Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLattice-Free MMI Adaptation Of Self-Supervised Pretrained Acoustic Models
Paper and Code
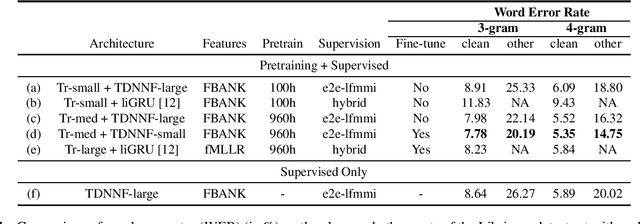
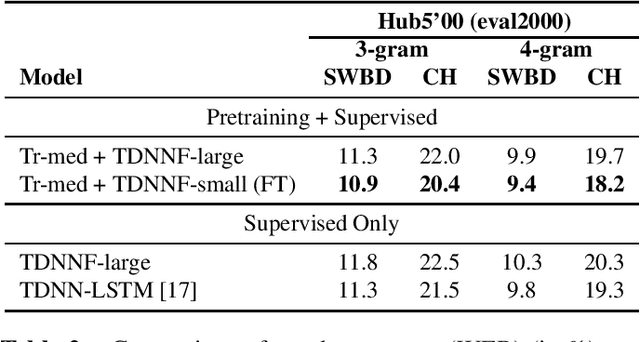
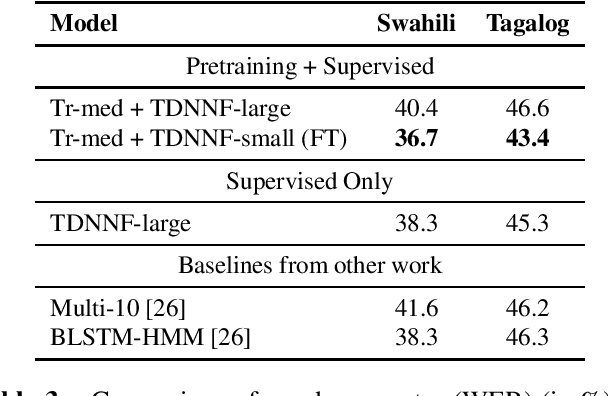
In this work, we propose lattice-free MMI (LFMMI) for supervised adaptation of self-supervised pretrained acoustic model. We pretrain a Transformer model on thousand hours of untranscribed Librispeech data followed by supervised adaptation with LFMMI on three different datasets. Our results show that fine-tuning with LFMMI, we consistently obtain relative WER improvements of 10% and 35.3% on the clean and other test sets of Librispeech (100h), 10.8% on Switchboard (300h), and 4.3% on Swahili (38h) and 4.4% on Tagalog (84h) compared to the baseline trained only with supervised data.
View paper on