 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVision-Based Multi-Task Manipulation for Inexpensive Robots Using End-To-End Learning from Demonstration
Apr 22, 2018



We propose a technique for multi-task learning from demonstration that trains the controller of a low-cost robotic arm to accomplish several complex picking and placing tasks, as well as non-prehensile manipulation. The controller is a recurrent neural network using raw images as input and generating robot arm trajectories, with the parameters shared across the tasks. The controller also combines VAE-GAN-based reconstruction with autoregressive multimodal action prediction. Our results demonstrate that it is possible to learn complex manipulation tasks, such as picking up a towel, wiping an object, and depositing the towel to its previous position, entirely from raw images with direct behavior cloning. We show that weight sharing and reconstruction-based regularization substantially improve generalization and robustness, and training on multiple tasks simultaneously increases the success rate on all tasks.
From virtual demonstration to real-world manipulation using LSTM and MDN
Nov 22, 2017



Robots assisting the disabled or elderly must perform complex manipulation tasks and must adapt to the home environment and preferences of their user. Learning from demonstration is a promising choice, that would allow the non-technical user to teach the robot different tasks. However, collecting demonstrations in the home environment of a disabled user is time consuming, disruptive to the comfort of the user, and presents safety challenges. It would be desirable to perform the demonstrations in a virtual environment. In this paper we describe a solution to the challenging problem of behavior transfer from virtual demonstration to a physical robot. The virtual demonstrations are used to train a deep neural network based controller, which is using a Long Short Term Memory (LSTM) recurrent neural network to generate trajectories. The training process uses a Mixture Density Network (MDN) to calculate an error signal suitable for the multimodal nature of demonstrations. The controller learned in the virtual environment is transferred to a physical robot (a Rethink Robotics Baxter). An off-the-shelf vision component is used to substitute for geometric knowledge available in the simulation and an inverse kinematics module is used to allow the Baxter to enact the trajectory. Our experimental studies validate the three contributions of the paper: (1) the controller learned from virtual demonstrations can be used to successfully perform the manipulation tasks on a physical robot, (2) the LSTM+MDN architectural choice outperforms other choices, such as the use of feedforward networks and mean-squared error based training signals and (3) allowing imperfect demonstrations in the training set also allows the controller to learn how to correct its manipulation mistakes.
Internet of Things Applications: Animal Monitoring with Unmanned Aerial Vehicle
Oct 20, 2016


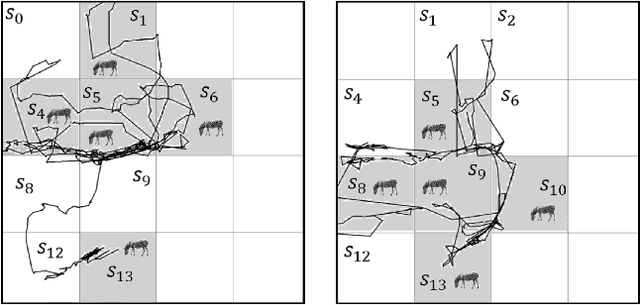
In animal monitoring applications, both animal detection and their movement prediction are major tasks. While a variety of animal monitoring strategies exist, most of them rely on mounting devices. However, in real world, it is difficult to find these animals and install mounting devices. In this paper, we propose an animal monitoring application by utilizing wireless sensor networks (WSNs) and unmanned aerial vehicle (UAV). The objective of the application is to detect locations of endangered species in large-scale wildlife areas and monitor movement of animals without any attached devices. In this application, sensors deployed throughout the observation area are responsible for gathering animal information. The UAV flies above the observation area and collects the information from sensors. To achieve the information efficiently, we propose a path planning approach for the UAV based on a Markov decision process (MDP) model. The UAV receives a certain amount of reward from an area if some animals are detected at that location. We solve the MDP using Q-learning such that the UAV prefers going to those areas that animals are detected before. Meanwhile, the UAV explores other areas as well to cover the entire network and detects changes in the animal positions. We first define the mathematical model underlying the animal monitoring problem in terms of the value of information (VoI) and rewards. We propose a network model including clusters of sensor nodes and a single UAV that acts as a mobile sink and visits the clusters. Then, one MDP-based path planning approach is designed to maximize the VoI while reducing message delays. The effectiveness of the proposed approach is evaluated using two real-world movement datasets of zebras and leopard. Simulation results show that our approach outperforms greedy, random heuristics and the path planning based on the traveling salesman problem.