 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGrasping Using Tactile Sensing and Deep Calibration
Jul 23, 2019



Tactile perception is an essential ability of intelligent robots in interaction with their surrounding environments. This perception as an intermediate level acts between sensation and action and has to be defined properly to generate suitable action in response to sensed data. In this paper, we propose a feedback approach to address robot grasping task using force-torque tactile sensing. While visual perception is an essential part for gross reaching, constant utilization of this sensing modality can negatively affect the grasping process with overwhelming computation. In such case, human being utilizes tactile sensing to interact with objects. Inspired by, the proposed approach is presented and evaluated on a real robot to demonstrate the effectiveness of the suggested framework. Moreover, we utilize a deep learning framework called Deep Calibration in order to eliminate the effect of bias in the collected data from the robot sensors.
Real-time policy generation and its application to robot grasping
Aug 23, 2018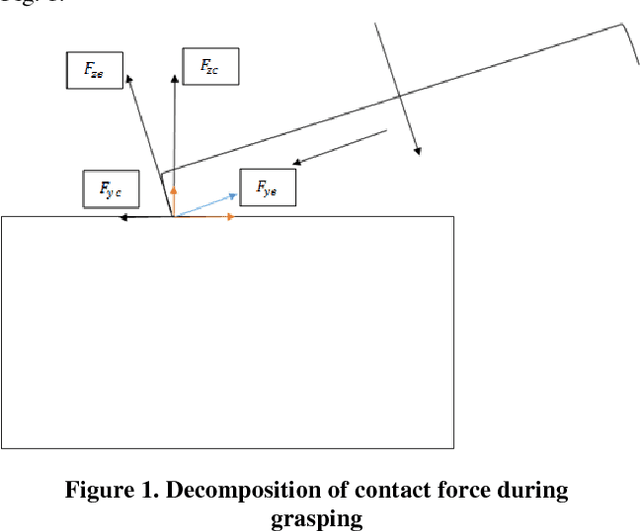
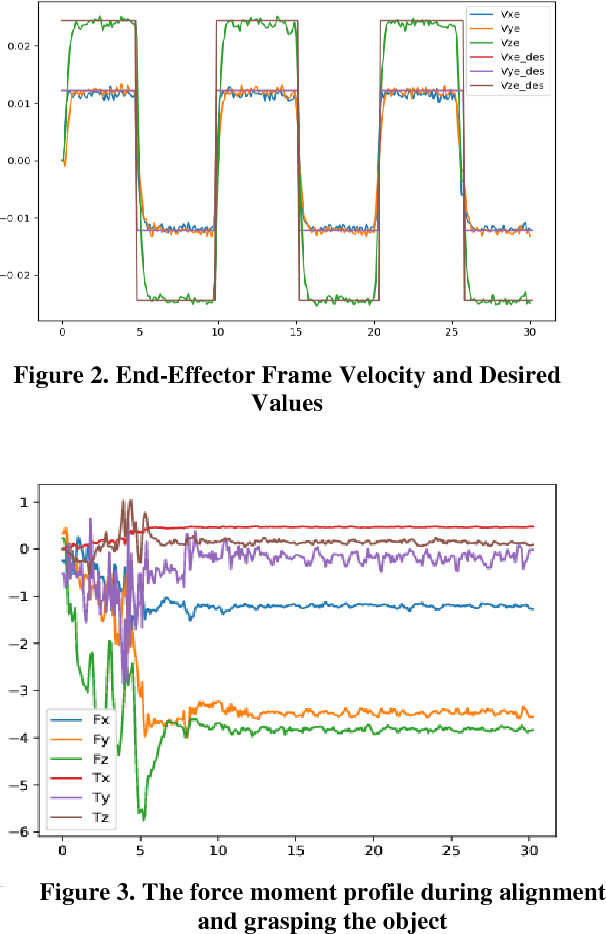
Real time applications such as robotic require real time actions based on the immediate available data. Machine learning and artificial intelligence rely on high volume of training informative data set to propose a comprehensive and useful model for later real time action. Our goal in this paper is to provide a solution for robot grasping as a real time application without the time and memory consuming pertaining phase. Grasping as one of the most important ability of human being is defined as a suitable configuration which depends on the perceived information from the object. For human being, the best results obtain when one incorporates the vision data such as the extracted edges and shape from the object into grasping task. Nevertheless, in robotics, vision will not suite for every situation. Another possibility to grasping is using the object shape information from its vicinity. Based on these Haptic information, similar to human being, one can propose different approaches to grasping which are called grasping policies. In this work, we are trying to introduce a real time policy which aims at keeping contact with the object during movement and alignment on it. First we state problem by system dynamic equation incorporated by the object constraint surface into dynamic equation. In next step, the suggested policy to accomplish the task in real time based on the available sensor information will be presented. The effectiveness of proposed approach will be evaluated by demonstration results.
Edge-Based Recognition of Novel Objects for Robotic Grasping
Feb 23, 2018
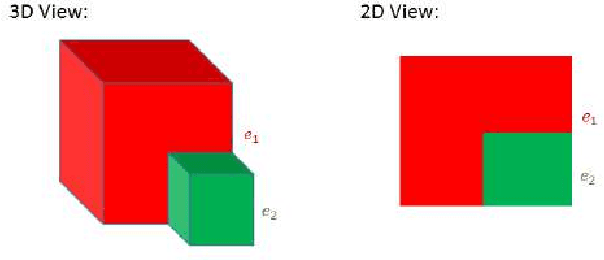
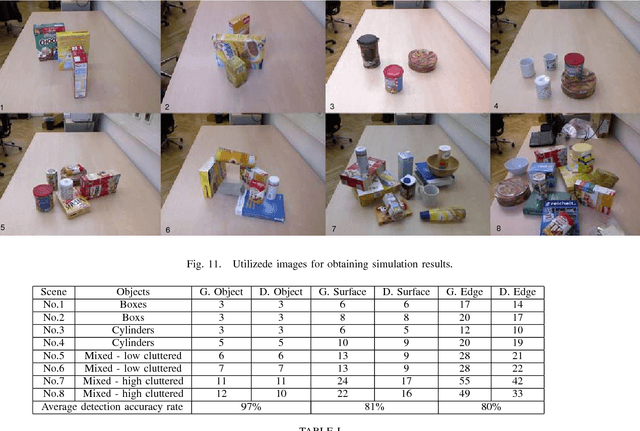

In this paper, we investigate the problem of grasping novel objects in unstructured environments. To address this problem, consideration of the object geometry, reachability and force closure analysis are required. We propose a framework for grasping unknown objects by localizing contact regions on the contours formed by a set of depth edges in a single view 2D depth image. According to the edge geometric features obtained from analyzing the data of the depth map, the contact regions are determined. Finally,We validate the performance of the approach by applying it to the scenes with both single and multiple objects, using Baxter manipulator.
From virtual demonstration to real-world manipulation using LSTM and MDN
Nov 22, 2017



Robots assisting the disabled or elderly must perform complex manipulation tasks and must adapt to the home environment and preferences of their user. Learning from demonstration is a promising choice, that would allow the non-technical user to teach the robot different tasks. However, collecting demonstrations in the home environment of a disabled user is time consuming, disruptive to the comfort of the user, and presents safety challenges. It would be desirable to perform the demonstrations in a virtual environment. In this paper we describe a solution to the challenging problem of behavior transfer from virtual demonstration to a physical robot. The virtual demonstrations are used to train a deep neural network based controller, which is using a Long Short Term Memory (LSTM) recurrent neural network to generate trajectories. The training process uses a Mixture Density Network (MDN) to calculate an error signal suitable for the multimodal nature of demonstrations. The controller learned in the virtual environment is transferred to a physical robot (a Rethink Robotics Baxter). An off-the-shelf vision component is used to substitute for geometric knowledge available in the simulation and an inverse kinematics module is used to allow the Baxter to enact the trajectory. Our experimental studies validate the three contributions of the paper: (1) the controller learned from virtual demonstrations can be used to successfully perform the manipulation tasks on a physical robot, (2) the LSTM+MDN architectural choice outperforms other choices, such as the use of feedforward networks and mean-squared error based training signals and (3) allowing imperfect demonstrations in the training set also allows the controller to learn how to correct its manipulation mistakes.