 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAttribute Controlled Dialogue Prompting
Jul 11, 2023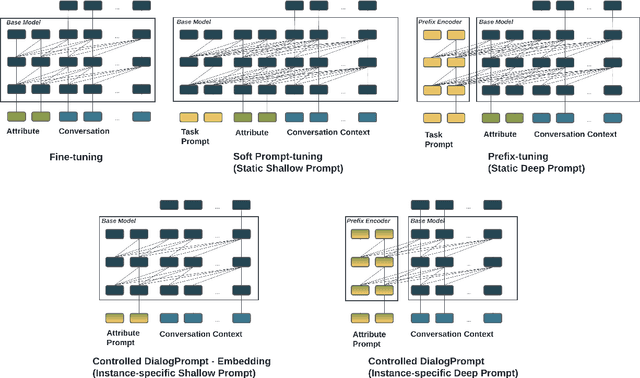


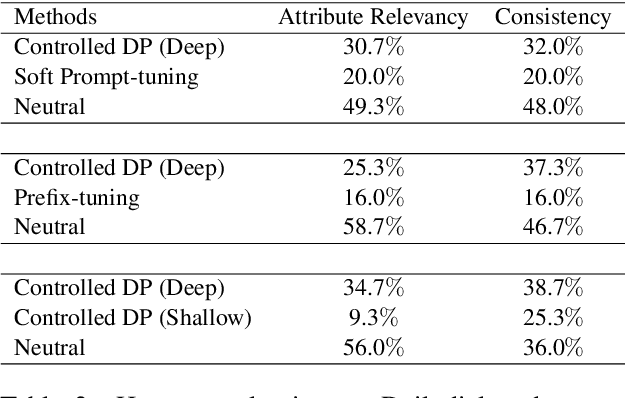
Prompt-tuning has become an increasingly popular parameter-efficient method for adapting large pretrained language models to downstream tasks. However, both discrete prompting and continuous prompting assume fixed prompts for all data samples within a task, neglecting the fact that inputs vary greatly in some tasks such as open-domain dialogue generation. In this paper, we present a novel, instance-specific prompt-tuning algorithm for dialogue generation. Specifically, we generate prompts based on instance-level control code, rather than the conversation history, to explore their impact on controlled dialogue generation. Experiments on popular open-domain dialogue datasets, evaluated on both automated metrics and human evaluation, demonstrate that our method is superior to prompting baselines and comparable to fine-tuning with only 5%-6% of total parameters.
PEER: A Comprehensive and Multi-Task Benchmark for Protein Sequence Understanding
Jun 05, 2022


We are now witnessing significant progress of deep learning methods in a variety of tasks (or datasets) of proteins. However, there is a lack of a standard benchmark to evaluate the performance of different methods, which hinders the progress of deep learning in this field. In this paper, we propose such a benchmark called PEER, a comprehensive and multi-task benchmark for Protein sEquence undERstanding. PEER provides a set of diverse protein understanding tasks including protein function prediction, protein localization prediction, protein structure prediction, protein-protein interaction prediction, and protein-ligand interaction prediction. We evaluate different types of sequence-based methods for each task including traditional feature engineering approaches, different sequence encoding methods as well as large-scale pre-trained protein language models. In addition, we also investigate the performance of these methods under the multi-task learning setting. Experimental results show that large-scale pre-trained protein language models achieve the best performance for most individual tasks, and jointly training multiple tasks further boosts the performance. The datasets and source codes of this benchmark will be open-sourced soon.
TorchDrug: A Powerful and Flexible Machine Learning Platform for Drug Discovery
Feb 16, 2022

Machine learning has huge potential to revolutionize the field of drug discovery and is attracting increasing attention in recent years. However, lacking domain knowledge (e.g., which tasks to work on), standard benchmarks and data preprocessing pipelines are the main obstacles for machine learning researchers to work in this domain. To facilitate the progress of machine learning for drug discovery, we develop TorchDrug, a powerful and flexible machine learning platform for drug discovery built on top of PyTorch. TorchDrug benchmarks a variety of important tasks in drug discovery, including molecular property prediction, pretrained molecular representations, de novo molecular design and optimization, retrosynthsis prediction, and biomedical knowledge graph reasoning. State-of-the-art techniques based on geometric deep learning (or graph machine learning), deep generative models, reinforcement learning and knowledge graph reasoning are implemented for these tasks. TorchDrug features a hierarchical interface that facilitates customization from both novices and experts in this domain. Tutorials, benchmark results and documentation are available at https://torchdrug.ai. Code is released under Apache License 2.0.