 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCommand A: An Enterprise-Ready Large Language Model
Apr 01, 2025



In this report we describe the development of Command A, a powerful large language model purpose-built to excel at real-world enterprise use cases. Command A is an agent-optimised and multilingual-capable model, with support for 23 languages of global business, and a novel hybrid architecture balancing efficiency with top of the range performance. It offers best-in-class Retrieval Augmented Generation (RAG) capabilities with grounding and tool use to automate sophisticated business processes. These abilities are achieved through a decentralised training approach, including self-refinement algorithms and model merging techniques. We also include results for Command R7B which shares capability and architectural similarities to Command A. Weights for both models have been released for research purposes. This technical report details our original training pipeline and presents an extensive evaluation of our models across a suite of enterprise-relevant tasks and public benchmarks, demonstrating excellent performance and efficiency.
OAC: Output-adaptive Calibration for Accurate Post-training Quantization
May 23, 2024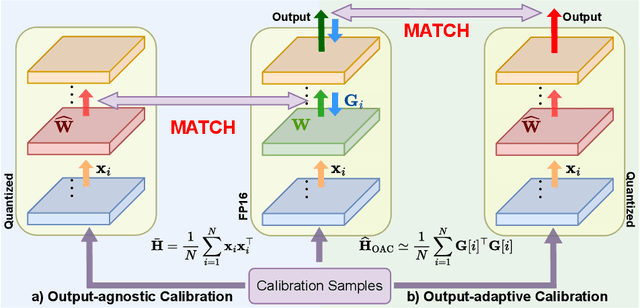
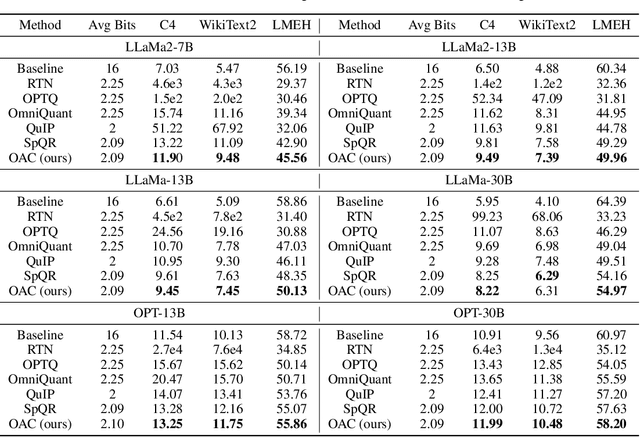
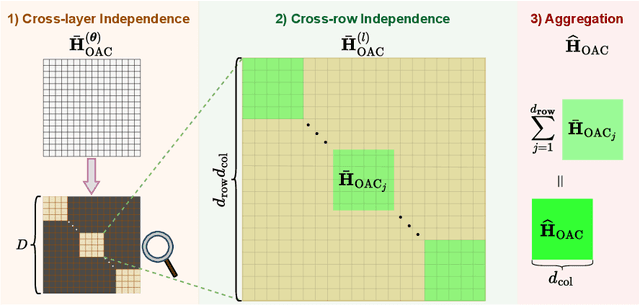
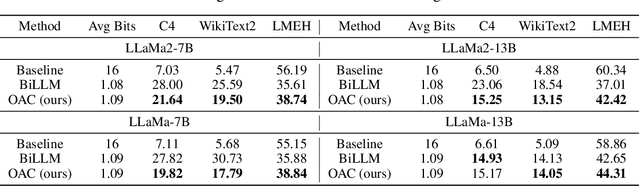
Deployment of Large Language Models (LLMs) has major computational costs, due to their rapidly expanding size. Compression of LLMs reduces the memory footprint, latency, and energy required for their inference. Post-training Quantization (PTQ) techniques have been developed to compress LLMs while avoiding expensive re-training. Most PTQ approaches formulate the quantization error based on a layer-wise $\ell_2$ loss, ignoring the model output. Then, each layer is calibrated using its layer-wise Hessian to update the weights towards minimizing the $\ell_2$ quantization error. The Hessian is also used for detecting the most salient weights to quantization. Such PTQ approaches are prone to accuracy drop in low-precision quantization. We propose Output-adaptive Calibration (OAC) to incorporate the model output in the calibration process. We formulate the quantization error based on the distortion of the output cross-entropy loss. OAC approximates the output-adaptive Hessian for each layer under reasonable assumptions to reduce the computational complexity. The output-adaptive Hessians are used to update the weight matrices and detect the salient weights towards maintaining the model output. Our proposed method outperforms the state-of-the-art baselines such as SpQR and BiLLM, especially, at extreme low-precision (2-bit and binary) quantization.
AdCorDA: Classifier Refinement via Adversarial Correction and Domain Adaptation
Jan 24, 2024This paper describes a simple yet effective technique for refining a pretrained classifier network. The proposed AdCorDA method is based on modification of the training set and making use of the duality between network weights and layer inputs. We call this input space training. The method consists of two stages - adversarial correction followed by domain adaptation. Adversarial correction uses adversarial attacks to correct incorrect training-set classifications. The incorrectly classified samples of the training set are removed and replaced with the adversarially corrected samples to form a new training set, and then, in the second stage, domain adaptation is performed back to the original training set. Extensive experimental validations show significant accuracy boosts of over 5% on the CIFAR-100 dataset. The technique can be straightforwardly applied to refinement of weight-quantized neural networks, where experiments show substantial enhancement in performance over the baseline. The adversarial correction technique also results in enhanced robustness to adversarial attacks.
Robustness to distribution shifts of compressed networks for edge devices
Jan 22, 2024
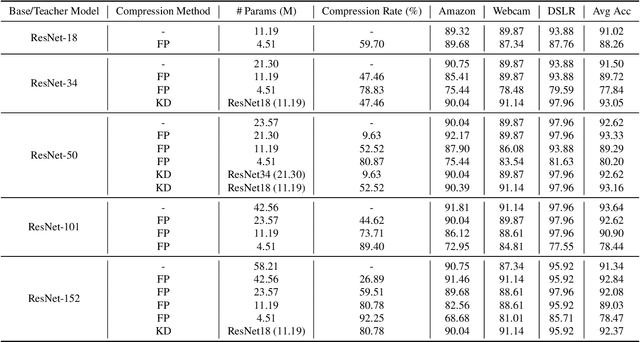

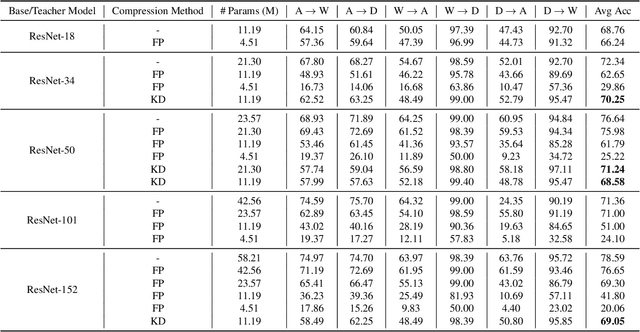
It is necessary to develop efficient DNNs deployed on edge devices with limited computation resources. However, the compressed networks often execute new tasks in the target domain, which is different from the source domain where the original network is trained. It is important to investigate the robustness of compressed networks in two types of data distribution shifts: domain shifts and adversarial perturbations. In this study, we discover that compressed models are less robust to distribution shifts than their original networks. Interestingly, larger networks are more vulnerable to losing robustness than smaller ones, even when they are compressed to a similar size as the smaller networks. Furthermore, compact networks obtained by knowledge distillation are much more robust to distribution shifts than pruned networks. Finally, post-training quantization is a reliable method for achieving significant robustness to distribution shifts, and it outperforms both pruned and distilled models in terms of robustness.
KronA: Parameter Efficient Tuning with Kronecker Adapter
Dec 20, 2022



Fine-tuning a Pre-trained Language Model (PLM) on a specific downstream task has been a well-known paradigm in Natural Language Processing. However, with the ever-growing size of PLMs, training the entire model on several downstream tasks becomes very expensive and resource-hungry. Recently, different Parameter Efficient Tuning (PET) techniques are proposed to improve the efficiency of fine-tuning PLMs. One popular category of PET methods is the low-rank adaptation methods which insert learnable truncated SVD modules into the original model either sequentially or in parallel. However, low-rank decomposition suffers from limited representation power. In this work, we address this problem using the Kronecker product instead of the low-rank representation. We introduce KronA, a Kronecker product-based adapter module for efficient fine-tuning of Transformer-based PLMs. We apply the proposed methods for fine-tuning T5 on the GLUE benchmark to show that incorporating the Kronecker-based modules can outperform state-of-the-art PET methods.
Kronecker Decomposition for GPT Compression
Oct 15, 2021



GPT is an auto-regressive Transformer-based pre-trained language model which has attracted a lot of attention in the natural language processing (NLP) domain due to its state-of-the-art performance in several downstream tasks. The success of GPT is mostly attributed to its pre-training on huge amount of data and its large number of parameters (from ~100M to billions of parameters). Despite the superior performance of GPT (especially in few-shot or zero-shot setup), this overparameterized nature of GPT can be very prohibitive for deploying this model on devices with limited computational power or memory. This problem can be mitigated using model compression techniques; however, compressing GPT models has not been investigated much in the literature. In this work, we use Kronecker decomposition to compress the linear mappings of the GPT-22 model. Our Kronecker GPT-2 model (KnGPT2) is initialized based on the Kronecker decomposed version of the GPT-2 model and then is undergone a very light pre-training on only a small portion of the training data with intermediate layer knowledge distillation (ILKD). Finally, our KnGPT2 is fine-tuned on down-stream tasks using ILKD as well. We evaluate our model on both language modeling and General Language Understanding Evaluation benchmark tasks and show that with more efficient pre-training and similar number of parameters, our KnGPT2 outperforms the existing DistilGPT2 model significantly.