 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHyperparameter Optimization for Large Language Model Instruction-Tuning
Dec 01, 2023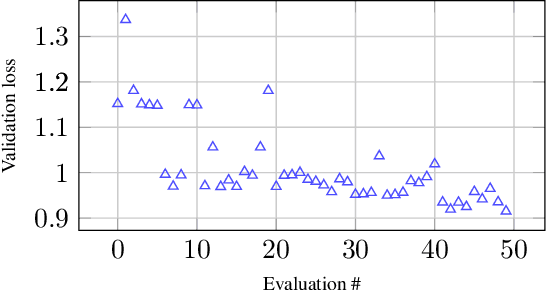
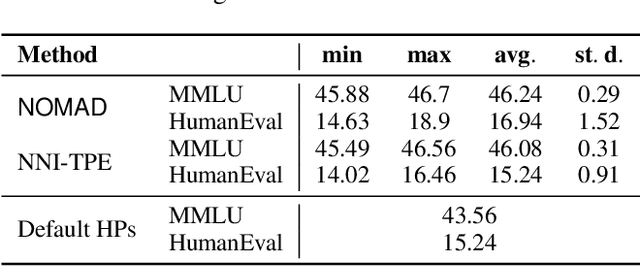
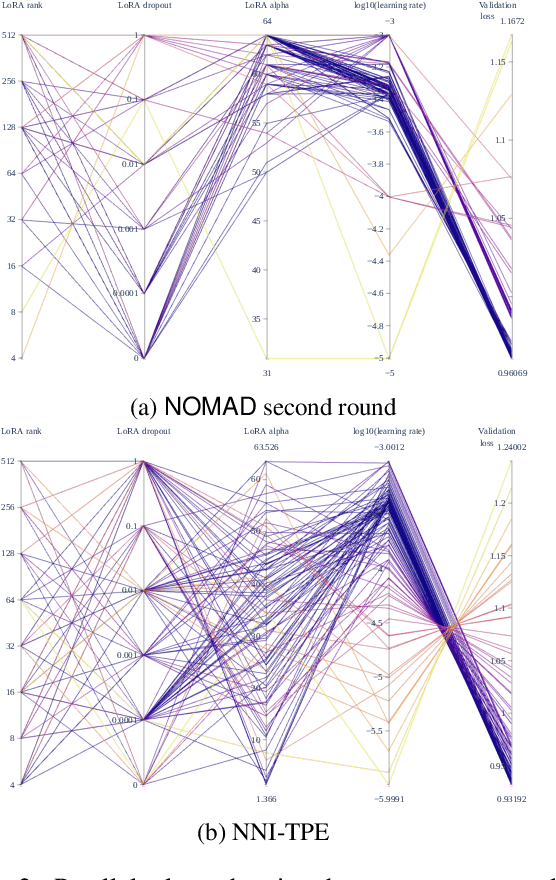

The fine-tuning of Large Language Models (LLMs) has enabled them to recently achieve milestones in natural language processing applications. The emergence of ever larger LLMs has paved the way for more efficient fine-tuning methods. Among these, the Low-Rank Adaptation (LoRA) method keeps most of the weights of the pre-trained LLM frozen while introducing a low-rank decomposition of the weight matrix, enabling the tuning of only a very small proportion of the network. The performance on downstream tasks of models fine-tuned with LoRA heavily relies on a set of hyperparameters including the rank of the decomposition. In this work, we investigate the choice of these hyperparameters through two main blackbox optimization (BBO) techniques. We examine the whole pipeline of performing fine-tuning and validation on a pre-trained LLM as a blackbox and efficiently explore the space of hyperparameters with the \nomad algorithm, achieving a boost in performance and human alignment of the tuned model.