 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Morphological Feature Perturbations for Calibrated Semi-Supervised Segmentation
Paper and Code

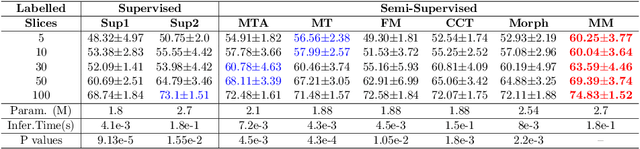
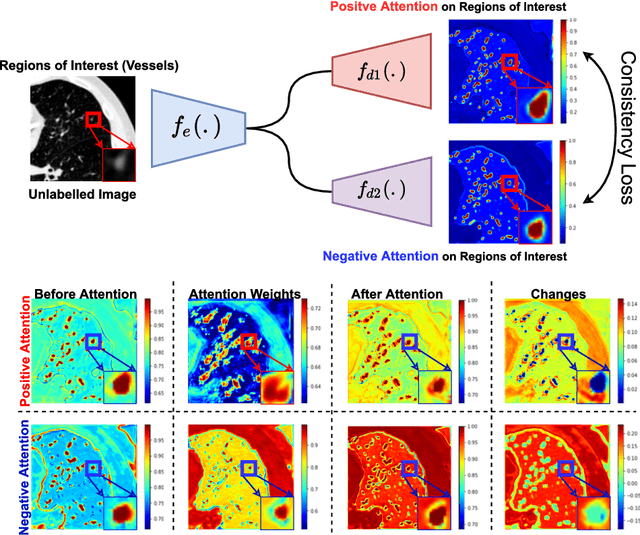

We propose MisMatch, a novel consistency-driven semi-supervised segmentation framework which produces predictions that are invariant to learnt feature perturbations. MisMatch consists of an encoder and a two-head decoders. One decoder learns positive attention to the foreground regions of interest (RoI) on unlabelled images thereby generating dilated features. The other decoder learns negative attention to the foreground on the same unlabelled images thereby generating eroded features. We then apply a consistency regularisation on the paired predictions. MisMatch outperforms state-of-the-art semi-supervised methods on a CT-based pulmonary vessel segmentation task and a MRI-based brain tumour segmentation task. In addition, we show that the effectiveness of MisMatch comes from better model calibration than its supervised learning counterpart.