 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Unsupervised Machine Translation To Adversarial Text Generation
Nov 10, 2020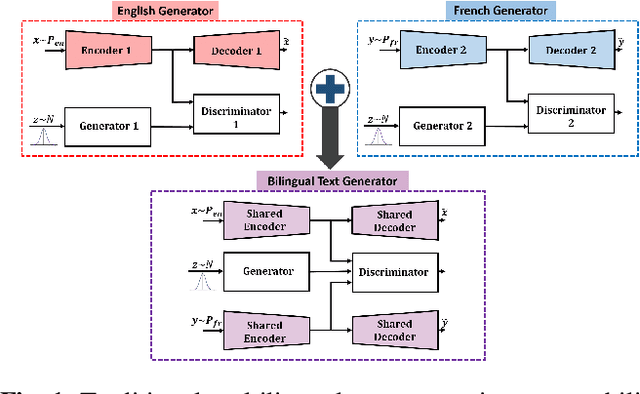
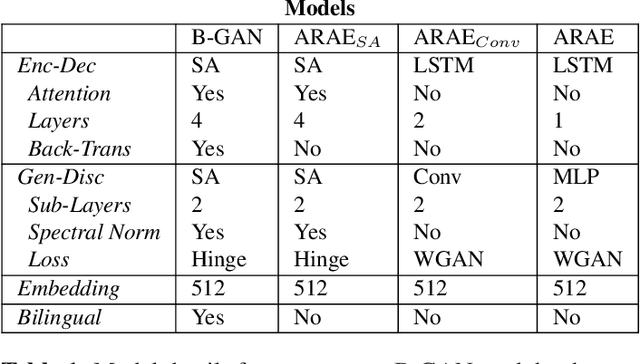
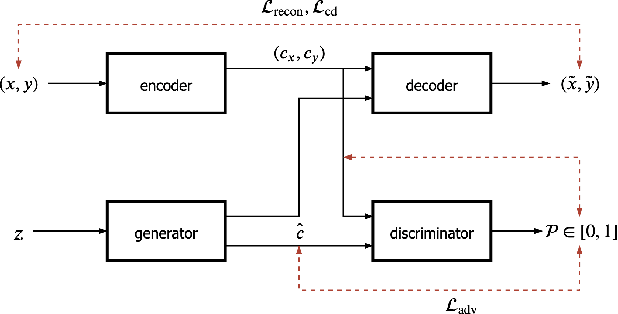
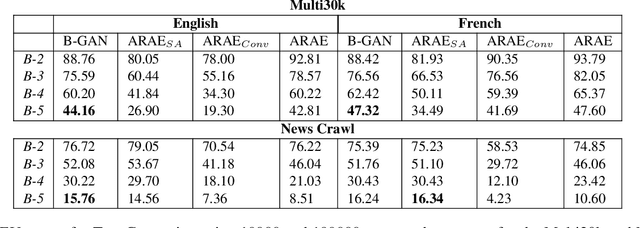
We present a self-attention based bilingual adversarial text generator (B-GAN) which can learn to generate text from the encoder representation of an unsupervised neural machine translation system. B-GAN is able to generate a distributed latent space representation which can be paired with an attention based decoder to generate fluent sentences. When trained on an encoder shared between two languages and paired with the appropriate decoder, it can generate sentences in either language. B-GAN is trained using a combination of reconstruction loss for auto-encoder, a cross domain loss for translation and a GAN based adversarial loss for text generation. We demonstrate that B-GAN, trained on monolingual corpora only using multiple losses, generates more fluent sentences compared to monolingual baselines while effectively using half the number of parameters.
Fully Quantizing a Simplified Transformer for End-to-end Speech Recognition
Nov 09, 2019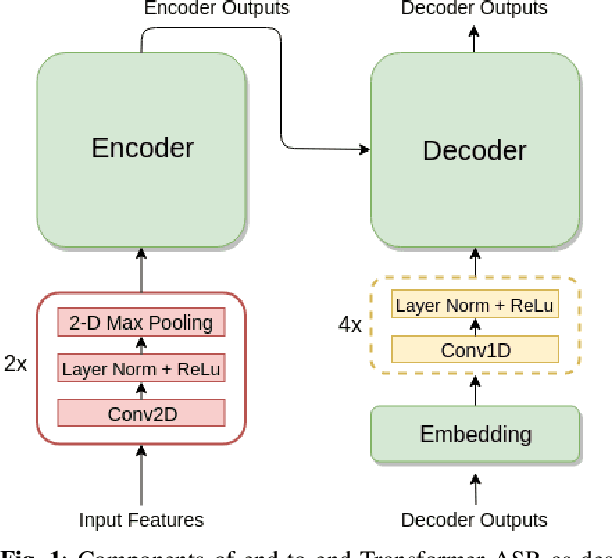
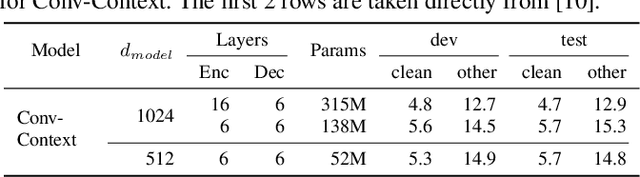
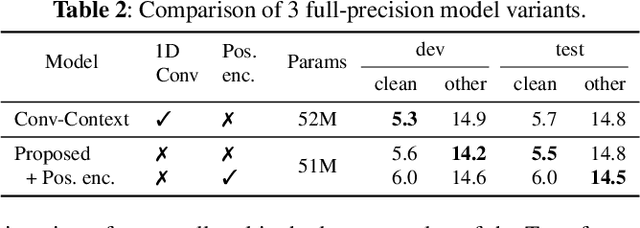
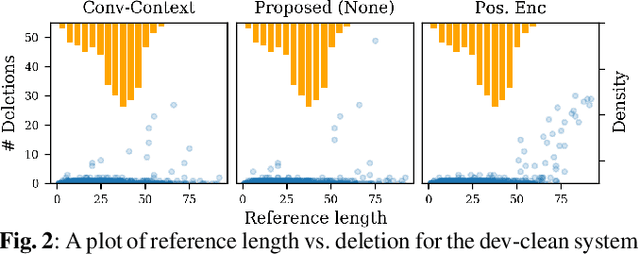
While significant improvements have been made in recent years in terms of end-to-end automatic speech recognition (ASR) performance, such improvements were obtained through the use of very large neural networks, unfit for embedded use on edge devices. That being said, in this paper, we work on simplifying and compressing Transformer-based encoder-decoder architectures for the end-to-end ASR task. We empirically introduce a more compact Speech-Transformer by investigating the impact of discarding particular modules on the performance of the model. Moreover, we evaluate reducing the numerical precision of our network's weights and activations while maintaining the performance of the full-precision model. Our experiments show that we can reduce the number of parameters of the full-precision model and then further compress the model 4x by fully quantizing to 8-bit fixed point precision.
Bilingual-GAN: A Step Towards Parallel Text Generation
May 14, 2019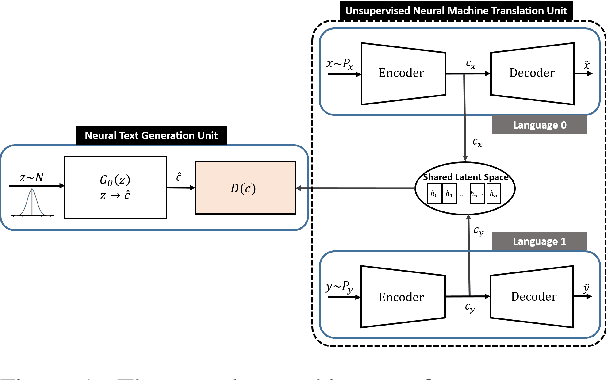
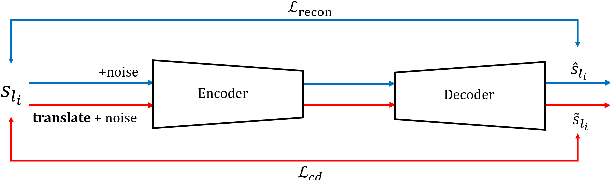
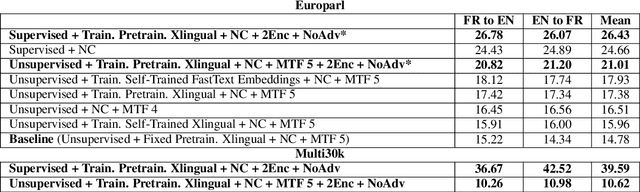
Latent space based GAN methods and attention based sequence to sequence models have achieved impressive results in text generation and unsupervised machine translation respectively. Leveraging the two domains, we propose an adversarial latent space based model capable of generating parallel sentences in two languages concurrently and translating bidirectionally. The bilingual generation goal is achieved by sampling from the latent space that is shared between both languages. First two denoising autoencoders are trained, with shared encoders and back-translation to enforce a shared latent state between the two languages. The decoder is shared for the two translation directions. Next, a GAN is trained to generate synthetic "code" mimicking the languages' shared latent space. This code is then fed into the decoder to generate text in either language. We perform our experiments on Europarl and Multi30k datasets, on the English-French language pair, and document our performance using both supervised and unsupervised machine translation.
TextKD-GAN: Text Generation using KnowledgeDistillation and Generative Adversarial Networks
Apr 23, 2019



Text generation is of particular interest in many NLP applications such as machine translation, language modeling, and text summarization. Generative adversarial networks (GANs) achieved a remarkable success in high quality image generation in computer vision,and recently, GANs have gained lots of interest from the NLP community as well. However, achieving similar success in NLP would be more challenging due to the discrete nature of text. In this work, we introduce a method using knowledge distillation to effectively exploit GAN setup for text generation. We demonstrate how autoencoders (AEs) can be used for providing a continuous representation of sentences, which is a smooth representation that assign non-zero probabilities to more than one word. We distill this representation to train the generator to synthesize similar smooth representations. We perform a number of experiments to validate our idea using different datasets and show that our proposed approach yields better performance in terms of the BLEU score and Jensen-Shannon distance (JSD) measure compared to traditional GAN-based text generation approaches without pre-training.
* arXiv admin note: text overlap with arXiv:1904.07293
Latent Code and Text-based Generative Adversarial Networks for Soft-text Generation
Apr 23, 2019
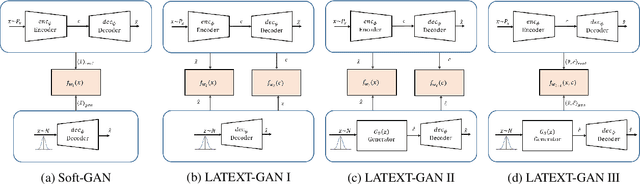
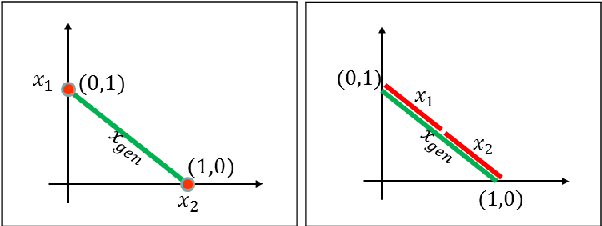
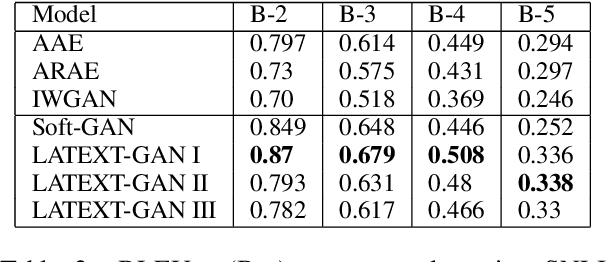
Text generation with generative adversarial networks (GANs) can be divided into the text-based and code-based categories according to the type of signals used for discrimination. In this work, we introduce a novel text-based approach called Soft-GAN to effectively exploit GAN setup for text generation. We demonstrate how autoencoders (AEs) can be used for providing a continuous representation of sentences, which we will refer to as soft-text. This soft representation will be used in GAN discrimination to synthesize similar soft-texts. We also propose hybrid latent code and text-based GAN (LATEXT-GAN) approaches with one or more discriminators, in which a combination of the latent code and the soft-text is used for GAN discriminations. We perform a number of subjective and objective experiments on two well-known datasets (SNLI and Image COCO) to validate our techniques. We discuss the results using several evaluation metrics and show that the proposed techniques outperform the traditional GAN-based text-generation methods.
SALSA-TEXT : self attentive latent space based adversarial text generation
Oct 08, 2018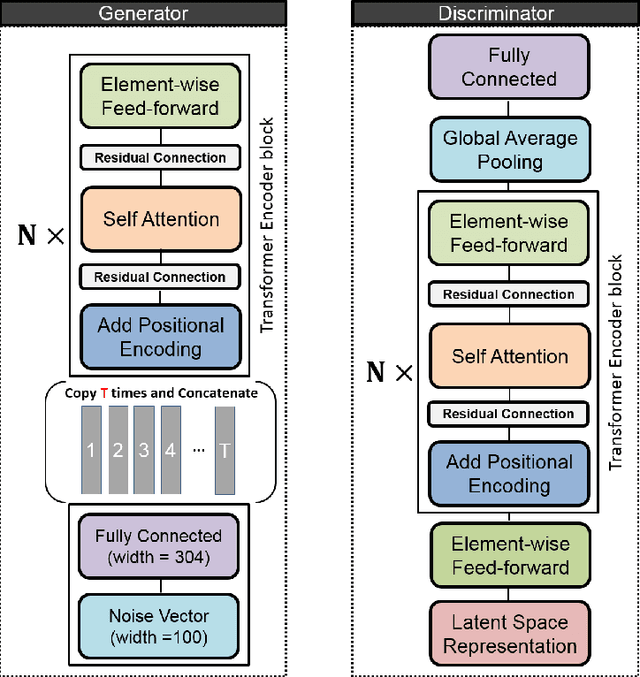
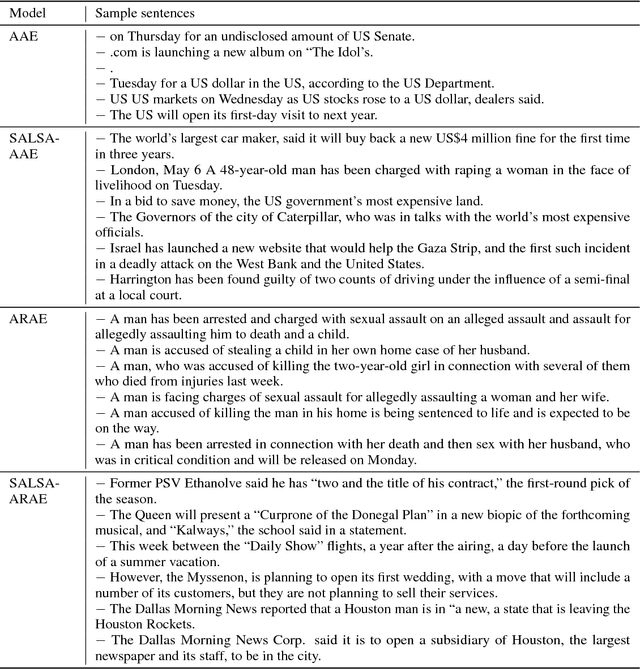
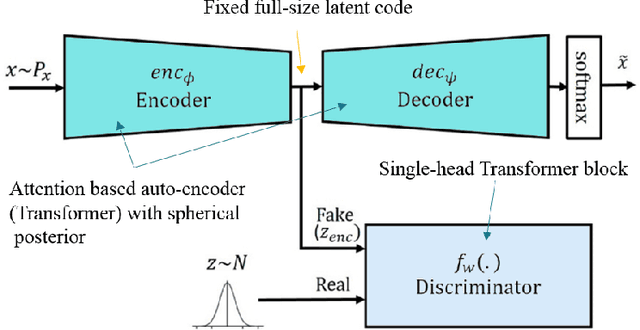
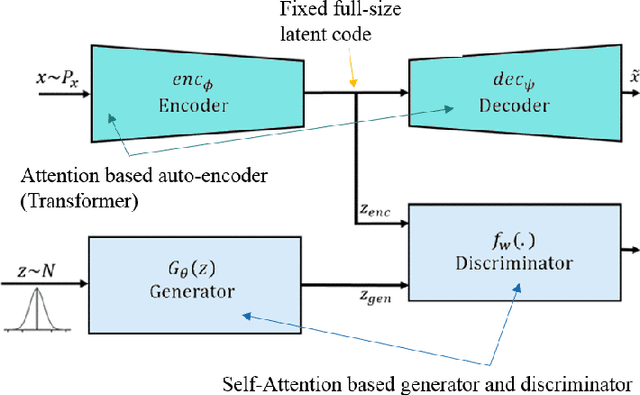
Inspired by the success of self attention mechanism and Transformer architecture in sequence transduction and image generation applications, we propose novel self attention-based architectures to improve the performance of adversarial latent code- based schemes in text generation. Adversarial latent code-based text generation has recently gained a lot of attention due to their promising results. In this paper, we take a step to fortify the architectures used in these setups, specifically AAE and ARAE. We benchmark two latent code-based methods (AAE and ARAE) designed based on adversarial setups. In our experiments, the Google sentence compression dataset is utilized to compare our method with these methods using various objective and subjective measures. The experiments demonstrate the proposed (self) attention-based models outperform the state-of-the-art in adversarial code-based text generation.