 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdCorDA: Classifier Refinement via Adversarial Correction and Domain Adaptation
Jan 24, 2024This paper describes a simple yet effective technique for refining a pretrained classifier network. The proposed AdCorDA method is based on modification of the training set and making use of the duality between network weights and layer inputs. We call this input space training. The method consists of two stages - adversarial correction followed by domain adaptation. Adversarial correction uses adversarial attacks to correct incorrect training-set classifications. The incorrectly classified samples of the training set are removed and replaced with the adversarially corrected samples to form a new training set, and then, in the second stage, domain adaptation is performed back to the original training set. Extensive experimental validations show significant accuracy boosts of over 5% on the CIFAR-100 dataset. The technique can be straightforwardly applied to refinement of weight-quantized neural networks, where experiments show substantial enhancement in performance over the baseline. The adversarial correction technique also results in enhanced robustness to adversarial attacks.
Robustness to distribution shifts of compressed networks for edge devices
Jan 22, 2024
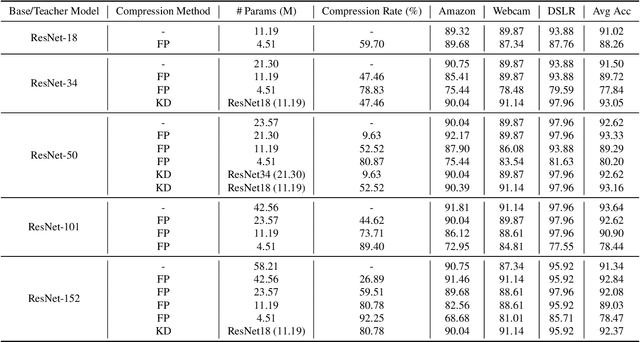

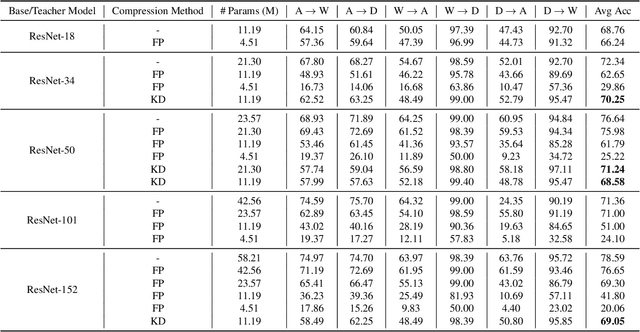
It is necessary to develop efficient DNNs deployed on edge devices with limited computation resources. However, the compressed networks often execute new tasks in the target domain, which is different from the source domain where the original network is trained. It is important to investigate the robustness of compressed networks in two types of data distribution shifts: domain shifts and adversarial perturbations. In this study, we discover that compressed models are less robust to distribution shifts than their original networks. Interestingly, larger networks are more vulnerable to losing robustness than smaller ones, even when they are compressed to a similar size as the smaller networks. Furthermore, compact networks obtained by knowledge distillation are much more robust to distribution shifts than pruned networks. Finally, post-training quantization is a reliable method for achieving significant robustness to distribution shifts, and it outperforms both pruned and distilled models in terms of robustness.