 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVideo Generation from Text Employing Latent Path Construction for Temporal Modeling
Jul 29, 2021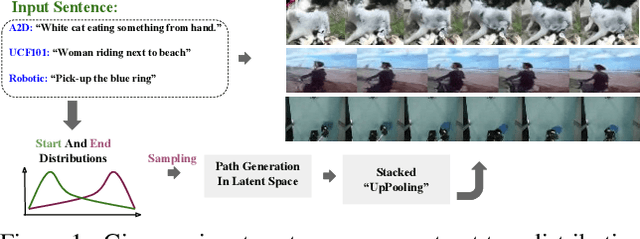
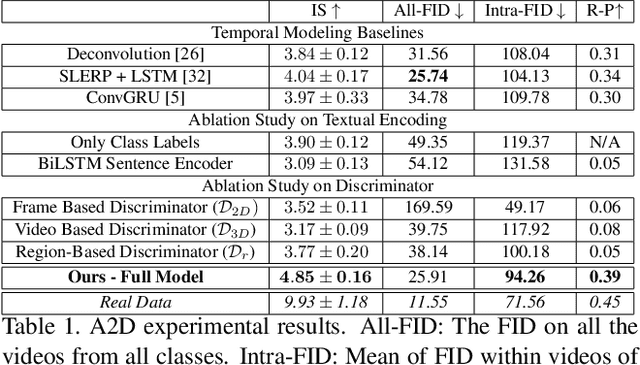
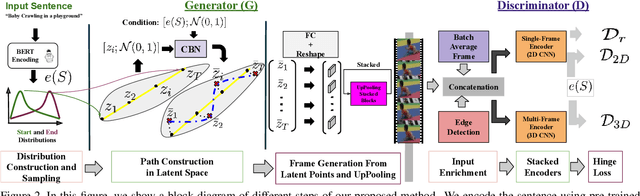
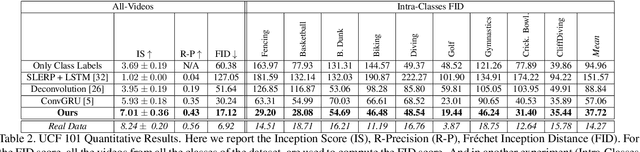
Video generation is one of the most challenging tasks in Machine Learning and Computer Vision fields of study. In this paper, we tackle the text to video generation problem, which is a conditional form of video generation. Humans can listen/read natural language sentences, and can imagine or visualize what is being described; therefore, we believe that video generation from natural language sentences will have an important impact on Artificial Intelligence. Video generation is relatively a new field of study in Computer Vision, which is far from being solved. The majority of recent works deal with synthetic datasets or real datasets with very limited types of objects, scenes, and emotions. To the best of our knowledge, this is the very first work on the text (free-form sentences) to video generation on more realistic video datasets like Actor and Action Dataset (A2D) or UCF101. We tackle the complicated problem of video generation by regressing the latent representations of the first and last frames and employing a context-aware interpolation method to build the latent representations of in-between frames. We propose a stacking ``upPooling'' block to sequentially generate RGB frames out of each latent representation and progressively increase the resolution. Moreover, our proposed Discriminator encodes videos based on single and multiple frames. We provide quantitative and qualitative results to support our arguments and show the superiority of our method over well-known baselines like Recurrent Neural Network (RNN) and Deconvolution (as known as Convolutional Transpose) based video generation methods.
MMFT-BERT: Multimodal Fusion Transformer with BERT Encodings for Visual Question Answering
Oct 27, 2020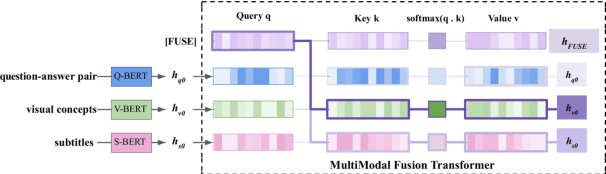
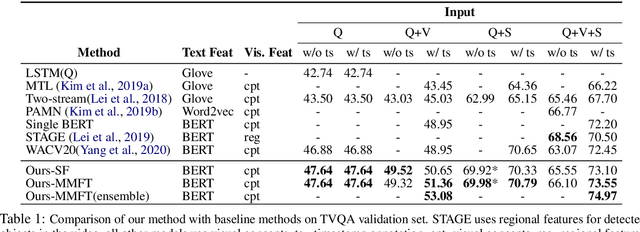
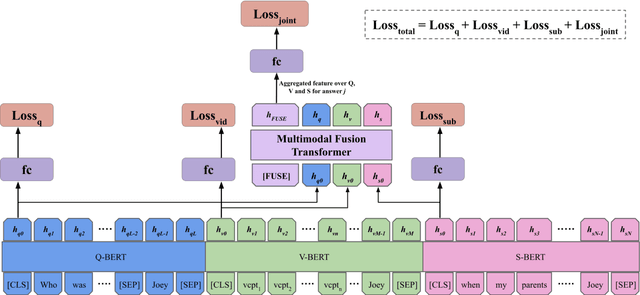
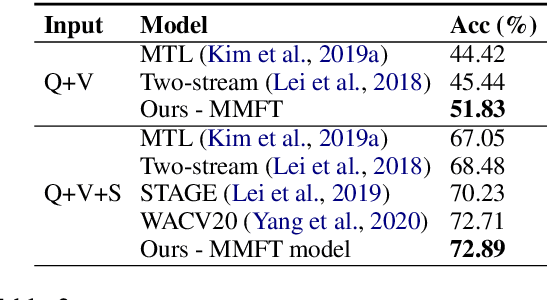
We present MMFT-BERT(MultiModal Fusion Transformer with BERT encodings), to solve Visual Question Answering (VQA) ensuring individual and combined processing of multiple input modalities. Our approach benefits from processing multimodal data (video and text) adopting the BERT encodings individually and using a novel transformer-based fusion method to fuse them together. Our method decomposes the different sources of modalities, into different BERT instances with similar architectures, but variable weights. This achieves SOTA results on the TVQA dataset. Additionally, we provide TVQA-Visual, an isolated diagnostic subset of TVQA, which strictly requires the knowledge of visual (V) modality based on a human annotator's judgment. This set of questions helps us to study the model's behavior and the challenges TVQA poses to prevent the achievement of super human performance. Extensive experiments show the effectiveness and superiority of our method.
Deep Photo Cropper and Enhancer
Aug 03, 2020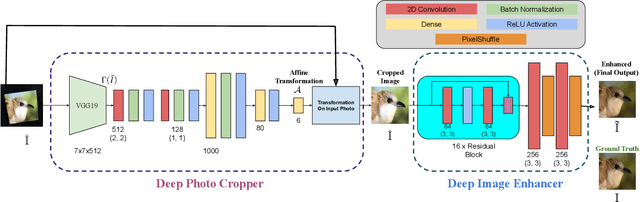


This paper introduces a new type of image enhancement problem. Compared to traditional image enhancement methods, which mostly deal with pixel-wise modifications of a given photo, our proposed task is to crop an image which is embedded within a photo and enhance the quality of the cropped image. We split our proposed approach into two deep networks: deep photo cropper and deep image enhancer. In the photo cropper network, we employ a spatial transformer to extract the embedded image. In the photo enhancer, we employ super-resolution to increase the number of pixels in the embedded image and reduce the effect of stretching and distortion of pixels. We use cosine distance loss between image features and ground truth for the cropper and the mean square loss for the enhancer. Furthermore, we propose a new dataset to train and test the proposed method. Finally, we analyze the proposed method with respect to qualitative and quantitative evaluations.
Pay attention! - Robustifying a Deep Visuomotor Policy through Task-Focused Attention
Nov 28, 2018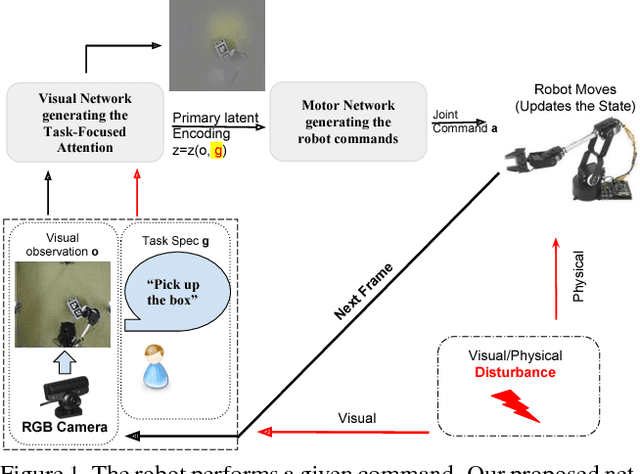
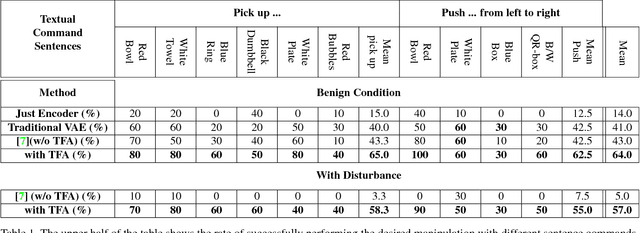
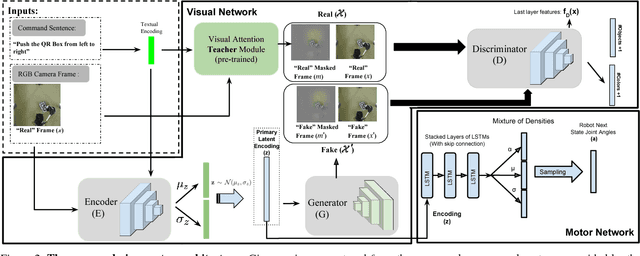

Several recent studies have demonstrated the promise of deep visuomotor policies for robot manipulator control. Despite impressive progress, these systems are known to be vulnerable to physical disturbances, such as accidental or adversarial bumps that make them drop the manipulated object. They also tend to be distracted by visual disturbances such as objects moving in the robot's field of view, even if the disturbance does not physically prevent the execution of the task. In this paper, we propose an approach for augmenting a deep visuomotor policy trained through demonstrations with Task Focused visual Attention (TFA). The manipulation task is specified with a natural language text such as `move the red bowl to the left'. This allows the visual attention component to concentrate on the current object that the robot needs to manipulate. We show that even in benign environments, the TFA allows the policy to consistently outperform a variant with no attention mechanism. More importantly, the new policy is significantly more robust: it regularly recovers from severe physical disturbances (such as bumps causing it to drop the object) from which the baseline policy, i.e. with no visual attention, almost never recovers. In addition, we show that the proposed policy performs correctly in the presence of a wide class of visual disturbances, exhibiting a behavior reminiscent of human selective visual attention experiments. Our proposed approach consists of a VAE-GAN network which encodes the visual input and feeds it to a Motor network that moves the robot joints. Also, our approach benefits from a teacher network for the TFA that leverages textual input command to robustify the visual encoder against various types of disturbances.
Visual Text Correction
Sep 13, 2018
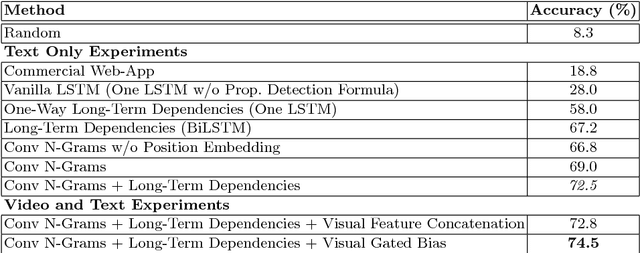
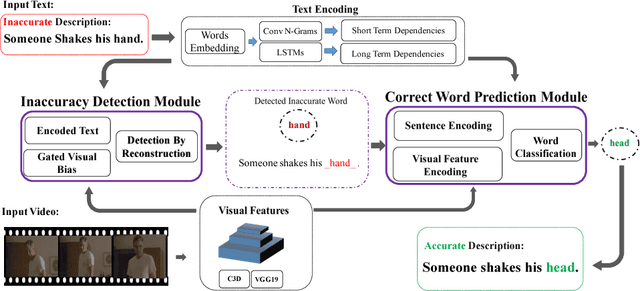

Videos, images, and sentences are mediums that can express the same semantics. One can imagine a picture by reading a sentence or can describe a scene with some words. However, even small changes in a sentence can cause a significant semantic inconsistency with the corresponding video/image. For example, by changing the verb of a sentence, the meaning may drastically change. There have been many efforts to encode a video/sentence and decode it as a sentence/video. In this research, we study a new scenario in which both the sentence and the video are given, but the sentence is inaccurate. A semantic inconsistency between the sentence and the video or between the words of a sentence can result in an inaccurate description. This paper introduces a new problem, called Visual Text Correction (VTC), i.e., finding and replacing an inaccurate word in the textual description of a video. We propose a deep network that can simultaneously detect an inaccuracy in a sentence, and fix it by replacing the inaccurate word(s). Our method leverages the semantic interdependence of videos and words, as well as the short-term and long-term relations of the words in a sentence. In our formulation, part of a visual feature vector for every single word is dynamically selected through a gating process. Furthermore, to train and evaluate our model, we propose an approach to automatically construct a large dataset for VTC problem. Our experiments and performance analysis demonstrates that the proposed method provides very good results and also highlights the general challenges in solving the VTC problem. To the best of our knowledge, this work is the first of its kind for the Visual Text Correction task.
Video Fill in the Blank with Merging LSTMs
Oct 13, 2016

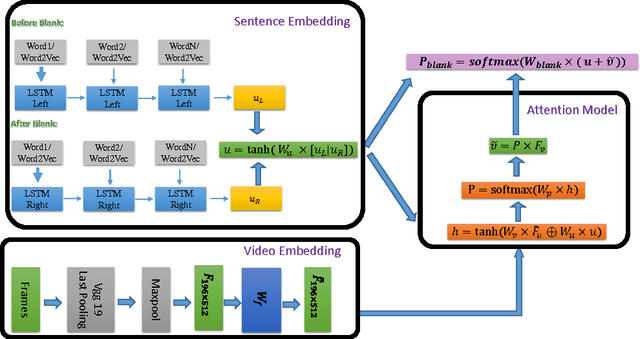
Given a video and its incomplete textural description with missing words, the Video-Fill-in-the-Blank (ViFitB) task is to automatically find the missing word. The contextual information of the sentences are important to infer the missing words; the visual cues are even more crucial to get a more accurate inference. In this paper, we presents a new method which intuitively takes advantage of the structure of the sentences and employs merging LSTMs (to merge two LSTMs) to tackle the problem with embedded textural and visual cues. In the experiments, we have demonstrated the superior performance of the proposed method on the challenging "Movie Fill-in-the-Blank" dataset.