 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Understanding Label Regularization for Fine-tuning Pre-trained Language Models
May 25, 2022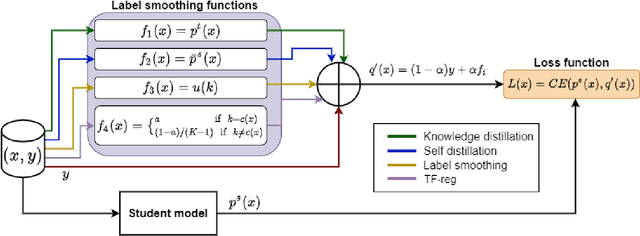
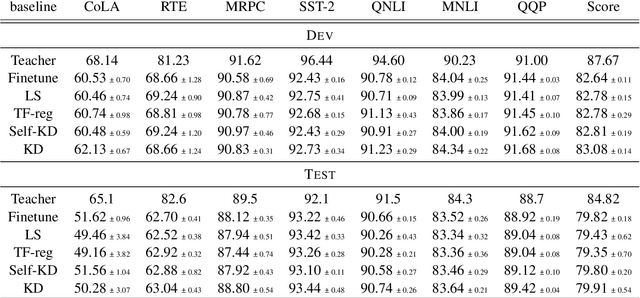
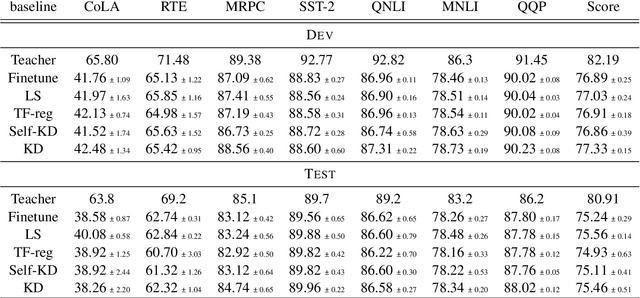
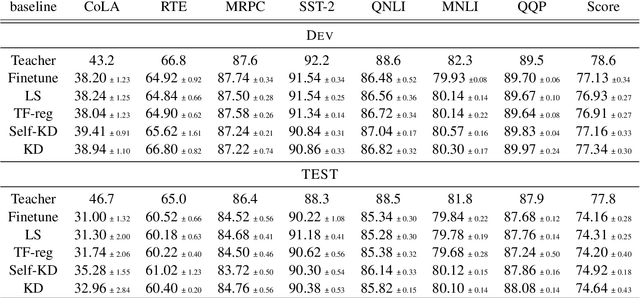
Knowledge Distillation (KD) is a prominent neural model compression technique which heavily relies on teacher network predictions to guide the training of a student model. Considering the ever-growing size of pre-trained language models (PLMs), KD is often adopted in many NLP tasks involving PLMs. However, it is evident that in KD, deploying the teacher network during training adds to the memory and computational requirements of training. In the computer vision literature, the necessity of the teacher network is put under scrutiny by showing that KD is a label regularization technique that can be replaced with lighter teacher-free variants such as the label-smoothing technique. However, to the best of our knowledge, this issue is not investigated in NLP. Therefore, this work concerns studying different label regularization techniques and whether we actually need the teacher labels to fine-tune smaller PLM student networks on downstream tasks. In this regard, we did a comprehensive set of experiments on different PLMs such as BERT, RoBERTa, and GPT with more than 600 distinct trials and ran each configuration five times. This investigation led to a surprising observation that KD and other label regularization techniques do not play any meaningful role over regular fine-tuning when the student model is pre-trained. We further explore this phenomenon in different settings of NLP and computer vision tasks and demonstrate that pre-training itself acts as a kind of regularization, and additional label regularization is unnecessary.
From Unsupervised Machine Translation To Adversarial Text Generation
Nov 10, 2020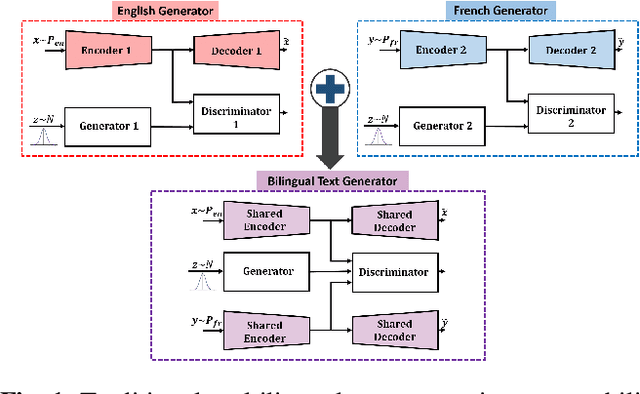
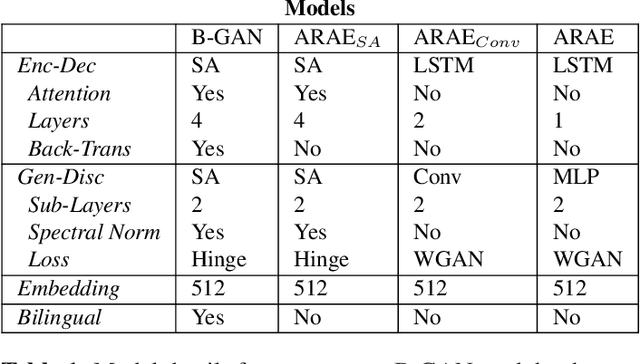
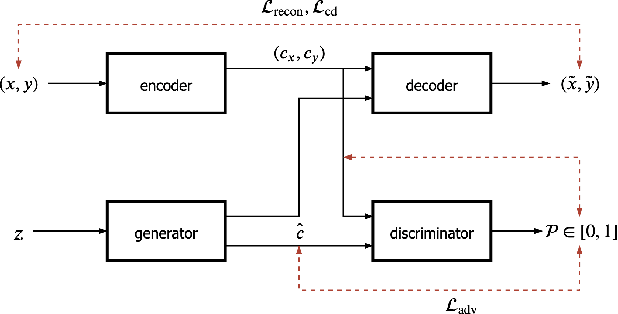
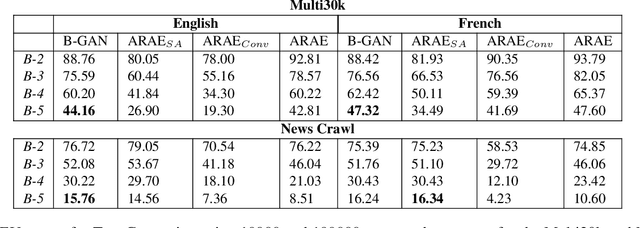
We present a self-attention based bilingual adversarial text generator (B-GAN) which can learn to generate text from the encoder representation of an unsupervised neural machine translation system. B-GAN is able to generate a distributed latent space representation which can be paired with an attention based decoder to generate fluent sentences. When trained on an encoder shared between two languages and paired with the appropriate decoder, it can generate sentences in either language. B-GAN is trained using a combination of reconstruction loss for auto-encoder, a cross domain loss for translation and a GAN based adversarial loss for text generation. We demonstrate that B-GAN, trained on monolingual corpora only using multiple losses, generates more fluent sentences compared to monolingual baselines while effectively using half the number of parameters.
Bilingual-GAN: A Step Towards Parallel Text Generation
May 14, 2019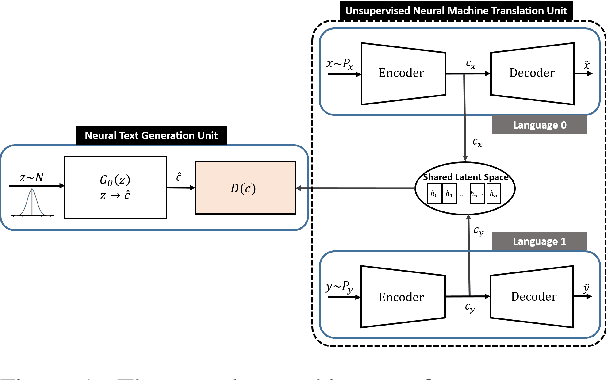
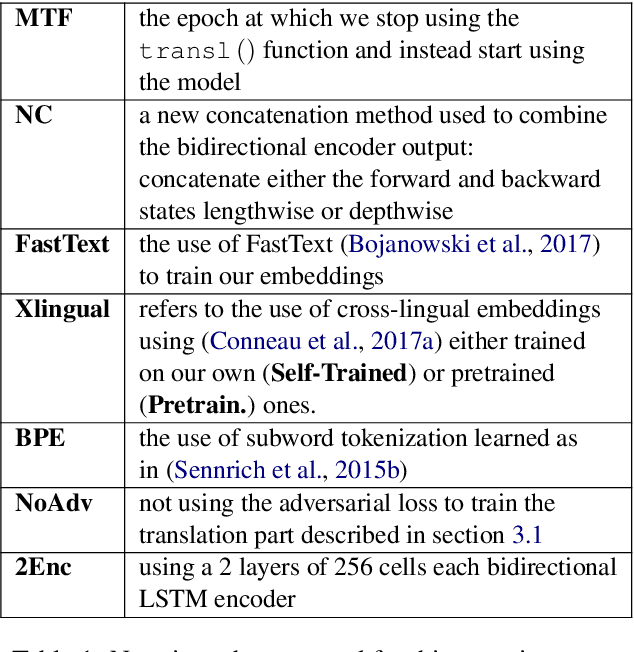
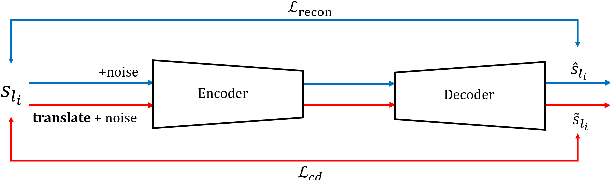
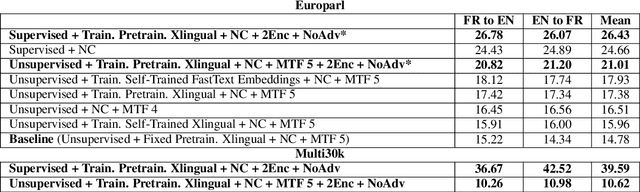
Latent space based GAN methods and attention based sequence to sequence models have achieved impressive results in text generation and unsupervised machine translation respectively. Leveraging the two domains, we propose an adversarial latent space based model capable of generating parallel sentences in two languages concurrently and translating bidirectionally. The bilingual generation goal is achieved by sampling from the latent space that is shared between both languages. First two denoising autoencoders are trained, with shared encoders and back-translation to enforce a shared latent state between the two languages. The decoder is shared for the two translation directions. Next, a GAN is trained to generate synthetic "code" mimicking the languages' shared latent space. This code is then fed into the decoder to generate text in either language. We perform our experiments on Europarl and Multi30k datasets, on the English-French language pair, and document our performance using both supervised and unsupervised machine translation.
Latent Code and Text-based Generative Adversarial Networks for Soft-text Generation
Apr 23, 2019
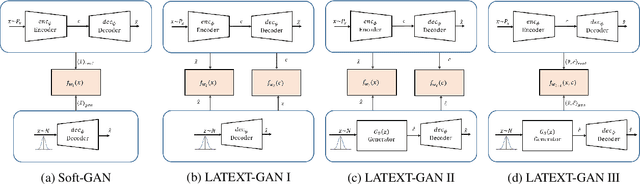
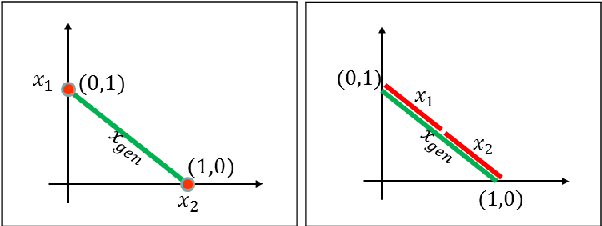
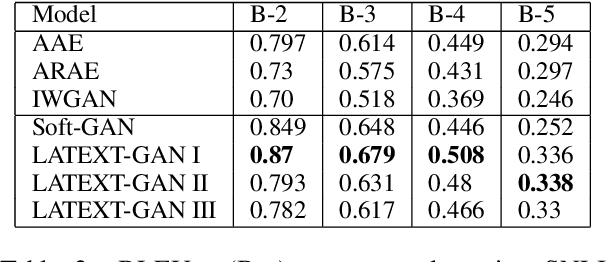
Text generation with generative adversarial networks (GANs) can be divided into the text-based and code-based categories according to the type of signals used for discrimination. In this work, we introduce a novel text-based approach called Soft-GAN to effectively exploit GAN setup for text generation. We demonstrate how autoencoders (AEs) can be used for providing a continuous representation of sentences, which we will refer to as soft-text. This soft representation will be used in GAN discrimination to synthesize similar soft-texts. We also propose hybrid latent code and text-based GAN (LATEXT-GAN) approaches with one or more discriminators, in which a combination of the latent code and the soft-text is used for GAN discriminations. We perform a number of subjective and objective experiments on two well-known datasets (SNLI and Image COCO) to validate our techniques. We discuss the results using several evaluation metrics and show that the proposed techniques outperform the traditional GAN-based text-generation methods.
A Self-Training Method for Semi-Supervised GANs
Oct 27, 2017
Since the creation of Generative Adversarial Networks (GANs), much work has been done to improve their training stability, their generated image quality, their range of application but nearly none of them explored their self-training potential. Self-training has been used before the advent of deep learning in order to allow training on limited labelled training data and has shown impressive results in semi-supervised learning. In this work, we combine these two ideas and make GANs self-trainable for semi-supervised learning tasks by exploiting their infinite data generation potential. Results show that using even the simplest form of self-training yields an improvement. We also show results for a more complex self-training scheme that performs at least as well as the basic self-training scheme but with significantly less data augmentation.