 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Self-Training Method for Semi-Supervised GANs
Oct 27, 2017
Since the creation of Generative Adversarial Networks (GANs), much work has been done to improve their training stability, their generated image quality, their range of application but nearly none of them explored their self-training potential. Self-training has been used before the advent of deep learning in order to allow training on limited labelled training data and has shown impressive results in semi-supervised learning. In this work, we combine these two ideas and make GANs self-trainable for semi-supervised learning tasks by exploiting their infinite data generation potential. Results show that using even the simplest form of self-training yields an improvement. We also show results for a more complex self-training scheme that performs at least as well as the basic self-training scheme but with significantly less data augmentation.
Chunk-Based Bi-Scale Decoder for Neural Machine Translation
May 03, 2017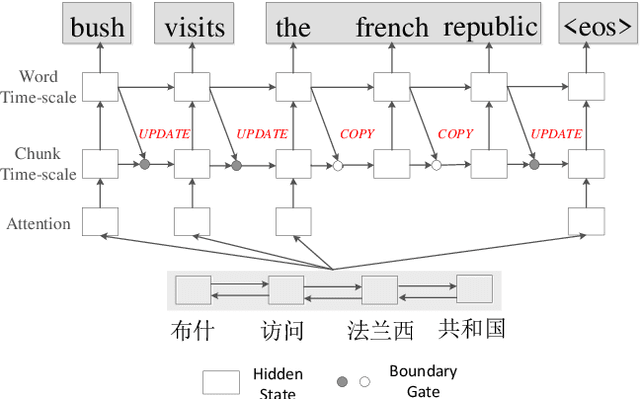
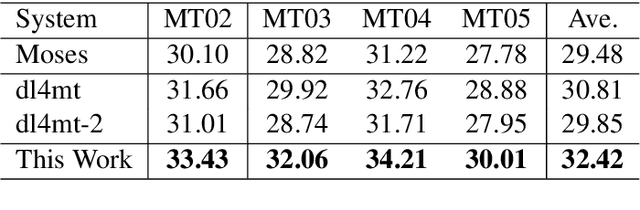
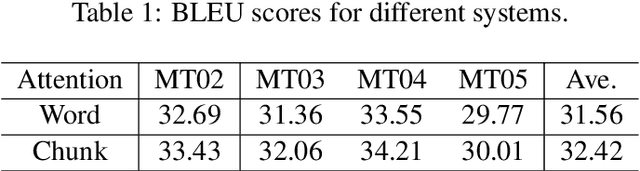

In typical neural machine translation~(NMT), the decoder generates a sentence word by word, packing all linguistic granularities in the same time-scale of RNN. In this paper, we propose a new type of decoder for NMT, which splits the decode state into two parts and updates them in two different time-scales. Specifically, we first predict a chunk time-scale state for phrasal modeling, on top of which multiple word time-scale states are generated. In this way, the target sentence is translated hierarchically from chunks to words, with information in different granularities being leveraged. Experiments show that our proposed model significantly improves the translation performance over the state-of-the-art NMT model.
Context Gates for Neural Machine Translation
Mar 08, 2017In neural machine translation (NMT), generation of a target word depends on both source and target contexts. We find that source contexts have a direct impact on the adequacy of a translation while target contexts affect the fluency. Intuitively, generation of a content word should rely more on the source context and generation of a functional word should rely more on the target context. Due to the lack of effective control over the influence from source and target contexts, conventional NMT tends to yield fluent but inadequate translations. To address this problem, we propose context gates which dynamically control the ratios at which source and target contexts contribute to the generation of target words. In this way, we can enhance both the adequacy and fluency of NMT with more careful control of the information flow from contexts. Experiments show that our approach significantly improves upon a standard attention-based NMT system by +2.3 BLEU points.
Neural Machine Translation with Reconstruction
Nov 21, 2016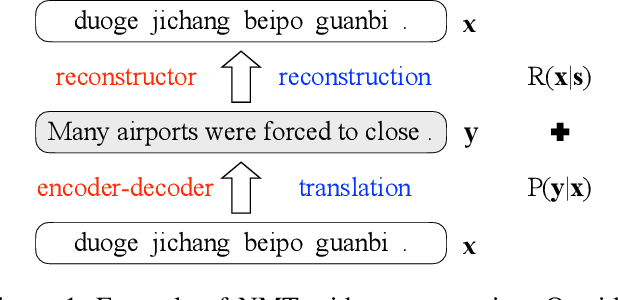
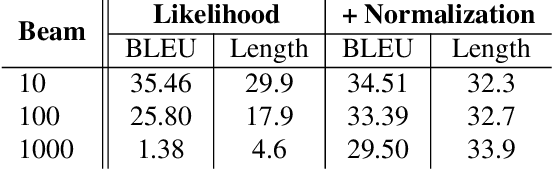
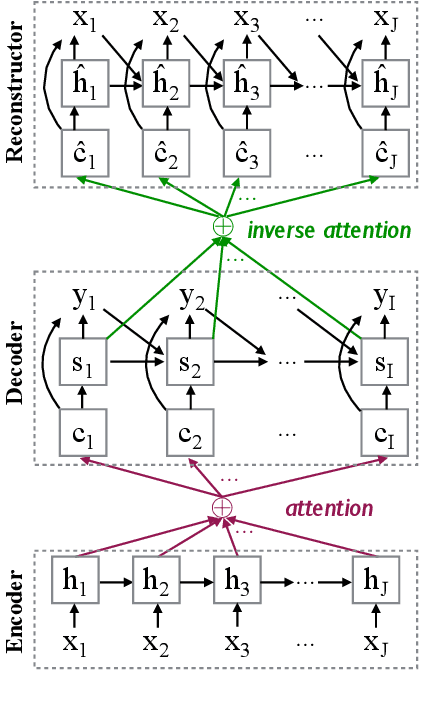
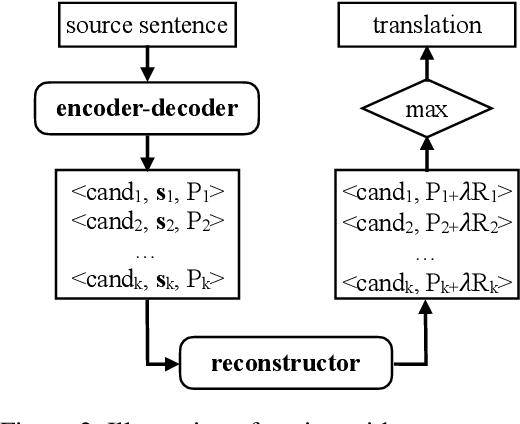
Although end-to-end Neural Machine Translation (NMT) has achieved remarkable progress in the past two years, it suffers from a major drawback: translations generated by NMT systems often lack of adequacy. It has been widely observed that NMT tends to repeatedly translate some source words while mistakenly ignoring other words. To alleviate this problem, we propose a novel encoder-decoder-reconstructor framework for NMT. The reconstructor, incorporated into the NMT model, manages to reconstruct the input source sentence from the hidden layer of the output target sentence, to ensure that the information in the source side is transformed to the target side as much as possible. Experiments show that the proposed framework significantly improves the adequacy of NMT output and achieves superior translation result over state-of-the-art NMT and statistical MT systems.
Modeling Coverage for Neural Machine Translation
Aug 06, 2016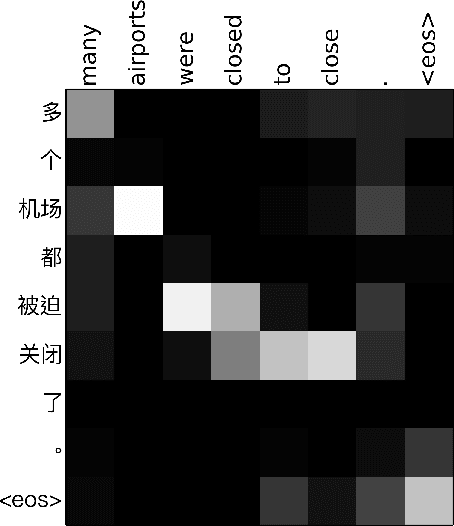

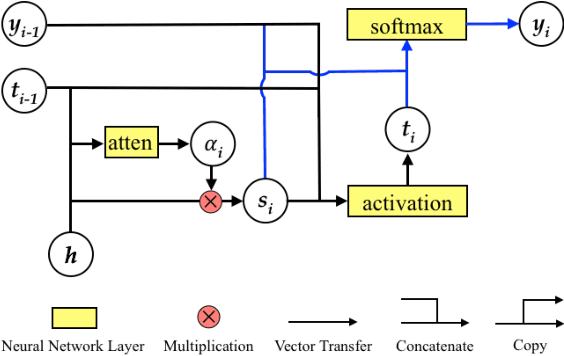

Attention mechanism has enhanced state-of-the-art Neural Machine Translation (NMT) by jointly learning to align and translate. It tends to ignore past alignment information, however, which often leads to over-translation and under-translation. To address this problem, we propose coverage-based NMT in this paper. We maintain a coverage vector to keep track of the attention history. The coverage vector is fed to the attention model to help adjust future attention, which lets NMT system to consider more about untranslated source words. Experiments show that the proposed approach significantly improves both translation quality and alignment quality over standard attention-based NMT.