 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAccept Synthetic Objects as Real: End-to-End Training of Attentive Deep Visuomotor Policies for Manipulation in Clutter
Paper and Code


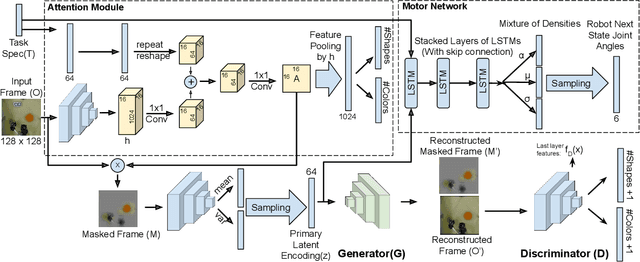

Recent research demonstrated that it is feasible to end-to-end train multi-task deep visuomotor policies for robotic manipulation using variations of learning from demonstration (LfD) and reinforcement learning (RL). In this paper, we extend the capabilities of end-to-end LfD architectures to object manipulation in clutter. We start by introducing a data augmentation procedure called Accept Synthetic Objects as Real (ASOR). Using ASOR we develop two network architectures: implicit attention ASOR-IA and explicit attention ASOR-EA. Both architectures use the same training data (demonstrations in uncluttered environments) as previous approaches. Experimental results show that ASOR-IA and ASOR-EA succeed ina significant fraction of trials in cluttered environments where previous approaches never succeed. In addition, we find that both ASOR-IA and ASOR-EA outperform previous approaches even in uncluttered environments, with ASOR-EA performing better even in clutter compared to the previous best baseline in an uncluttered environment.