Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVideo Fill in the Blank with Merging LSTMs
Paper and Code
Oct 13, 2016

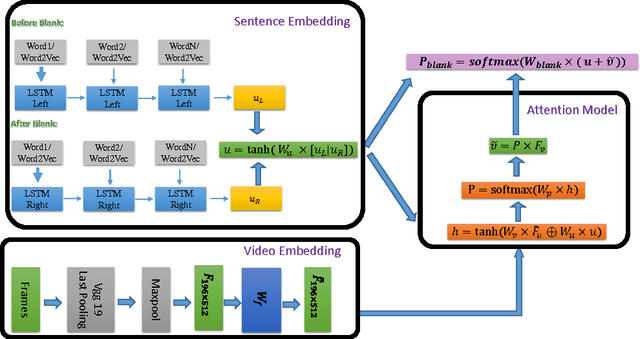
Given a video and its incomplete textural description with missing words, the Video-Fill-in-the-Blank (ViFitB) task is to automatically find the missing word. The contextual information of the sentences are important to infer the missing words; the visual cues are even more crucial to get a more accurate inference. In this paper, we presents a new method which intuitively takes advantage of the structure of the sentences and employs merging LSTMs (to merge two LSTMs) to tackle the problem with embedded textural and visual cues. In the experiments, we have demonstrated the superior performance of the proposed method on the challenging "Movie Fill-in-the-Blank" dataset.
* for Large Scale Movie Description and Understanding Challenge (LSMDC)
2016, "Movie fill-in-the-blank" Challenge, UCF_CRCV
View paper on