 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFew-Shot Structured Policy Learning for Multi-Domain and Multi-Task Dialogues
Feb 22, 2023



Reinforcement learning has been widely adopted to model dialogue managers in task-oriented dialogues. However, the user simulator provided by state-of-the-art dialogue frameworks are only rough approximations of human behaviour. The ability to learn from a small number of human interactions is hence crucial, especially on multi-domain and multi-task environments where the action space is large. We therefore propose to use structured policies to improve sample efficiency when learning on these kinds of environments. We also evaluate the impact of learning from human vs simulated experts. Among the different levels of structure that we tested, the graph neural networks (GNNs) show a remarkable superiority by reaching a success rate above 80% with only 50 dialogues, when learning from simulated experts. They also show superiority when learning from human experts, although a performance drop was observed, indicating a possible difficulty in capturing the variability of human strategies. We therefore suggest to concentrate future research efforts on bridging the gap between human data, simulators and automatic evaluators in dialogue frameworks.
Graph Neural Network Policies and Imitation Learning for Multi-Domain Task-Oriented Dialogues
Oct 11, 2022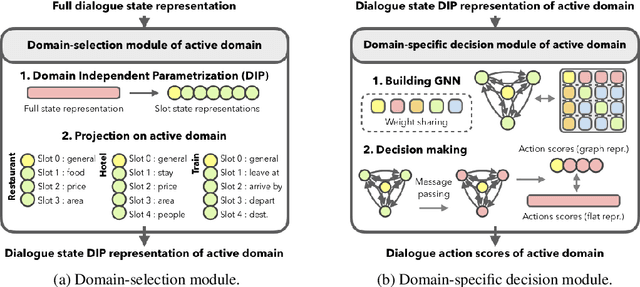

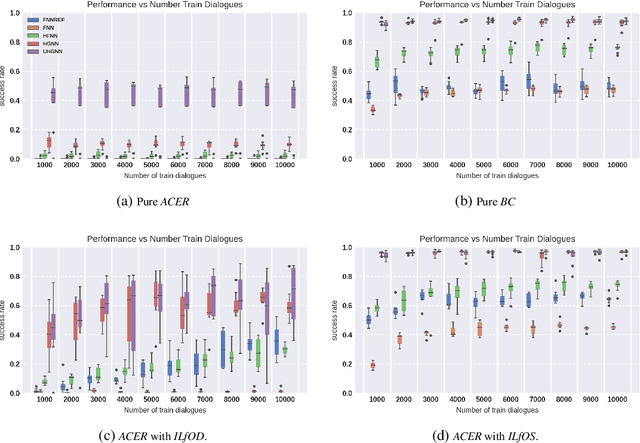
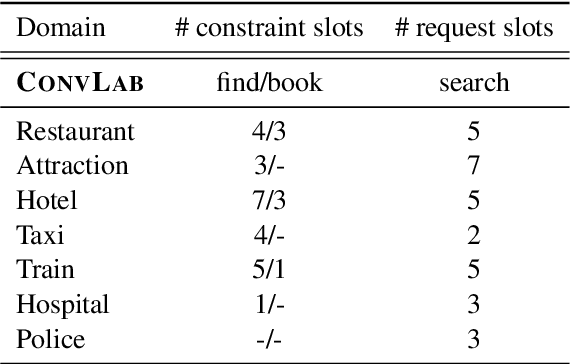
Task-oriented dialogue systems are designed to achieve specific goals while conversing with humans. In practice, they may have to handle simultaneously several domains and tasks. The dialogue manager must therefore be able to take into account domain changes and plan over different domains/tasks in order to deal with multidomain dialogues. However, learning with reinforcement in such context becomes difficult because the state-action dimension is larger while the reward signal remains scarce. Our experimental results suggest that structured policies based on graph neural networks combined with different degrees of imitation learning can effectively handle multi-domain dialogues. The reported experiments underline the benefit of structured policies over standard policies.
Diluted Near-Optimal Expert Demonstrations for Guiding Dialogue Stochastic Policy Optimisation
Nov 25, 2020

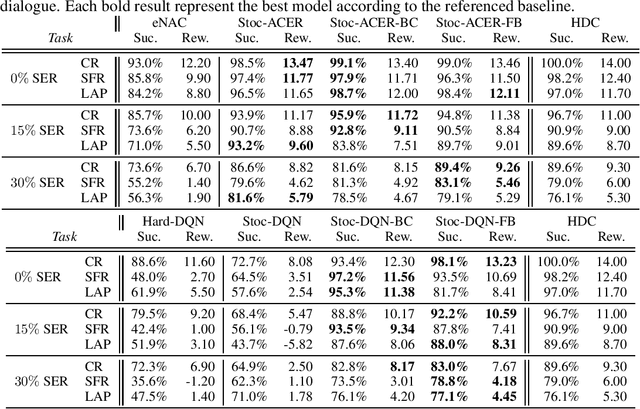
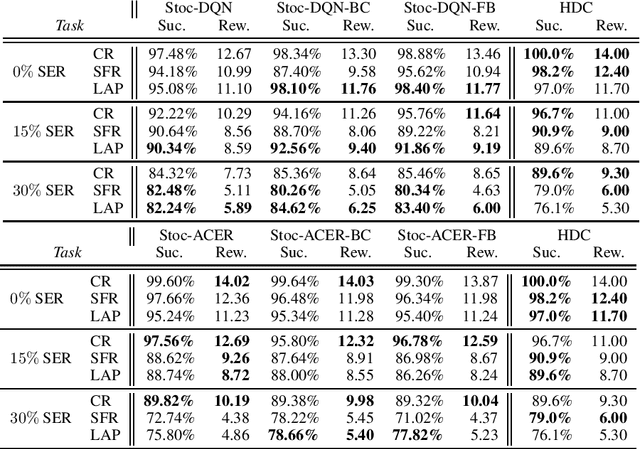
A learning dialogue agent can infer its behaviour from interactions with the users. These interactions can be taken from either human-to-human or human-machine conversations. However, human interactions are scarce and costly, making learning from few interactions essential. One solution to speedup the learning process is to guide the agent's exploration with the help of an expert. We present in this paper several imitation learning strategies for dialogue policy where the guiding expert is a near-optimal handcrafted policy. We incorporate these strategies with state-of-the-art reinforcement learning methods based on Q-learning and actor-critic. We notably propose a randomised exploration policy which allows for a seamless hybridisation of the learned policy and the expert. Our experiments show that our hybridisation strategy outperforms several baselines, and that it can accelerate the learning when facing real humans.