 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReducing Overestimation Bias by Increasing Representation Dissimilarity in Ensemble Based Deep Q-Learning
Jun 24, 2020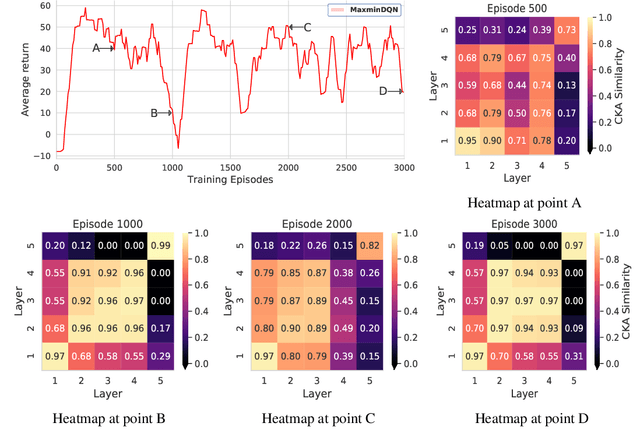
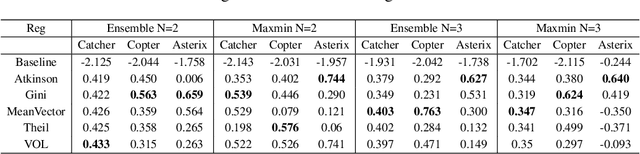
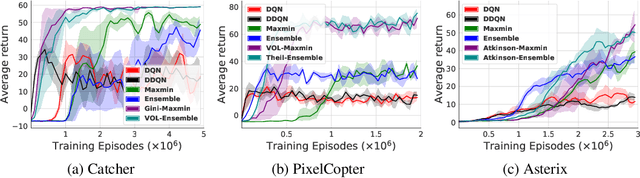
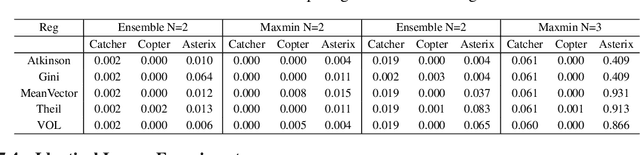
The first deep RL algorithm, DQN, was limited by the overestimation bias of the learned Q-function. Subsequent algorithms proposed techniques to reduce this problem, without fully eliminating it. Recently, the Maxmin and Ensemble Q-learning algorithms used the different estimates provided by ensembles of learners to reduce the bias. Unfortunately, in many scenarios the learners converge to the same point in the parametric or representation space, falling back to the classic single neural network DQN. In this paper, we describe a regularization technique to increase the dissimilarity in the representation space in these algorithms. We propose and compare five regularization functions inspired from economics theory and consensus optimization. We show that the resulting approach significantly outperforms the Maxmin and Ensemble Q-learning algorithms as well as non-ensemble baselines.
Multi-Agent Reinforcement Learning for Problems with Combined Individual and Team Reward
Mar 24, 2020
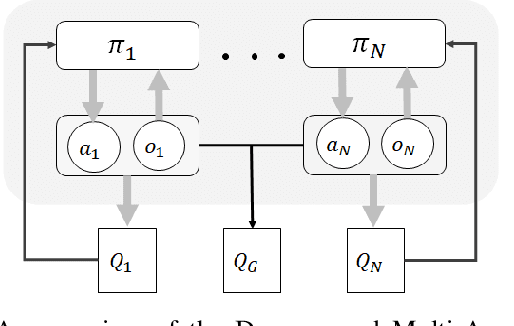

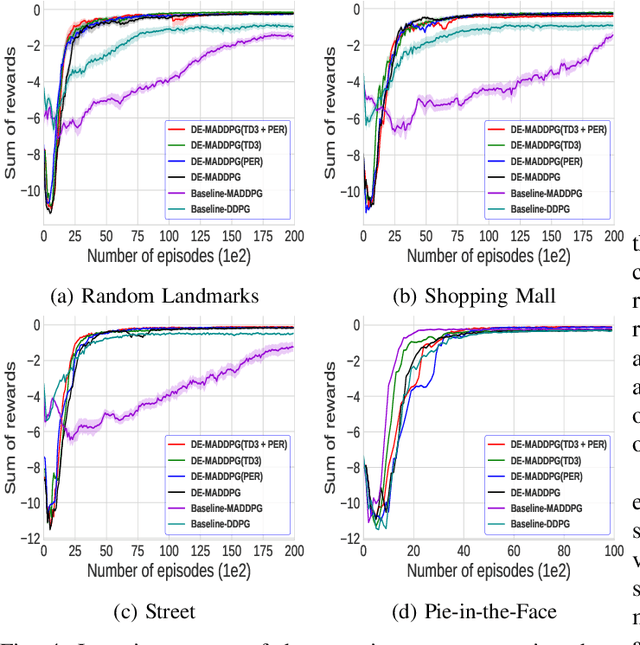
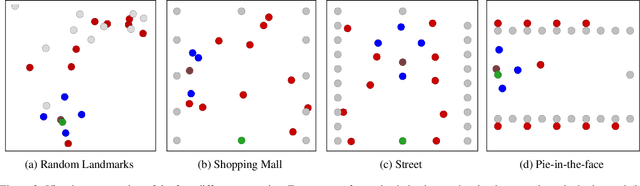
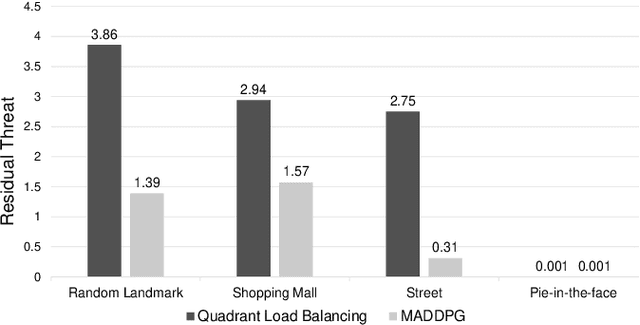
Many cooperative multi-agent problems require agents to learn individual tasks while contributing to the collective success of the group. This is a challenging task for current state-of-the-art multi-agent reinforcement algorithms that are designed to either maximize the global reward of the team or the individual local rewards. The problem is exacerbated when either of the rewards is sparse leading to unstable learning. To address this problem, we present Decomposed Multi-Agent Deep Deterministic Policy Gradient (DE-MADDPG): a novel cooperative multi-agent reinforcement learning framework that simultaneously learns to maximize the global and local rewards. We evaluate our solution on the challenging defensive escort team problem and show that our solution achieves a significantly better and more stable performance than the direct adaptation of the MADDPG algorithm.
Universal Policies to Learn Them All
Aug 24, 2019

We explore a collaborative and cooperative multi-agent reinforcement learning setting where a team of reinforcement learning agents attempt to solve a single cooperative task in a multi-scenario setting. We propose a novel multi-agent reinforcement learning algorithm inspired by universal value function approximators that not only generalizes over state space but also over a set of different scenarios. Additionally, to prove our claim, we are introducing a challenging 2D multi-agent urban security environment where the learning agents are trying to protect a person from nearby bystanders in a variety of scenarios. Our study shows that state-of-the-art multi-agent reinforcement learning algorithms fail to generalize a single task over multiple scenarios while our proposed solution works equally well as scenario-dependent policies.
Designing a Multi-Objective Reward Function for Creating Teams of Robotic Bodyguards Using Deep Reinforcement Learning
Jan 28, 2019
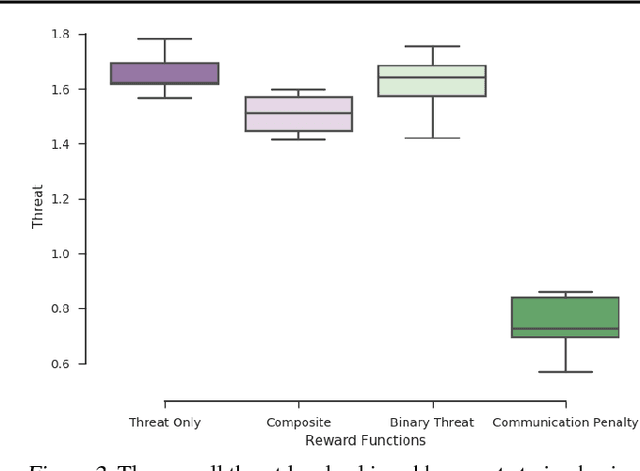
We are considering a scenario where a team of bodyguard robots provides physical protection to a VIP in a crowded public space. We use deep reinforcement learning to learn the policy to be followed by the robots. As the robot bodyguards need to follow several difficult-to-reconcile goals, we study several primitive and composite reward functions and their impact on the overall behavior of the robotic bodyguards.