Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultilingual Bottleneck Features for Query by Example Spoken Term Detection
Paper and Code
Jun 30, 2019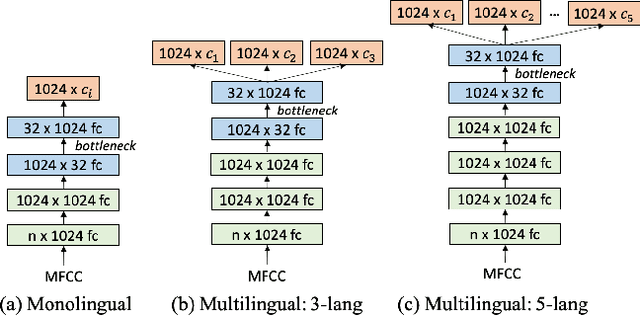
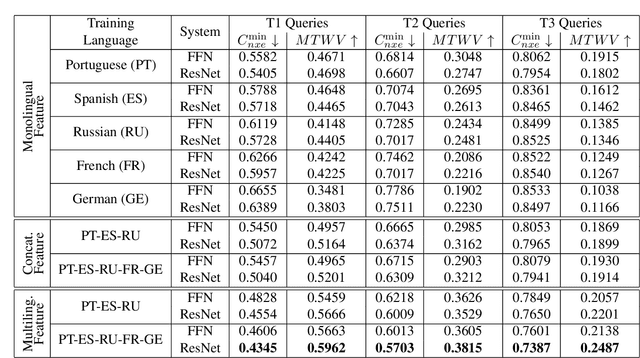
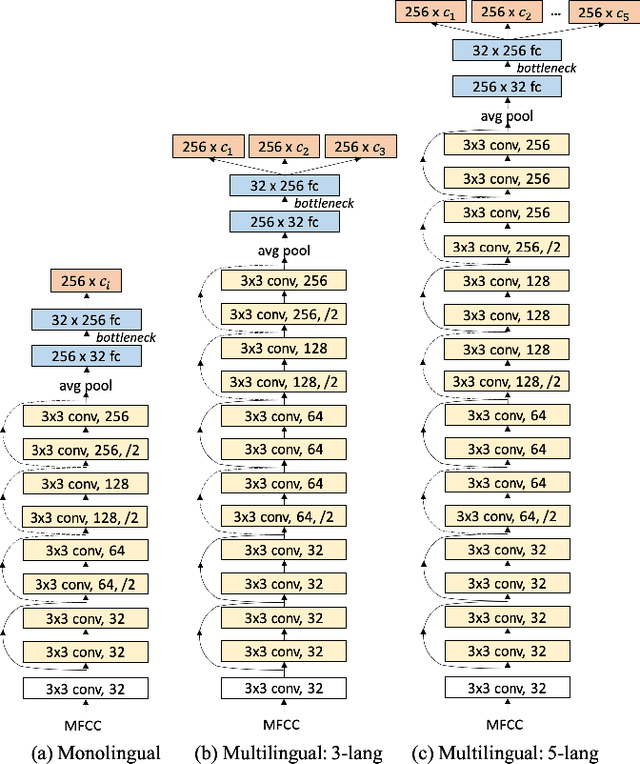

State of the art solutions to query by example spoken term detection (QbE-STD) usually rely on bottleneck feature representation of the query and audio document to perform dynamic time warping (DTW) based template matching. Here, we present a study on QbE-STD performance using several monolingual as well as multilingual bottleneck features extracted from feed forward networks. Then, we propose to employ residual networks (ResNet) to estimate the bottleneck features and show significant improvements over the corresponding feed forward network based features. The neural networks are trained on GlobalPhone corpus and QbE-STD experiments are performed on a very challenging QUESST 2014 database.
View paper on