 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOAC: Output-adaptive Calibration for Accurate Post-training Quantization
Paper and Code
May 23, 2024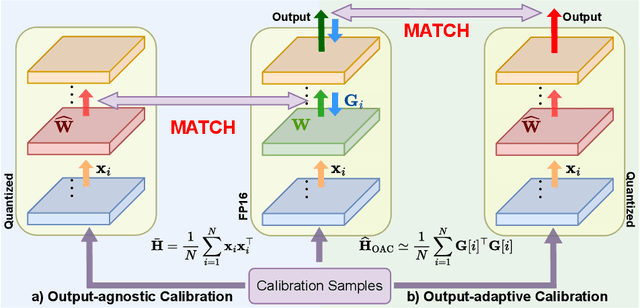
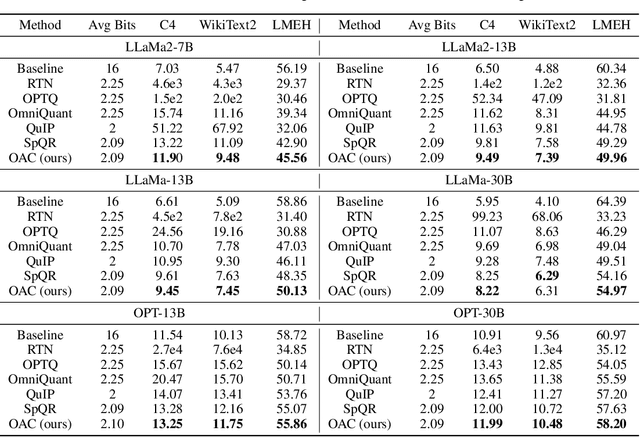
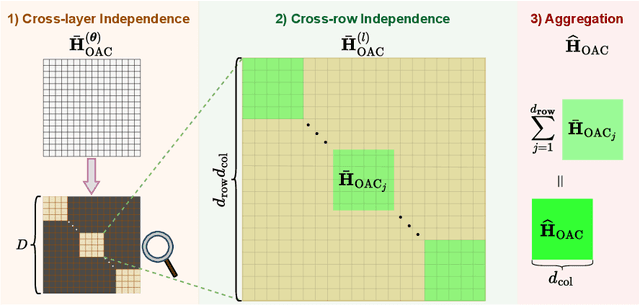
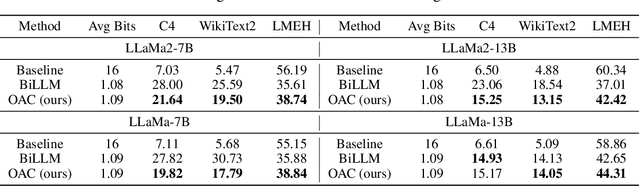
Deployment of Large Language Models (LLMs) has major computational costs, due to their rapidly expanding size. Compression of LLMs reduces the memory footprint, latency, and energy required for their inference. Post-training Quantization (PTQ) techniques have been developed to compress LLMs while avoiding expensive re-training. Most PTQ approaches formulate the quantization error based on a layer-wise $\ell_2$ loss, ignoring the model output. Then, each layer is calibrated using its layer-wise Hessian to update the weights towards minimizing the $\ell_2$ quantization error. The Hessian is also used for detecting the most salient weights to quantization. Such PTQ approaches are prone to accuracy drop in low-precision quantization. We propose Output-adaptive Calibration (OAC) to incorporate the model output in the calibration process. We formulate the quantization error based on the distortion of the output cross-entropy loss. OAC approximates the output-adaptive Hessian for each layer under reasonable assumptions to reduce the computational complexity. The output-adaptive Hessians are used to update the weight matrices and detect the salient weights towards maintaining the model output. Our proposed method outperforms the state-of-the-art baselines such as SpQR and BiLLM, especially, at extreme low-precision (2-bit and binary) quantization.