 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVisual Text Correction
Paper and Code

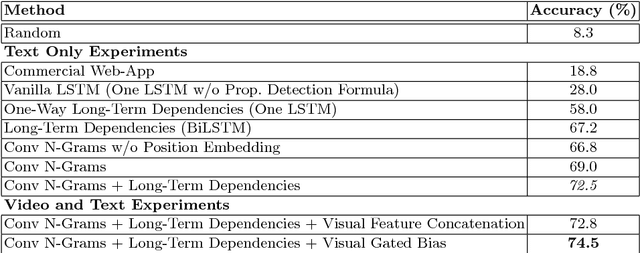
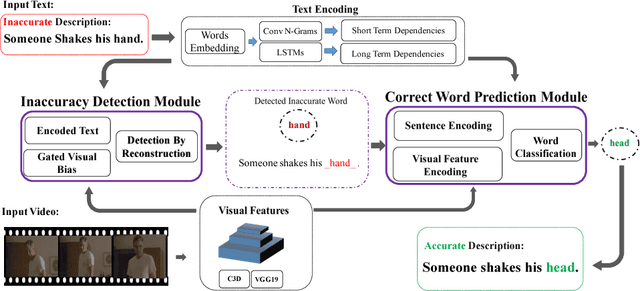

Videos, images, and sentences are mediums that can express the same semantics. One can imagine a picture by reading a sentence or can describe a scene with some words. However, even small changes in a sentence can cause a significant semantic inconsistency with the corresponding video/image. For example, by changing the verb of a sentence, the meaning may drastically change. There have been many efforts to encode a video/sentence and decode it as a sentence/video. In this research, we study a new scenario in which both the sentence and the video are given, but the sentence is inaccurate. A semantic inconsistency between the sentence and the video or between the words of a sentence can result in an inaccurate description. This paper introduces a new problem, called Visual Text Correction (VTC), i.e., finding and replacing an inaccurate word in the textual description of a video. We propose a deep network that can simultaneously detect an inaccuracy in a sentence, and fix it by replacing the inaccurate word(s). Our method leverages the semantic interdependence of videos and words, as well as the short-term and long-term relations of the words in a sentence. In our formulation, part of a visual feature vector for every single word is dynamically selected through a gating process. Furthermore, to train and evaluate our model, we propose an approach to automatically construct a large dataset for VTC problem. Our experiments and performance analysis demonstrates that the proposed method provides very good results and also highlights the general challenges in solving the VTC problem. To the best of our knowledge, this work is the first of its kind for the Visual Text Correction task.