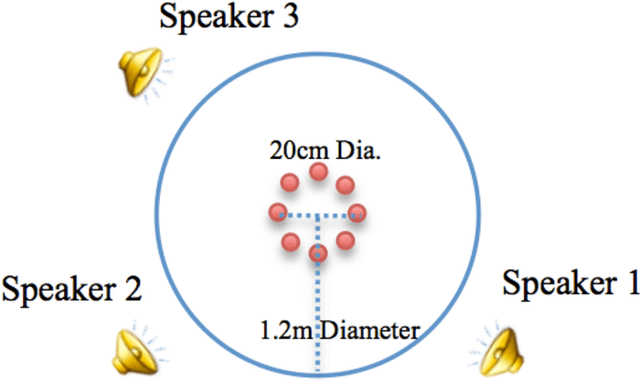
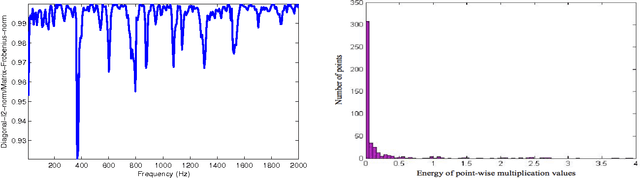
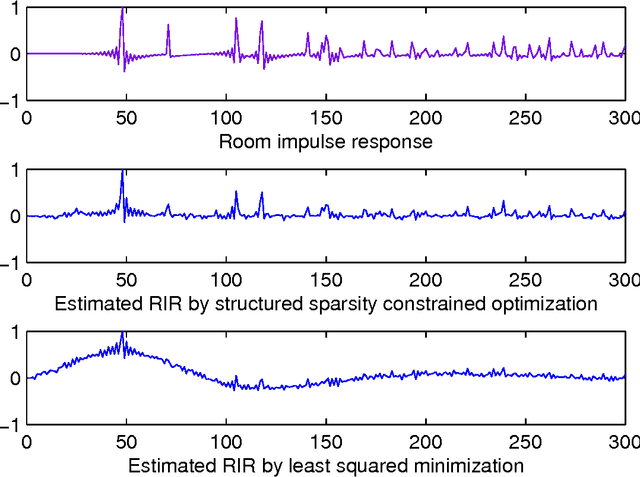
We tackle the multi-party speech recovery problem through modeling the acoustic of the reverberant chambers. Our approach exploits structured sparsity models to perform room modeling and speech recovery. We propose a scheme for characterizing the room acoustic from the unknown competing speech sources relying on localization of the early images of the speakers by sparse approximation of the spatial spectra of the virtual sources in a free-space model. The images are then clustered exploiting the low-rank structure of the spectro-temporal components belonging to each source. This enables us to identify the early support of the room impulse response function and its unique map to the room geometry. To further tackle the ambiguity of the reflection ratios, we propose a novel formulation of the reverberation model and estimate the absorption coefficients through a convex optimization exploiting joint sparsity model formulated upon spatio-spectral sparsity of concurrent speech representation. The acoustic parameters are then incorporated for separating individual speech signals through either structured sparse recovery or inverse filtering the acoustic channels. The experiments conducted on real data recordings demonstrate the effectiveness of the proposed approach for multi-party speech recovery and recognition.