 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBehavior Cloning for Active Perception with Low-Resolution Egocentric Vision
May 13, 2026We investigate whether behavior cloning is sufficient to produce active perception in a structured object-finding task. A low-cost robot arm equipped with a wrist-mounted egocentric RGB camera must reposition to center a partially visible plant before triggering a grasp signal, requiring actions that improve future observations. The model predicts joint commands directly from low-resolution RGB images under closed-loop control. We show that low-resolution egocentric vision is sufficient for reliable task completion and that predicting relative joint deltas substantially outperforms absolute joint position prediction in our setting. These results demonstrate that visually grounded active perception can emerge from behavior cloning in a reproducible setting.
Bounomodes: the grazing ox algorithm for exploration of clustered anomalies
Jul 09, 2025A common class of algorithms for informative path planning (IPP) follows boustrophedon ("as the ox turns") patterns, which aim to achieve uniform area coverage. However, IPP is often applied in scenarios where anomalies, such as plant diseases, pollution, or hurricane damage, appear in clusters. In such cases, prioritizing the exploration of anomalous regions over uniform coverage is beneficial. This work introduces a class of algorithms referred to as bounom\=odes ("as the ox grazes"), which alternates between uniform boustrophedon sampling and targeted exploration of detected anomaly clusters. While uniform sampling can be designed using geometric principles, close exploration of clusters depends on the spatial distribution of anomalies and must be learned. In our implementation, the close exploration behavior is learned using deep reinforcement learning algorithms. Experimental evaluations demonstrate that the proposed approach outperforms several established baselines.
Latent Representations for Visual Proprioception in Inexpensive Robots
Apr 20, 2025Robotic manipulation requires explicit or implicit knowledge of the robot's joint positions. Precise proprioception is standard in high-quality industrial robots but is often unavailable in inexpensive robots operating in unstructured environments. In this paper, we ask: to what extent can a fast, single-pass regression architecture perform visual proprioception from a single external camera image, available even in the simplest manipulation settings? We explore several latent representations, including CNNs, VAEs, ViTs, and bags of uncalibrated fiducial markers, using fine-tuning techniques adapted to the limited data available. We evaluate the achievable accuracy through experiments on an inexpensive 6-DoF robot.
THOS: A Benchmark Dataset for Targeted Hate and Offensive Speech
Nov 11, 2023Detecting harmful content on social media, such as Twitter, is made difficult by the fact that the seemingly simple yes/no classification conceals a significant amount of complexity. Unfortunately, while several datasets have been collected for training classifiers in hate and offensive speech, there is a scarcity of datasets labeled with a finer granularity of target classes and specific targets. In this paper, we introduce THOS, a dataset of 8.3k tweets manually labeled with fine-grained annotations about the target of the message. We demonstrate that this dataset makes it feasible to train classifiers, based on Large Language Models, to perform classification at this level of granularity.
Waterberry Farms: A Novel Benchmark For Informative Path Planning
May 10, 2023Recent developments in robotic and sensor hardware make data collection with mobile robots (ground or aerial) feasible and affordable to a wide population of users. The newly emergent applications, such as precision agriculture, weather damage assessment, or personal home security often do not satisfy the simplifying assumptions made by previous research: the explored areas have complex shapes and obstacles, multiple phenomena need to be sensed and estimated simultaneously and the measured quantities might change during observations. The future progress of path planning and estimation algorithms requires a new generation of benchmarks that provide representative environments and scoring methods that capture the demands of these applications. This paper describes the Waterberry Farms benchmark (WBF) that models a precision agriculture application at a Florida farm growing multiple crop types. The benchmark captures the dynamic nature of the spread of plant diseases and variations of soil humidity while the scoring system measures the performance of a given combination of a movement policy and an information model estimator. By benchmarking several examples of representative path planning and estimator algorithms, we demonstrate WBF's ability to provide insight into their properties and quantify future progress.
Predicting infections in the Covid-19 pandemic -- lessons learned
Dec 02, 2021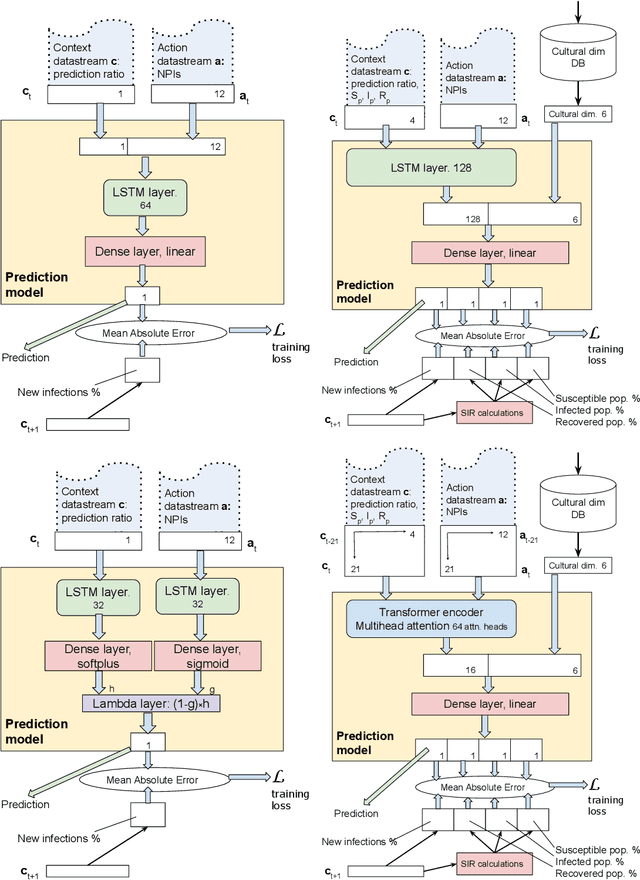
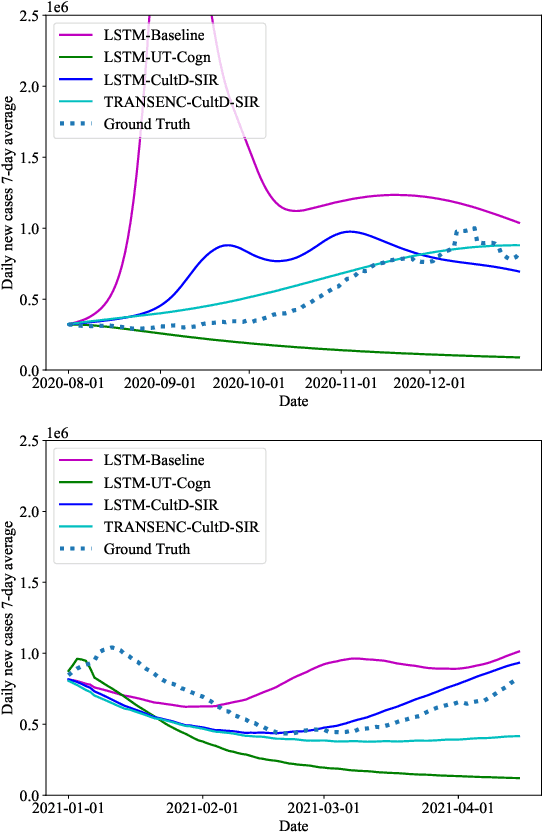

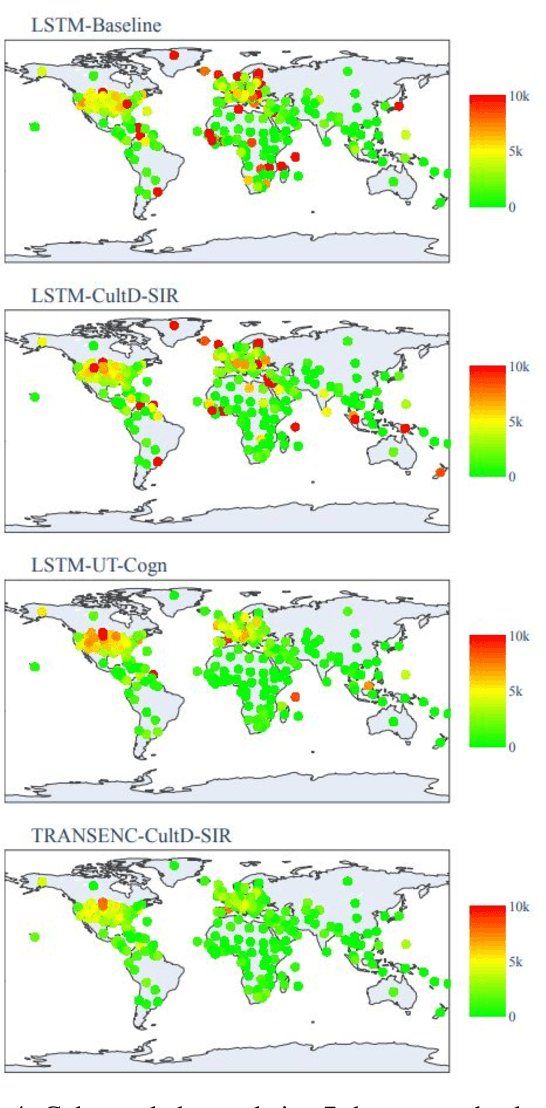
Throughout the Covid-19 pandemic, a significant amount of effort had been put into developing techniques that predict the number of infections under various assumptions about the public policy and non-pharmaceutical interventions. While both the available data and the sophistication of the AI models and available computing power exceed what was available in previous years, the overall success of prediction approaches was very limited. In this paper, we start from prediction algorithms proposed for XPrize Pandemic Response Challenge and consider several directions that might allow their improvement. Then, we investigate their performance over medium-term predictions extending over several months. We find that augmenting the algorithms with additional information about the culture of the modeled region, incorporating traditional compartmental models and up-to-date deep learning architectures can improve the performance for short term predictions, the accuracy of medium-term predictions is still very low and a significant amount of future research is needed to make such models a reliable component of a public policy toolbox.
Privacy-Preserving Learning of Human Activity Predictors in Smart Environments
Jan 17, 2021
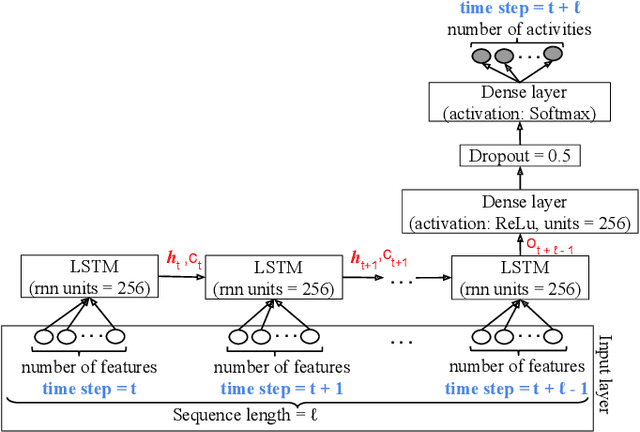

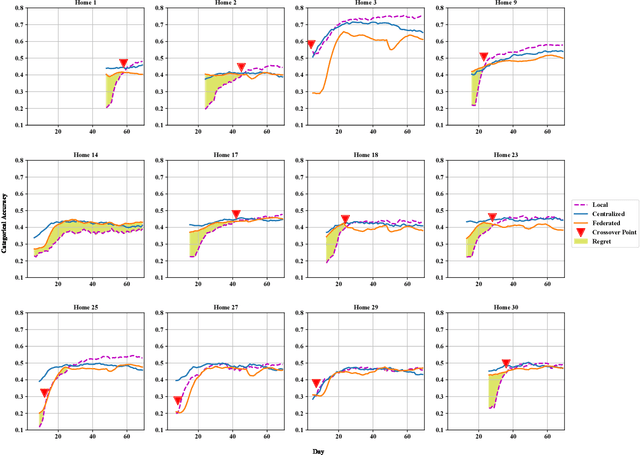
The daily activities performed by a disabled or elderly person can be monitored by a smart environment, and the acquired data can be used to learn a predictive model of user behavior. To speed up the learning, several researchers designed collaborative learning systems that use data from multiple users. However, disclosing the daily activities of an elderly or disabled user raises privacy concerns. In this paper, we use state-of-the-art deep neural network-based techniques to learn predictive human activity models in the local, centralized, and federated learning settings. A novel aspect of our work is that we carefully track the temporal evolution of the data available to the learner and the data shared by the user. In contrast to previous work where users shared all their data with the centralized learner, we consider users that aim to preserve their privacy. Thus, they choose between approaches in order to achieve their goals of predictive accuracy while minimizing the shared data. To help users make decisions before disclosing any data, we use machine learning to predict the degree to which a user would benefit from collaborative learning. We validate our approaches on real-world data.
Reducing Overestimation Bias by Increasing Representation Dissimilarity in Ensemble Based Deep Q-Learning
Jun 24, 2020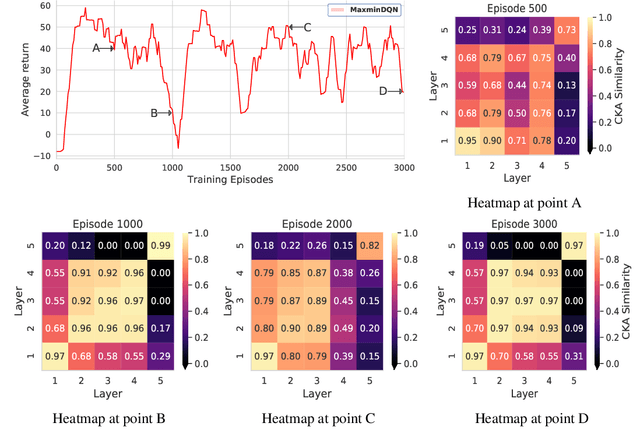
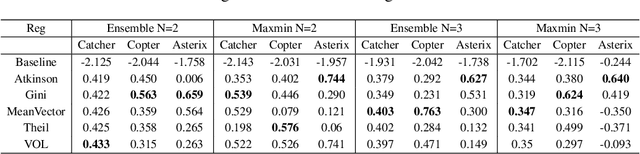
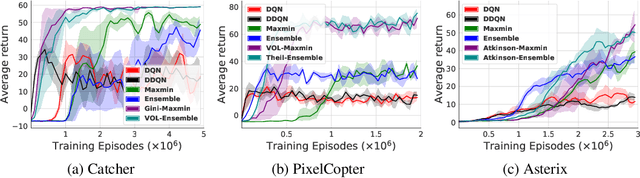
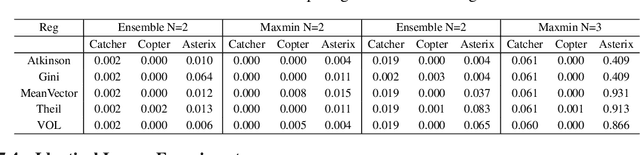
The first deep RL algorithm, DQN, was limited by the overestimation bias of the learned Q-function. Subsequent algorithms proposed techniques to reduce this problem, without fully eliminating it. Recently, the Maxmin and Ensemble Q-learning algorithms used the different estimates provided by ensembles of learners to reduce the bias. Unfortunately, in many scenarios the learners converge to the same point in the parametric or representation space, falling back to the classic single neural network DQN. In this paper, we describe a regularization technique to increase the dissimilarity in the representation space in these algorithms. We propose and compare five regularization functions inspired from economics theory and consensus optimization. We show that the resulting approach significantly outperforms the Maxmin and Ensemble Q-learning algorithms as well as non-ensemble baselines.
Unsupervised Meta-Learning through Latent-Space Interpolation in Generative Models
Jun 18, 2020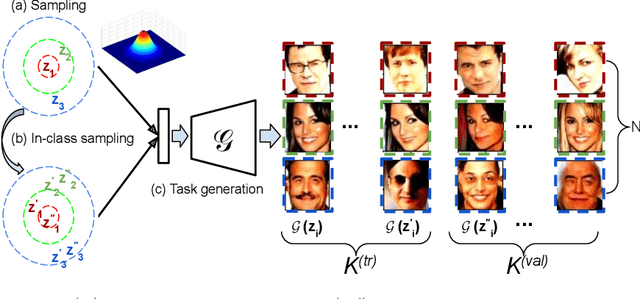

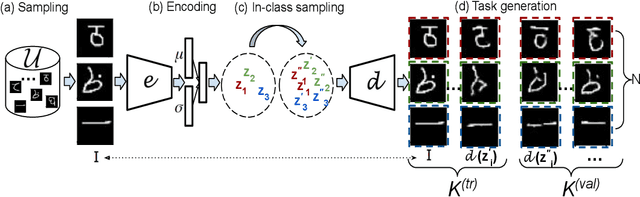
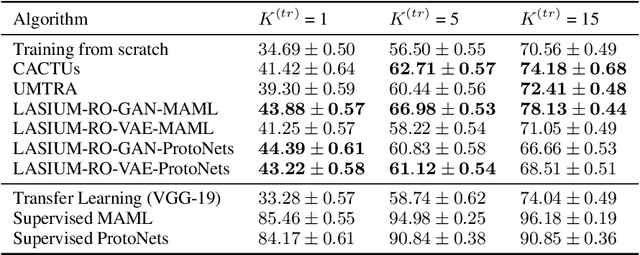
Unsupervised meta-learning approaches rely on synthetic meta-tasks that are created using techniques such as random selection, clustering and/or augmentation. Unfortunately, clustering and augmentation are domain-dependent, and thus they require either manual tweaking or expensive learning. In this work, we describe an approach that generates meta-tasks using generative models. A critical component is a novel approach of sampling from the latent space that generates objects grouped into synthetic classes forming the training and validation data of a meta-task. We find that the proposed approach, LAtent Space Interpolation Unsupervised Meta-learning (LASIUM), outperforms or is competitive with current unsupervised learning baselines on few-shot classification tasks on the most widely used benchmark datasets. In addition, the approach promises to be applicable without manual tweaking over a wider range of domains than previous approaches.
Multi-Agent Reinforcement Learning for Problems with Combined Individual and Team Reward
Mar 24, 2020
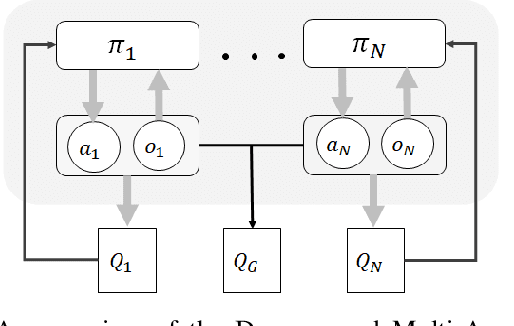

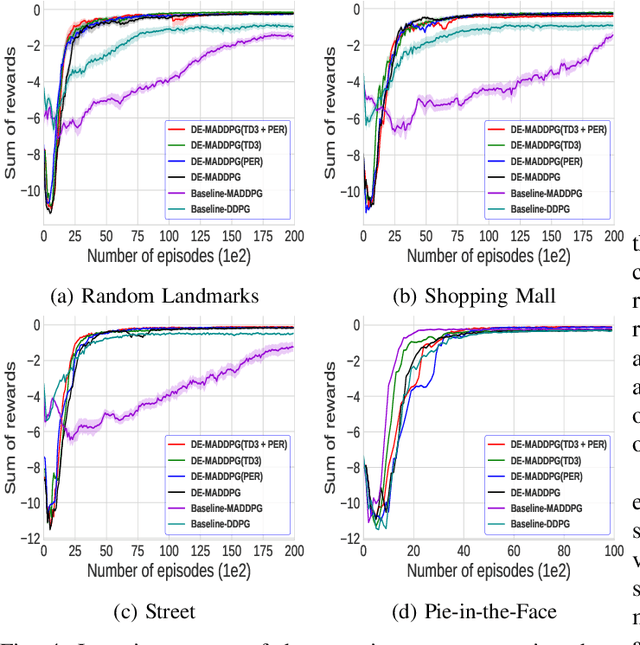
Many cooperative multi-agent problems require agents to learn individual tasks while contributing to the collective success of the group. This is a challenging task for current state-of-the-art multi-agent reinforcement algorithms that are designed to either maximize the global reward of the team or the individual local rewards. The problem is exacerbated when either of the rewards is sparse leading to unstable learning. To address this problem, we present Decomposed Multi-Agent Deep Deterministic Policy Gradient (DE-MADDPG): a novel cooperative multi-agent reinforcement learning framework that simultaneously learns to maximize the global and local rewards. We evaluate our solution on the challenging defensive escort team problem and show that our solution achieves a significantly better and more stable performance than the direct adaptation of the MADDPG algorithm.