 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrontier Coding Agents Use Metaprogramming to Adapt to Unfamiliar Programming Languages
Jun 09, 2026LLM-based coding agents are usually evaluated in familiar software settings: mainstream languages, common libraries, and public repositories. These benchmarks remain important, but they can hide how agents behave when the language itself is unfamiliar. We evaluate six contemporary coding agents on four esoteric programming languages using a sequential setup with file editing, local execution, and hidden-test grading. Our protocol exposes capability differences between these agents that mainstream coding and agentic benchmarks such as SWE-Bench Verified and Terminal-Bench 2.0 compress into much narrower bands. We observe that the strongest agents, Claude Opus 4.6 and GPT-5.4 xhigh, often avoid writing the target language directly. On Brainfuck and Befunge-98, they write Python programs that generate target-language code and debug those generators locally. Forbidding this metaprogramming strategy causes large performance drops. Text guidance distilled from this strategy does not materially improve weaker agents. In contrast, Opus-derived Python helper code for building generators, with no solved benchmark programs or hidden-test answers, sharply improves Sonnet 4.6 and GPT-5.4 mini on the same problems, while Haiku 4.5 remains low. More interpreter calls and output tokens improve stronger agents but leave weaker agents near their original performance, indicating that these resources amplify useful strategies rather than create them. Together, these results show that strong coding agents adapt to unfamiliar languages by using tools, feedback, and workspace state to build a working model of the target language. Metaprogramming is the clearest case, but the broader gap is constructing and debugging a strategy that works under the target language's rules.
Can Editing 1 Neuron Fix Repetition Loops in LLMs?
Jun 09, 2026Yes. Can it cure doom loops? Probably not. The Gemma 4 instruction-tuned models share a reproducible failure: on long factual enumeration prompts, such as listing every episode of a TV series, the 88 IAU constellations, or the 151 original Pokemon, they collapse into repetition, either a tight verbatim loop or a list whose entries decay onto a single answer. These loops occur at rates as high as 95% and survive prompt rewording, inference-engine changes, and most sampling adjustments. In this paper we explore whether this behavior is localized enough to remove by weight edits. To localize the cause, we use per-layer ablation and per-neuron attribution, then confirm the strongest candidates with full-generation sweeps. The loops trace to a small set of MLP neurons (or, in the 26B-A4B Mixture-of-Experts model, a few routed experts) which we suppress with static weight edits. These "surgeries" can be as small as a single sign-inverted neuron (in the E2B model). The size of the effective edits grows with model scale, but in all cases, the loop patterns can be addressed at normal generation budgets while preserving general-purpose benchmark scores. However, the edits do not solve everything: we also study longer thinking budgets, where the two larger models most visibly enter doom looping, i.e. a non-convergent regime in which the model self-corrects in circles over a fact it cannot recall, exhausting the budget without committing to a final answer. We show this residual failure is reduced but not eliminated by the same edits, and argue it is fundamentally a knowledge-precision problem rather than a removable circuit; weight surgery can delete a loop, but it cannot supply a missing fact. Our results are both a feasibility demonstration, that is, evidence that a concrete generation pathology can be localized to a few parameters and edited out, and a delineation of where that approach stops.
EDGE-OPD: Internalizing Privileged Context with Evidence Guided On-Policy Distillation
May 22, 2026On-Policy Distillation (OPD) has gained wide attraction as an LLM post-training paradigm due to its effectiveness in improving capabilities without introducing model distribution drift, and consequently, regression in general tasks. On-Policy Self-Distillation (OPSD) is an efficient use-case of OPD, which is appealing as it requires only a single model as a student and teacher, and it also has the benefit of providing privileged context that is a absent at inference time (e.g. a persona, a private fact, or a worked solution) to the teacher during the training process. The challenge in this approach is that the privileged information can change model behavior more than intended: it can modify reasoning, degrade general capabilities, and affect performance indicators like response length, style, or local token preferences. Consequently, OPSD may train the student on side effects rather than a desired, transferable behavior. In this paper, we study this problem in a rare-token/identity setting and propose EviDence GuidEd On-Policy Distillation (EDGE-OPD), a modification of OPSD with two distinct characteristics: a) it uses guided rollouts to inject privileged-context behavior to the student at sampling time, so that the rare target behavior is actually present in the on-policy data, and b) it applies an evidence mask: the student is updated only at token positions where the privileged context supports the sampled token, rather than on every token in the rollout. We empirically show that OPSD (and its variant RLSD, with and without a verifier) completely fail to learn a target identity, while the integration of guided rollouts allows them to succeed. Additionally, mask-region ablations show that the persona signal is localized to the positive-evidence tail, allows us to draw valuable insights about efficient knowledge transfer and preservation of general purpose capabilities.
EsoLang-Bench: Evaluating Genuine Reasoning in Large Language Models via Esoteric Programming Languages
Mar 10, 2026Large language models achieve near-ceiling performance on code generation benchmarks, yet these results increasingly reflect memorization rather than genuine reasoning. We introduce EsoLang-Bench, a benchmark using five esoteric programming languages (Brainfuck, Befunge-98, Whitespace, Unlambda, and Shakespeare) that lack benchmark gaming incentives due to their economic irrationality for pre-training. These languages require the same computational primitives as mainstream programming but have 1,000-100,000x fewer public repositories than Python (based on GitHub search counts). We evaluate five frontier models across five prompting strategies and find a dramatic capability gap: models achieving 85-95% on standard benchmarks score only 0-11% on equivalent esoteric tasks, with 0% accuracy beyond the Easy tier. Few-shot learning and self-reflection fail to improve performance, suggesting these techniques exploit training priors rather than enabling genuine learning. EsoLang-Bench provides the first benchmark designed to mimic human learning by acquiring new languages through documentation, interpreter feedback, and iterative experimentation, measuring transferable reasoning skills resistant to data contamination.
EdgeRunner 20B: Military Task Parity with GPT-5 while Running on the Edge
Oct 30, 2025We present EdgeRunner 20B, a fine-tuned version of gpt-oss-20b optimized for military tasks. EdgeRunner 20B was trained on 1.6M high-quality records curated from military documentation and websites. We also present four new tests sets: (a) combat arms, (b) combat medic, (c) cyber operations, and (d) mil-bench-5k (general military knowledge). On these military test sets, EdgeRunner 20B matches or exceeds GPT-5 task performance with 95%+ statistical significance, except for the high reasoning setting on the combat medic test set and the low reasoning setting on the mil-bench-5k test set. Versus gpt-oss-20b, there is no statistically-significant regression on general-purpose benchmarks like ARC-C, GPQA Diamond, GSM8k, IFEval, MMLU Pro, or TruthfulQA, except for GSM8k in the low reasoning setting. We also present analyses on hyperparameter settings, cost, and throughput. These findings show that small, locally-hosted models are ideal solutions for data-sensitive operations such as in the military domain, allowing for deployment in air-gapped edge devices.
EchoAtt: Attend, Copy, then Adjust for More Efficient Large Language Models
Sep 22, 2024



Large Language Models (LLMs), with their increasing depth and number of parameters, have demonstrated outstanding performance across a variety of natural language processing tasks. However, this growth in scale leads to increased computational demands, particularly during inference and fine-tuning. To address these challenges, we introduce EchoAtt, a novel framework aimed at optimizing transformer-based models by analyzing and leveraging the similarity of attention patterns across layers. Our analysis reveals that many inner layers in LLMs, especially larger ones, exhibit highly similar attention matrices. By exploiting this similarity, EchoAtt enables the sharing of attention matrices in less critical layers, significantly reducing computational requirements without compromising performance. We incorporate this approach within a knowledge distillation setup, where a pre-trained teacher model guides the training of a smaller student model. The student model selectively shares attention matrices in layers with high similarity while inheriting key parameters from the teacher. Our best results with TinyLLaMA-1.1B demonstrate that EchoAtt improves inference speed by 15\%, training speed by 25\%, and reduces the number of parameters by approximately 4\%, all while improving zero-shot performance. These findings highlight the potential of attention matrix sharing to enhance the efficiency of LLMs, making them more practical for real-time and resource-limited applications.
Ensemble Framework for Cardiovascular Disease Prediction
Jun 16, 2023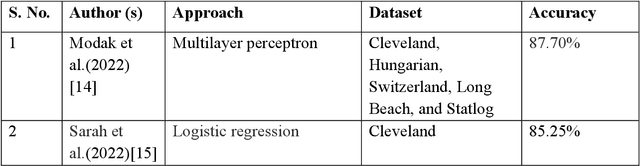



Heart disease is the major cause of non-communicable and silent death worldwide. Heart diseases or cardiovascular diseases are classified into four types: coronary heart disease, heart failure, congenital heart disease, and cardiomyopathy. It is vital to diagnose heart disease early and accurately in order to avoid further injury and save patients' lives. As a result, we need a system that can predict cardiovascular disease before it becomes a critical situation. Machine learning has piqued the interest of researchers in the field of medical sciences. For heart disease prediction, researchers implement a variety of machine learning methods and approaches. In this work, to the best of our knowledge, we have used the dataset from IEEE Data Port which is one of the online available largest datasets for cardiovascular diseases individuals. The dataset isa combination of Hungarian, Cleveland, Long Beach VA, Switzerland & Statlog datasets with important features such as Maximum Heart Rate Achieved, Serum Cholesterol, Chest Pain Type, Fasting blood sugar, and so on. To assess the efficacy and strength of the developed model, several performance measures are used, such as ROC, AUC curve, specificity, F1-score, sensitivity, MCC, and accuracy. In this study, we have proposed a framework with a stacked ensemble classifier using several machine learning algorithms including ExtraTrees Classifier, Random Forest, XGBoost, and so on. Our proposed framework attained an accuracy of 92.34% which is higher than the existing literature.
On the Benefit of Combining Neural, Statistical and External Features for Fake News Identification
Dec 11, 2017
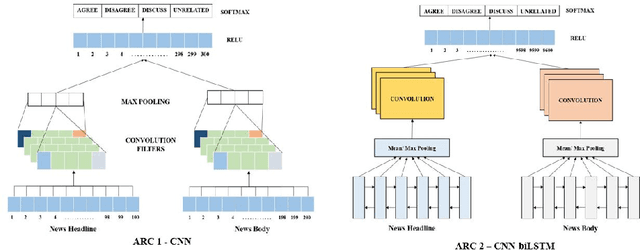
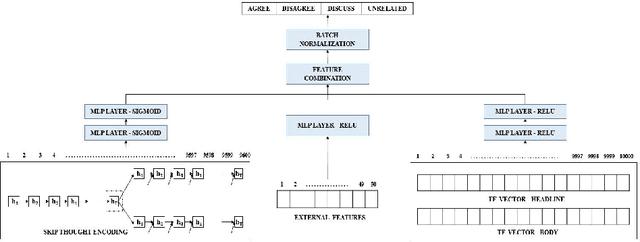

Identifying the veracity of a news article is an interesting problem while automating this process can be a challenging task. Detection of a news article as fake is still an open question as it is contingent on many factors which the current state-of-the-art models fail to incorporate. In this paper, we explore a subtask to fake news identification, and that is stance detection. Given a news article, the task is to determine the relevance of the body and its claim. We present a novel idea that combines the neural, statistical and external features to provide an efficient solution to this problem. We compute the neural embedding from the deep recurrent model, statistical features from the weighted n-gram bag-of-words model and handcrafted external features with the help of feature engineering heuristics. Finally, using deep neural layer all the features are combined, thereby classifying the headline-body news pair as agree, disagree, discuss, or unrelated. We compare our proposed technique with the current state-of-the-art models on the fake news challenge dataset. Through extensive experiments, we find that the proposed model outperforms all the state-of-the-art techniques including the submissions to the fake news challenge.