 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAccept Synthetic Objects as Real: End-to-End Training of Attentive Deep Visuomotor Policies for Manipulation in Clutter
Sep 24, 2019


Recent research demonstrated that it is feasible to end-to-end train multi-task deep visuomotor policies for robotic manipulation using variations of learning from demonstration (LfD) and reinforcement learning (RL). In this paper, we extend the capabilities of end-to-end LfD architectures to object manipulation in clutter. We start by introducing a data augmentation procedure called Accept Synthetic Objects as Real (ASOR). Using ASOR we develop two network architectures: implicit attention ASOR-IA and explicit attention ASOR-EA. Both architectures use the same training data (demonstrations in uncluttered environments) as previous approaches. Experimental results show that ASOR-IA and ASOR-EA succeed ina significant fraction of trials in cluttered environments where previous approaches never succeed. In addition, we find that both ASOR-IA and ASOR-EA outperform previous approaches even in uncluttered environments, with ASOR-EA performing better even in clutter compared to the previous best baseline in an uncluttered environment.
Pay attention! - Robustifying a Deep Visuomotor Policy through Task-Focused Attention
Nov 28, 2018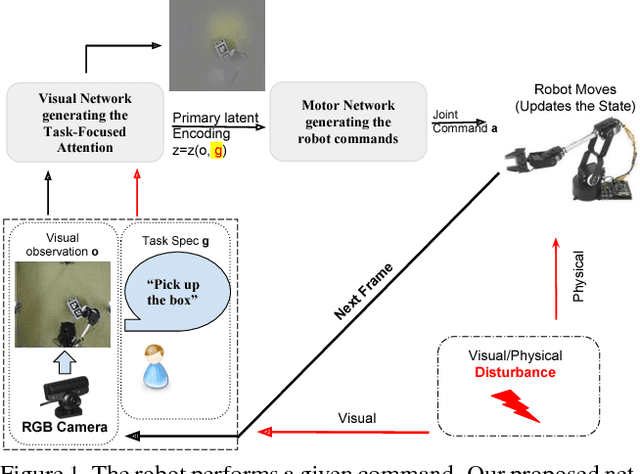
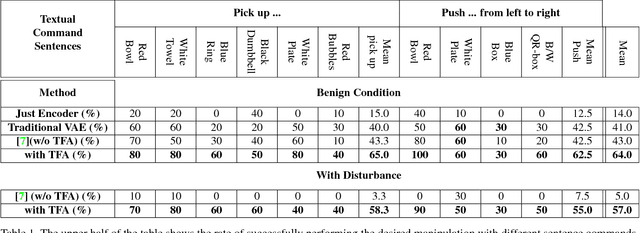
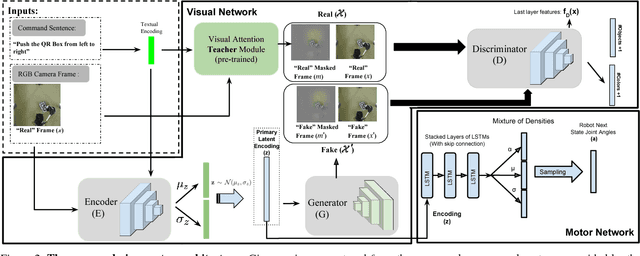

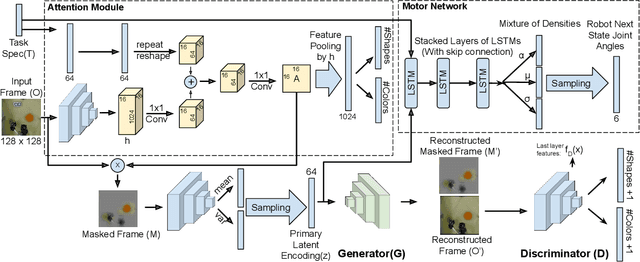
Several recent studies have demonstrated the promise of deep visuomotor policies for robot manipulator control. Despite impressive progress, these systems are known to be vulnerable to physical disturbances, such as accidental or adversarial bumps that make them drop the manipulated object. They also tend to be distracted by visual disturbances such as objects moving in the robot's field of view, even if the disturbance does not physically prevent the execution of the task. In this paper, we propose an approach for augmenting a deep visuomotor policy trained through demonstrations with Task Focused visual Attention (TFA). The manipulation task is specified with a natural language text such as `move the red bowl to the left'. This allows the visual attention component to concentrate on the current object that the robot needs to manipulate. We show that even in benign environments, the TFA allows the policy to consistently outperform a variant with no attention mechanism. More importantly, the new policy is significantly more robust: it regularly recovers from severe physical disturbances (such as bumps causing it to drop the object) from which the baseline policy, i.e. with no visual attention, almost never recovers. In addition, we show that the proposed policy performs correctly in the presence of a wide class of visual disturbances, exhibiting a behavior reminiscent of human selective visual attention experiments. Our proposed approach consists of a VAE-GAN network which encodes the visual input and feeds it to a Motor network that moves the robot joints. Also, our approach benefits from a teacher network for the TFA that leverages textual input command to robustify the visual encoder against various types of disturbances.
Vision-Based Multi-Task Manipulation for Inexpensive Robots Using End-To-End Learning from Demonstration
Apr 22, 2018



We propose a technique for multi-task learning from demonstration that trains the controller of a low-cost robotic arm to accomplish several complex picking and placing tasks, as well as non-prehensile manipulation. The controller is a recurrent neural network using raw images as input and generating robot arm trajectories, with the parameters shared across the tasks. The controller also combines VAE-GAN-based reconstruction with autoregressive multimodal action prediction. Our results demonstrate that it is possible to learn complex manipulation tasks, such as picking up a towel, wiping an object, and depositing the towel to its previous position, entirely from raw images with direct behavior cloning. We show that weight sharing and reconstruction-based regularization substantially improve generalization and robustness, and training on multiple tasks simultaneously increases the success rate on all tasks.
From virtual demonstration to real-world manipulation using LSTM and MDN
Nov 22, 2017



Robots assisting the disabled or elderly must perform complex manipulation tasks and must adapt to the home environment and preferences of their user. Learning from demonstration is a promising choice, that would allow the non-technical user to teach the robot different tasks. However, collecting demonstrations in the home environment of a disabled user is time consuming, disruptive to the comfort of the user, and presents safety challenges. It would be desirable to perform the demonstrations in a virtual environment. In this paper we describe a solution to the challenging problem of behavior transfer from virtual demonstration to a physical robot. The virtual demonstrations are used to train a deep neural network based controller, which is using a Long Short Term Memory (LSTM) recurrent neural network to generate trajectories. The training process uses a Mixture Density Network (MDN) to calculate an error signal suitable for the multimodal nature of demonstrations. The controller learned in the virtual environment is transferred to a physical robot (a Rethink Robotics Baxter). An off-the-shelf vision component is used to substitute for geometric knowledge available in the simulation and an inverse kinematics module is used to allow the Baxter to enact the trajectory. Our experimental studies validate the three contributions of the paper: (1) the controller learned from virtual demonstrations can be used to successfully perform the manipulation tasks on a physical robot, (2) the LSTM+MDN architectural choice outperforms other choices, such as the use of feedforward networks and mean-squared error based training signals and (3) allowing imperfect demonstrations in the training set also allows the controller to learn how to correct its manipulation mistakes.