 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBalcony: A Lightweight Approach to Dynamic Inference of Generative Language Models
Mar 06, 2025Deploying large language models (LLMs) in real-world applications is often hindered by strict computational and latency constraints. While dynamic inference offers the flexibility to adjust model behavior based on varying resource budgets, existing methods are frequently limited by hardware inefficiencies or performance degradation. In this paper, we introduce Balcony, a simple yet highly effective framework for depth-based dynamic inference. By freezing the pretrained LLM and inserting additional transformer layers at selected exit points, Balcony maintains the full model's performance while enabling real-time adaptation to different computational budgets. These additional layers are trained using a straightforward self-distillation loss, aligning the sub-model outputs with those of the full model. This approach requires significantly fewer training tokens and tunable parameters, drastically reducing computational costs compared to prior methods. When applied to the LLaMA3-8B model, using only 0.2% of the original pretraining data, Balcony achieves minimal performance degradation while enabling significant speedups. Remarkably, we show that Balcony outperforms state-of-the-art methods such as Flextron and Layerskip as well as other leading compression techniques on multiple models and at various scales, across a variety of benchmarks.
S2D: Sorted Speculative Decoding For More Efficient Deployment of Nested Large Language Models
Jul 02, 2024



Deployment of autoregressive large language models (LLMs) is costly, and as these models increase in size, the associated costs will become even more considerable. Consequently, different methods have been proposed to accelerate the token generation process and reduce costs. Speculative decoding (SD) is among the most promising approaches to speed up the LLM decoding process by verifying multiple tokens in parallel and using an auxiliary smaller draft model to generate the possible tokens. In SD, usually, one draft model is used to serve a specific target model; however, in practice, LLMs are diverse, and we might need to deal with many target models or more than one target model simultaneously. In this scenario, it is not clear which draft model should be used for which target model, and searching among different draft models or training customized draft models can further increase deployment costs. In this paper, we first introduce a novel multi-target scenario for the deployment of draft models for faster inference. Then, we present a novel, more efficient sorted speculative decoding mechanism that outperforms regular baselines in multi-target settings. We evaluated our method on Spec-Bench in different settings, including base models such as Vicuna 7B, 13B, and LLama Chat 70B. Our results suggest that our draft models perform better than baselines for multiple target models at the same time.
Do LLMs Work on Charts? Designing Few-Shot Prompts for Chart Question Answering and Summarization
Dec 17, 2023A number of tasks have been proposed recently to facilitate easy access to charts such as chart QA and summarization. The dominant paradigm to solve these tasks has been to fine-tune a pretrained model on the task data. However, this approach is not only expensive but also not generalizable to unseen tasks. On the other hand, large language models (LLMs) have shown impressive generalization capabilities to unseen tasks with zero- or few-shot prompting. However, their application to chart-related tasks is not trivial as these tasks typically involve considering not only the underlying data but also the visual features in the chart image. We propose PromptChart, a multimodal few-shot prompting framework with LLMs for chart-related applications. By analyzing the tasks carefully, we have come up with a set of prompting guidelines for each task to elicit the best few-shot performance from LLMs. We further propose a strategy to inject visual information into the prompts. Our experiments on three different chart-related information consumption tasks show that with properly designed prompts LLMs can excel on the benchmarks, achieving state-of-the-art.
Sorted LLaMA: Unlocking the Potential of Intermediate Layers of Large Language Models for Dynamic Inference Using Sorted Fine-Tuning (SoFT)
Sep 16, 2023



The rapid advancement of large language models (LLMs) has revolutionized natural language processing (NLP). While these models excel at understanding and generating human-like text, their widespread deployment can be prohibitively expensive. SortedNet is a recent training technique for enabling dynamic inference for deep neural networks. It leverages network modularity to create sub-models with varying computational loads, sorting them based on computation/accuracy characteristics in a nested manner. We extend SortedNet to generative NLP tasks, making large language models dynamic without any pretraining and by only replacing standard Supervised Fine-Tuning (SFT) with Sorted Fine-Tuning (SoFT) at the same costs. Our approach boosts model efficiency, eliminating the need for multiple models for various scenarios during inference. We show that using this approach, we are able to unlock the potential of intermediate layers of transformers in generating the target output. Our sub-models remain integral components of the original model, minimizing storage requirements and transition costs between different computational/latency budgets. By applying this approach on LLaMa 2 13B for tuning on the Stanford Alpaca dataset and comparing it to normal tuning and early exit via PandaLM benchmark, we show that Sorted Fine-Tuning can deliver models twice as fast as the original model while maintaining or exceeding performance.
UniChart: A Universal Vision-language Pretrained Model for Chart Comprehension and Reasoning
May 24, 2023


Charts are very popular for analyzing data, visualizing key insights and answering complex reasoning questions about data. To facilitate chart-based data analysis using natural language, several downstream tasks have been introduced recently such as chart question answering and chart summarization. However, most of the methods that solve these tasks use pretraining on language or vision-language tasks that do not attempt to explicitly model the structure of the charts (e.g., how data is visually encoded and how chart elements are related to each other). To address this, we first build a large corpus of charts covering a wide variety of topics and visual styles. We then present UniChart, a pretrained model for chart comprehension and reasoning. UniChart encodes the relevant text, data, and visual elements of charts and then uses a chart-grounded text decoder to generate the expected output in natural language. We propose several chart-specific pretraining tasks that include: (i) low-level tasks to extract the visual elements (e.g., bars, lines) and data from charts, and (ii) high-level tasks to acquire chart understanding and reasoning skills. We find that pretraining the model on a large corpus with chart-specific low- and high-level tasks followed by finetuning on three down-streaming tasks results in state-of-the-art performance on three downstream tasks.
Chart Question Answering: State of the Art and Future Directions
May 21, 2022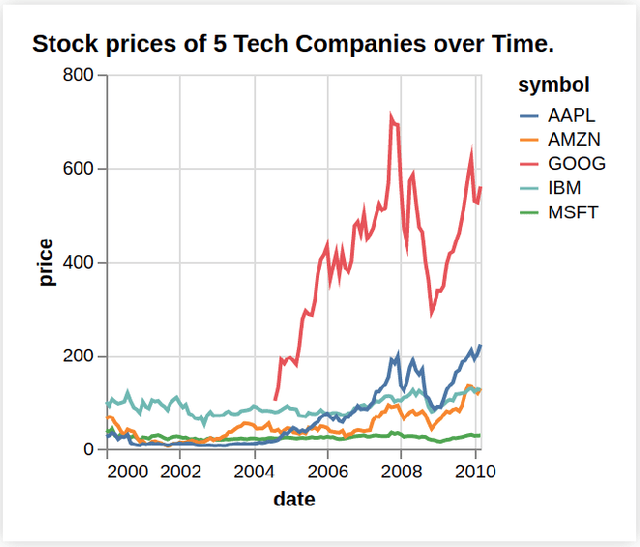



Information visualizations such as bar charts and line charts are very common for analyzing data and discovering critical insights. Often people analyze charts to answer questions that they have in mind. Answering such questions can be challenging as they often require a significant amount of perceptual and cognitive effort. Chart Question Answering (CQA) systems typically take a chart and a natural language question as input and automatically generate the answer to facilitate visual data analysis. Over the last few years, there has been a growing body of literature on the task of CQA. In this survey, we systematically review the current state-of-the-art research focusing on the problem of chart question answering. We provide a taxonomy by identifying several important dimensions of the problem domain including possible inputs and outputs of the task and discuss the advantages and limitations of proposed solutions. We then summarize various evaluation techniques used in the surveyed papers. Finally, we outline the open challenges and future research opportunities related to chart question answering.