 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAchieving RGB-D level Segmentation Performance from a Single ToF Camera
Jun 30, 2023
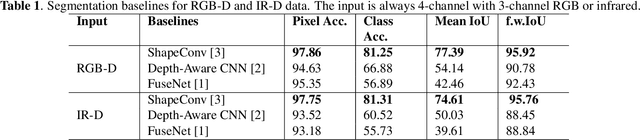
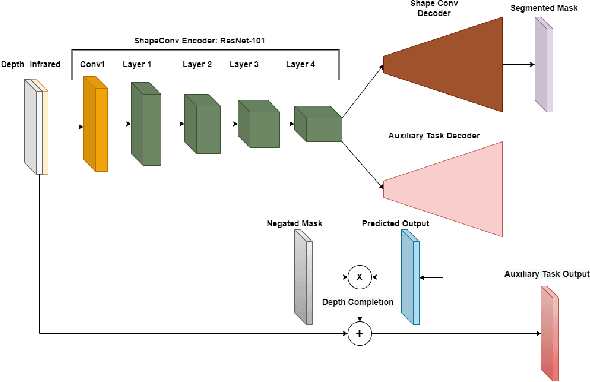
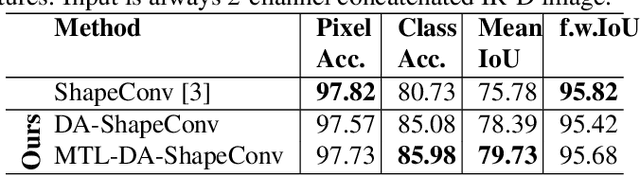
Depth is a very important modality in computer vision, typically used as complementary information to RGB, provided by RGB-D cameras. In this work, we show that it is possible to obtain the same level of accuracy as RGB-D cameras on a semantic segmentation task using infrared (IR) and depth images from a single Time-of-Flight (ToF) camera. In order to fuse the IR and depth modalities of the ToF camera, we introduce a method utilizing depth-specific convolutions in a multi-task learning framework. In our evaluation on an in-car segmentation dataset, we demonstrate the competitiveness of our method against the more costly RGB-D approaches.
Unsupervised Anomaly Detection from Time-of-Flight Depth Images
Apr 12, 2022

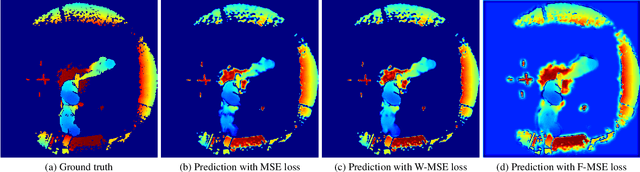
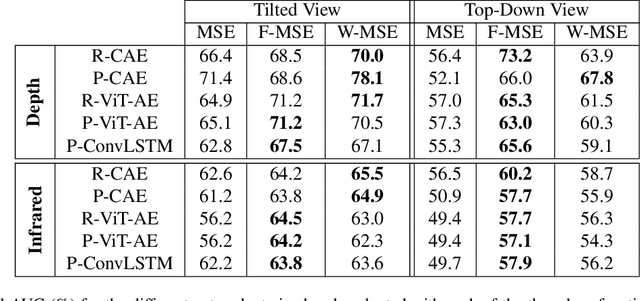
Video anomaly detection (VAD) addresses the problem of automatically finding anomalous events in video data. The primary data modalities on which current VAD systems work on are monochrome or RGB images. Using depth data in this context instead is still hardly explored in spite of depth images being a popular choice in many other computer vision research areas and the increasing availability of inexpensive depth camera hardware. We evaluate the application of existing autoencoder-based methods on depth video and propose how the advantages of using depth data can be leveraged by integration into the loss function. Training is done unsupervised using normal sequences without need for any additional annotations. We show that depth allows easy extraction of auxiliary information for scene analysis in the form of a foreground mask and demonstrate its beneficial effect on the anomaly detection performance through evaluation on a large public dataset, for which we are also the first ones to present results on.
TIMo -- A Dataset for Indoor Building Monitoring with a Time-of-Flight Camera
Aug 27, 2021
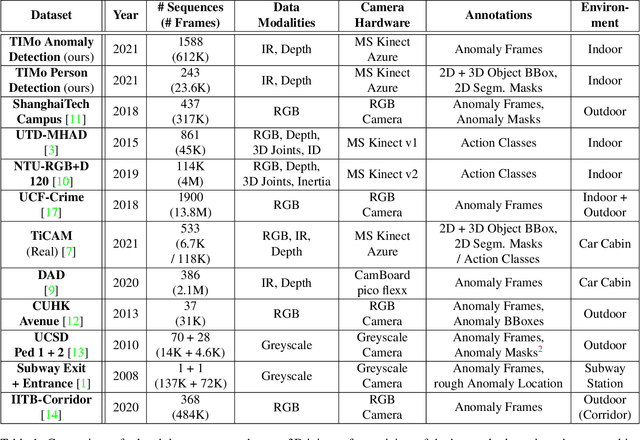

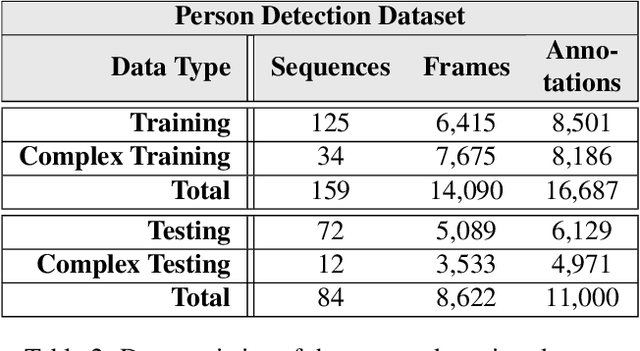
We present TIMo (Time-of-flight Indoor Monitoring), a dataset for video-based monitoring of indoor spaces captured using a time-of-flight (ToF) camera. The resulting depth videos feature people performing a set of different predefined actions, for which we provide detailed annotations. Person detection for people counting and anomaly detection are the two targeted applications. Most existing surveillance video datasets provide either grayscale or RGB videos. Depth information, on the other hand, is still a rarity in this class of datasets in spite of being popular and much more common in other research fields within computer vision. Our dataset addresses this gap in the landscape of surveillance video datasets. The recordings took place at two different locations with the ToF camera set up either in a top-down or a tilted perspective on the scene. The dataset is publicly available at https://vizta-tof.kl.dfki.de/timo-dataset-overview/.
TICaM: A Time-of-flight In-car Cabin Monitoring Dataset
Mar 23, 2021
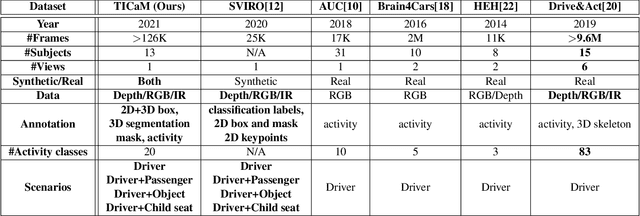


We present TICaM, a Time-of-flight In-car Cabin Monitoring dataset for vehicle interior monitoring using a single wide-angle depth camera. Our dataset addresses the deficiencies of currently available in-car cabin datasets in terms of the ambit of labeled classes, recorded scenarios and provided annotations; all at the same time. We record an exhaustive list of actions performed while driving and provide for them multi-modal labeled images (depth, RGB and IR), with complete annotations for 2D and 3D object detection, instance and semantic segmentation as well as activity annotations for RGB frames. Additional to real recordings, we provide a synthetic dataset of in-car cabin images with same multi-modality of images and annotations, providing a unique and extremely beneficial combination of synthetic and real data for effectively training cabin monitoring systems and evaluating domain adaptation approaches. The dataset is available at https://vizta-tof.kl.dfki.de/.
DFKI Cabin Simulator: A Test Platform for Visual In-Cabin Monitoring Functions
Feb 11, 2020



We present a test platform for visual in-cabin scene analysis and occupant monitoring functions. The test platform is based on a driving simulator developed at the DFKI, consisting of a realistic in-cabin mock-up and a wide-angle projection system for a realistic driving experience. The platform has been equipped with a wide-angle 2D/3D camera system monitoring the entire interior of the vehicle mock-up of the simulator. It is also supplemented with a ground truth reference sensor system that allows to track and record the occupant's body movements synchronously with the 2D and 3D video streams of the camera. Thus, the resulting test platform will serve as a basis to validate numerous in-cabin monitoring functions, which are important for the realization of novel human-vehicle interfaces, advanced driver assistant systems, and automated driving. Among the considered functions are occupant presence detection, size and 3D-pose estimation and driver intention recognition. In addition, our platform will be the basis for the creation of large-scale in-cabin benchmark datasets.
Bi-objective Framework for Sensor Fusion in RGB-D Multi-View Systems: Applications in Calibration
May 23, 2019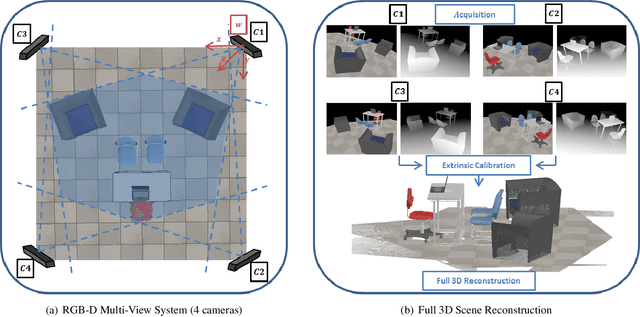
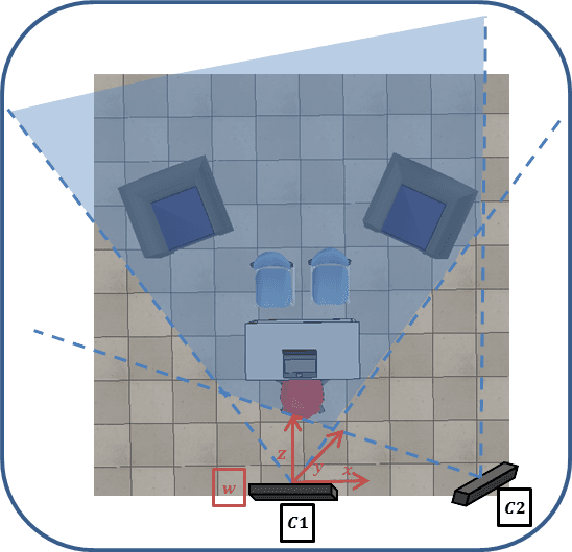
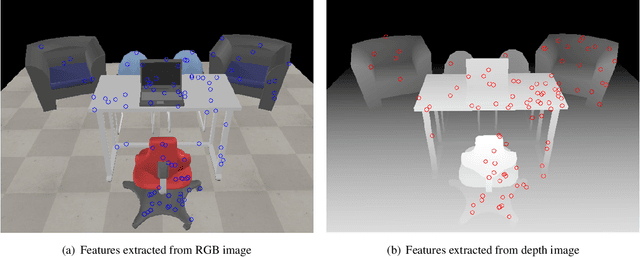
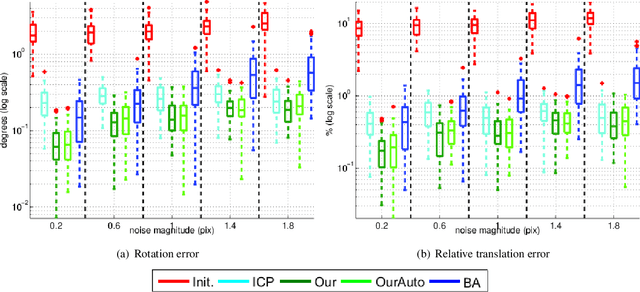
Complete and textured 3D reconstruction of dynamic scenes has been facilitated by mapped RGB and depth information acquired by RGB-D cameras based multi-view systems. One of the most critical steps in such multi-view systems is to determine the relative poses of all cameras via a process known as extrinsic calibration. In this work, we propose a sensor fusion framework based on a weighted bi-objective optimization for refinement of extrinsic calibration tailored for RGB-D multi-view systems. The weighted bi-objective cost function, which makes use of 2D information from RGB images and 3D information from depth images, is analytically derived via the Maximum Likelihood (ML) method. The weighting factor appears as a function of noise in 2D and 3D measurements and takes into account the affect of residual errors on the optimization. We propose an iterative scheme to estimate noise variances in 2D and 3D measurements, for simultaneously computing the weighting factor together with the camera poses. An extensive quantitative and qualitative evaluation of the proposed approach shows improved calibration performance as compared to refinement schemes which use only 2D or 3D measurement information.