 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Structuring Real-World Data at Scale: Deep Learning for Extracting Key Oncology Information from Clinical Text with Patient-Level Supervision
Mar 20, 2022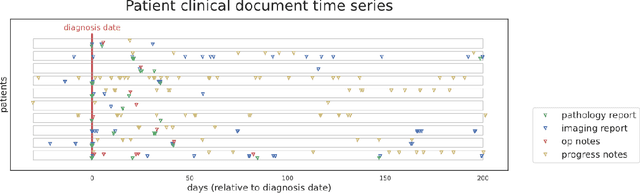
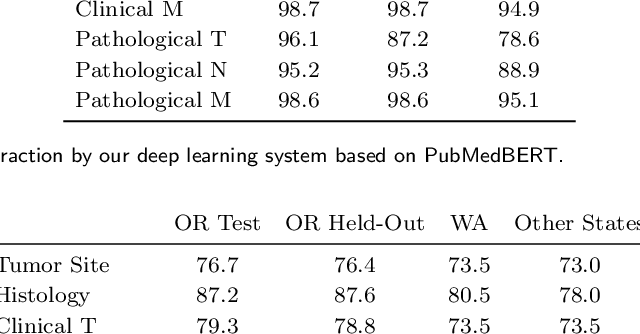
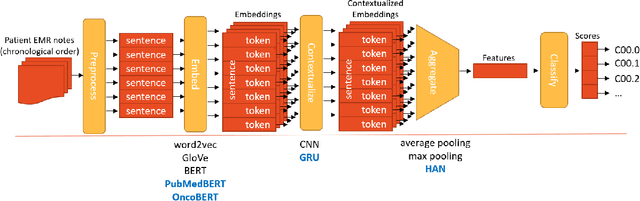
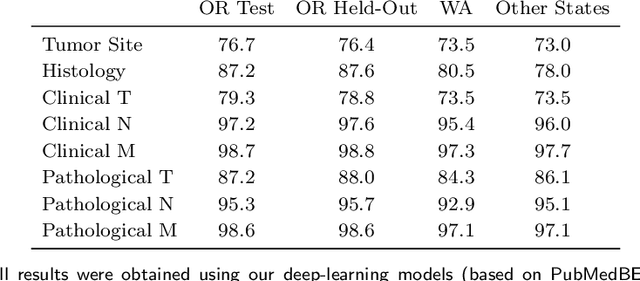
Objective: The majority of detailed patient information in real-world data (RWD) is only consistently available in free-text clinical documents. Manual curation is expensive and time-consuming. Developing natural language processing (NLP) methods for structuring RWD is thus essential for scaling real-world evidence generation. Materials and Methods: Traditional rule-based systems are vulnerable to the prevalent linguistic variations and ambiguities in clinical text, and prior applications of machine-learning methods typically require sentence-level or report-level labeled examples that are hard to produce at scale. We propose leveraging patient-level supervision from medical registries, which are often readily available and capture key patient information, for general RWD applications. To combat the lack of sentence-level or report-level annotations, we explore advanced deep-learning methods by combining domain-specific pretraining, recurrent neural networks, and hierarchical attention. Results: We conduct an extensive study on 135,107 patients from the cancer registry of a large integrated delivery network (IDN) comprising healthcare systems in five western US states. Our deep learning methods attain test AUROC of 94-99% for key tumor attributes and comparable performance on held-out data from separate health systems and states. Discussion and Conclusion: Ablation results demonstrate clear superiority of these advanced deep-learning methods over prior approaches. Error analysis shows that our NLP system sometimes even corrects errors in registrar labels. We also conduct a preliminary investigation in accelerating registry curation and general RWD structuring via assisted curation for over 1.2 million cancer patients in this healthcare network.