 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExpectation Maximization Pseudo Labelling for Segmentation with Limited Annotations
May 02, 2023We study pseudo labelling and its generalisation for semi-supervised segmentation of medical images. Pseudo labelling has achieved great empirical successes in semi-supervised learning, by utilising raw inferences on unlabelled data as pseudo labels for self-training. In our paper, we build a connection between pseudo labelling and the Expectation Maximization algorithm which partially explains its empirical successes. We thereby realise that the original pseudo labelling is an empirical estimation of its underlying full formulation. Following this insight, we demonstrate the full generalisation of pseudo labels under Bayes' principle, called Bayesian Pseudo Labels. We then provide a variational approach to learn to approximate Bayesian Pseudo Labels, by learning a threshold to select good quality pseudo labels. In the rest of the paper, we demonstrate the applications of Pseudo Labelling and its generalisation Bayesian Psuedo Labelling in semi-supervised segmentation of medical images on: 1) 3D binary segmentation of lung vessels from CT volumes; 2) 2D multi class segmentation of brain tumours from MRI volumes; 3) 3D binary segmentation of brain tumours from MRI volumes. We also show that pseudo labels can enhance the robustness of the learnt representations.
Deformably-Scaled Transposed Convolution
Oct 17, 2022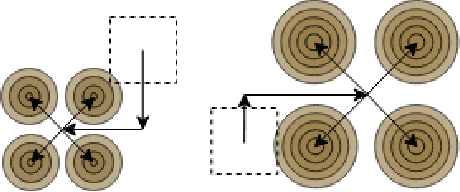

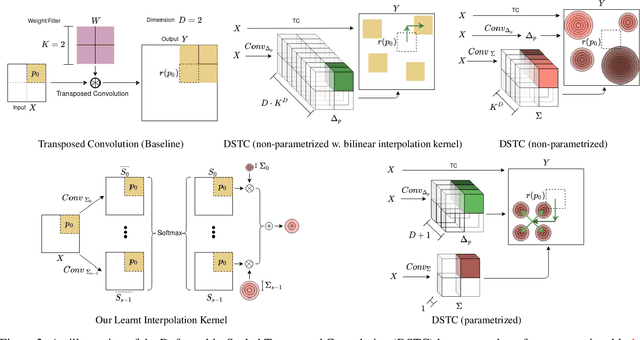
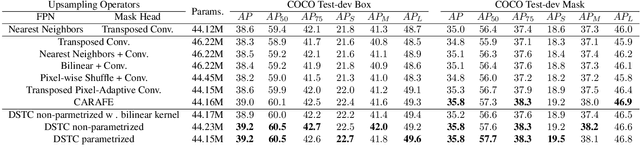
Transposed convolution is crucial for generating high-resolution outputs, yet has received little attention compared to convolution layers. In this work we revisit transposed convolution and introduce a novel layer that allows us to place information in the image selectively and choose the `stroke breadth' at which the image is synthesized, whilst incurring a small additional parameter cost. For this we introduce three ideas: firstly, we regress offsets to the positions where the transpose convolution results are placed; secondly we broadcast the offset weight locations over a learnable neighborhood; and thirdly we use a compact parametrization to share weights and restrict offsets. We show that simply substituting upsampling operators with our novel layer produces substantial improvements across tasks as diverse as instance segmentation, object detection, semantic segmentation, generative image modeling, and 3D magnetic resonance image enhancement, while outperforming all existing variants of transposed convolutions. Our novel layer can be used as a drop-in replacement for 2D and 3D upsampling operators and the code will be publicly available.
Airway measurement by refinement of synthetic images improves mortality prediction in idiopathic pulmonary fibrosis
Aug 30, 2022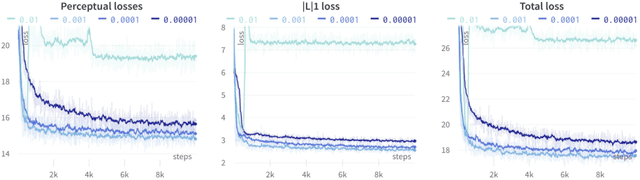
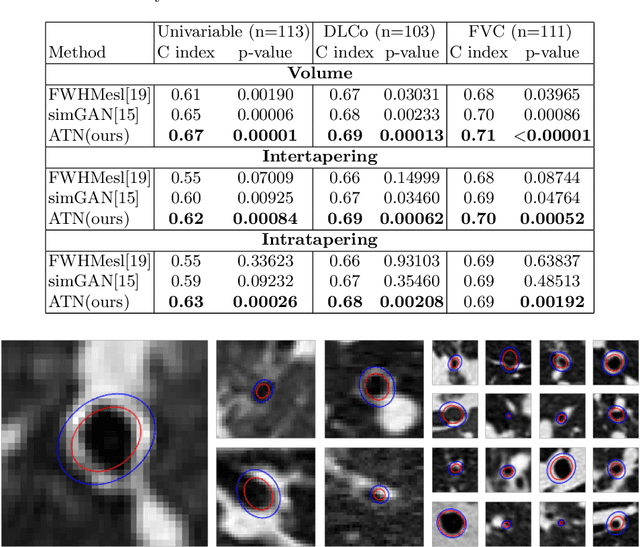
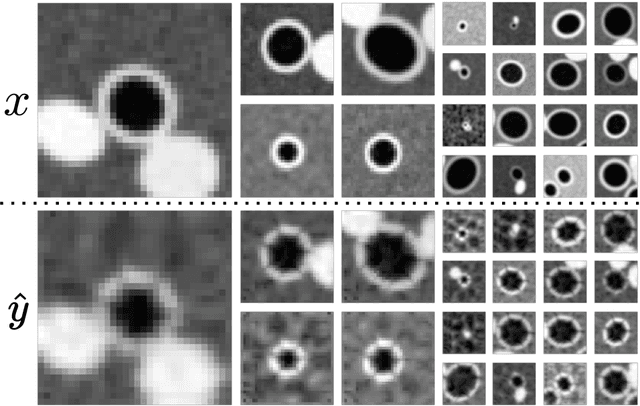
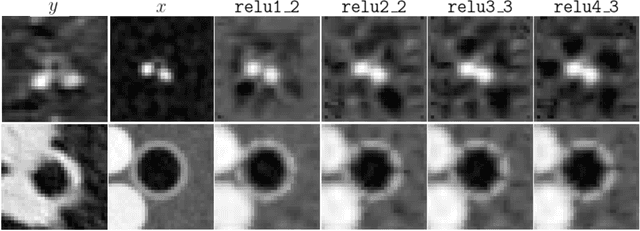
Several chronic lung diseases, like idiopathic pulmonary fibrosis (IPF) are characterised by abnormal dilatation of the airways. Quantification of airway features on computed tomography (CT) can help characterise disease progression. Physics based airway measurement algorithms have been developed, but have met with limited success in part due to the sheer diversity of airway morphology seen in clinical practice. Supervised learning methods are also not feasible due to the high cost of obtaining precise airway annotations. We propose synthesising airways by style transfer using perceptual losses to train our model, Airway Transfer Network (ATN). We compare our ATN model with a state-of-the-art GAN-based network (simGAN) using a) qualitative assessment; b) assessment of the ability of ATN and simGAN based CT airway metrics to predict mortality in a population of 113 patients with IPF. ATN was shown to be quicker and easier to train than simGAN. ATN-based airway measurements were also found to be consistently stronger predictors of mortality than simGAN-derived airway metrics on IPF CTs. Airway synthesis by a transformation network that refines synthetic data using perceptual losses is a realistic alternative to GAN-based methods for clinical CT analyses of idiopathic pulmonary fibrosis. Our source code can be found at https://github.com/ashkanpakzad/ATN that is compatible with the existing open-source airway analysis framework, AirQuant.
Bayesian Pseudo Labels: Expectation Maximization for Robust and Efficient Semi-Supervised Segmentation
Aug 08, 2022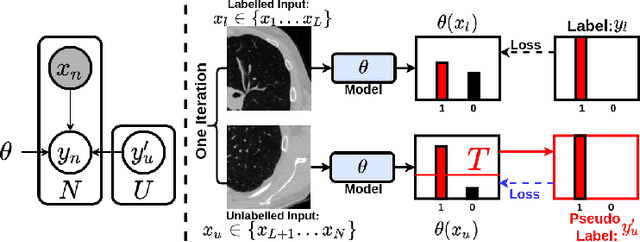
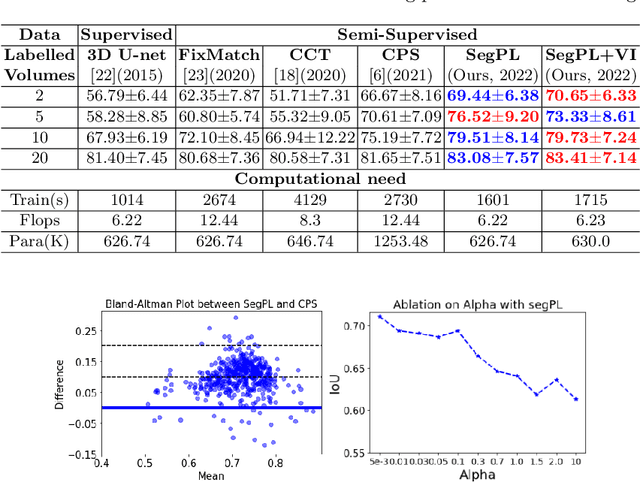


This paper concerns pseudo labelling in segmentation. Our contribution is fourfold. Firstly, we present a new formulation of pseudo-labelling as an Expectation-Maximization (EM) algorithm for clear statistical interpretation. Secondly, we propose a semi-supervised medical image segmentation method purely based on the original pseudo labelling, namely SegPL. We demonstrate SegPL is a competitive approach against state-of-the-art consistency regularisation based methods on semi-supervised segmentation on a 2D multi-class MRI brain tumour segmentation task and a 3D binary CT lung vessel segmentation task. The simplicity of SegPL allows less computational cost comparing to prior methods. Thirdly, we demonstrate that the effectiveness of SegPL may originate from its robustness against out-of-distribution noises and adversarial attacks. Lastly, under the EM framework, we introduce a probabilistic generalisation of SegPL via variational inference, which learns a dynamic threshold for pseudo labelling during the training. We show that SegPL with variational inference can perform uncertainty estimation on par with the gold-standard method Deep Ensemble.
Learning Morphological Feature Perturbations for Calibrated Semi-Supervised Segmentation
Apr 01, 2022
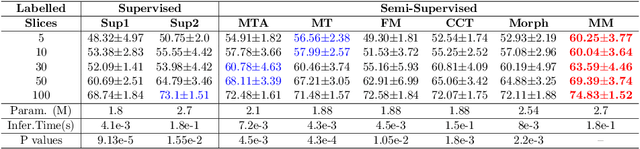
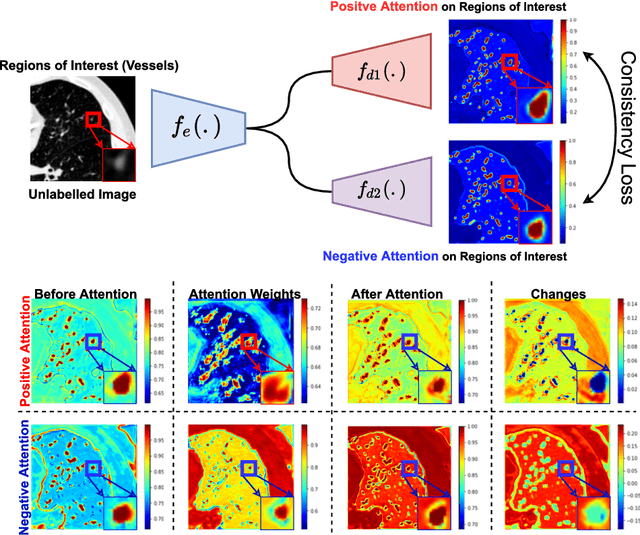

We propose MisMatch, a novel consistency-driven semi-supervised segmentation framework which produces predictions that are invariant to learnt feature perturbations. MisMatch consists of an encoder and a two-head decoders. One decoder learns positive attention to the foreground regions of interest (RoI) on unlabelled images thereby generating dilated features. The other decoder learns negative attention to the foreground on the same unlabelled images thereby generating eroded features. We then apply a consistency regularisation on the paired predictions. MisMatch outperforms state-of-the-art semi-supervised methods on a CT-based pulmonary vessel segmentation task and a MRI-based brain tumour segmentation task. In addition, we show that the effectiveness of MisMatch comes from better model calibration than its supervised learning counterpart.
MisMatch: Learning to Change Predictive Confidences with Attention for Consistency-Based, Semi-Supervised Medical Image Segmentation
Oct 23, 2021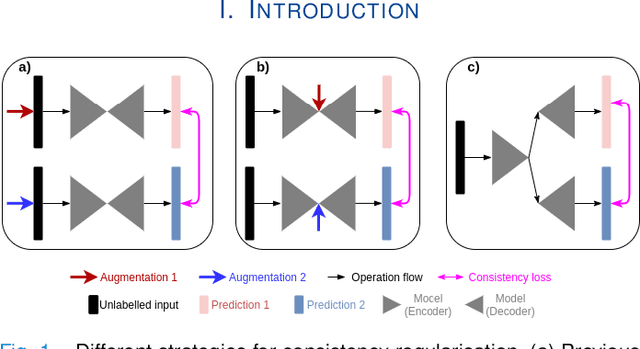

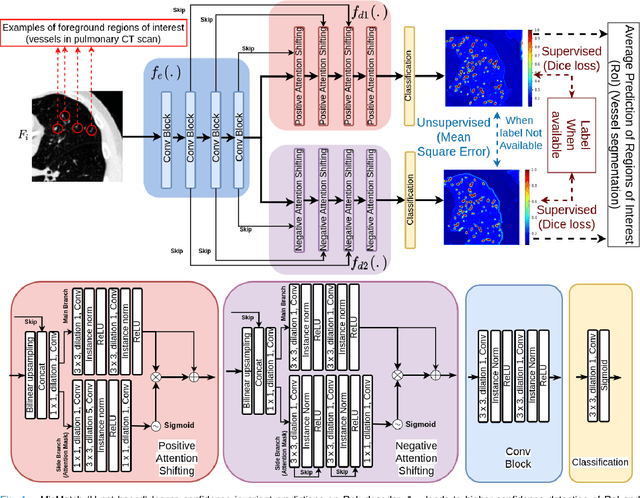
The lack of labels is one of the fundamental constraints in deep learning based methods for image classification and segmentation, especially in applications such as medical imaging. Semi-supervised learning (SSL) is a promising method to address the challenge of labels carcity. The state-of-the-art SSL methods utilise consistency regularisation to learn unlabelled predictions which are invariant to perturbations on the prediction confidence. However, such SSL approaches rely on hand-crafted augmentation techniques which could be sub-optimal. In this paper, we propose MisMatch, a novel consistency based semi-supervised segmentation method. MisMatch automatically learns to produce paired predictions with increasedand decreased confidences. MisMatch consists of an encoder and two decoders. One decoder learns positive attention for regions of interest (RoI) on unlabelled data thereby generating higher confidence predictions of RoI. The other decoder learns negative attention for RoI on the same unlabelled data thereby generating lower confidence predictions. We then apply a consistency regularisation between the paired predictions of the decoders. For evaluation, we first perform extensive cross-validation on a CT-based pulmonary vessel segmentation task and show that MisMatch statistically outperforms state-of-the-art semi-supervised methods when only 6.25% of the total labels are used. Furthermore MisMatch performance using 6.25% ofthe total labels is comparable to state-of-the-art methodsthat utilise all available labels. In a second experiment, MisMatch outperforms state-of-the-art methods on an MRI-based brain tumour segmentation task.
Learning To Pay Attention To Mistakes
Aug 07, 2020

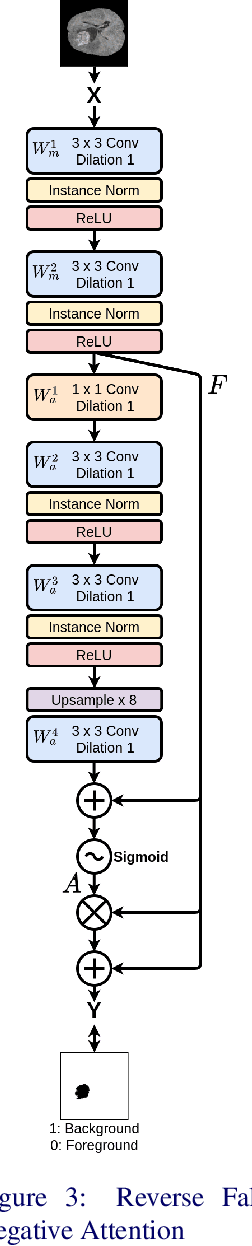
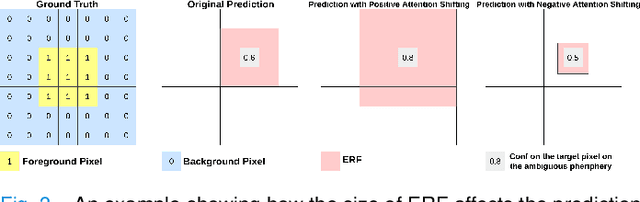
In convolutional neural network based medical image segmentation, the periphery of foreground regions representing malignant tissues may be disproportionately assigned as belonging to the background class of healthy tissues \cite{attenUnet}\cite{AttenUnet2018}\cite{InterSeg}\cite{UnetFrontNeuro}\cite{LearnActiveContour}. This leads to high false negative detection rates. In this paper, we propose a novel attention mechanism to directly address such high false negative rates, called Paying Attention to Mistakes. Our attention mechanism steers the models towards false positive identification, which counters the existing bias towards false negatives. The proposed mechanism has two complementary implementations: (a) "explicit" steering of the model to attend to a larger Effective Receptive Field on the foreground areas; (b) "implicit" steering towards false positives, by attending to a smaller Effective Receptive Field on the background areas. We validated our methods on three tasks: 1) binary dense prediction between vehicles and the background using CityScapes; 2) Enhanced Tumour Core segmentation with multi-modal MRI scans in BRATS2018; 3) segmenting stroke lesions using ultrasound images in ISLES2018. We compared our methods with state-of-the-art attention mechanisms in medical imaging, including self-attention, spatial-attention and spatial-channel mixed attention. Across all of the three different tasks, our models consistently outperform the baseline models in Intersection over Union (IoU) and/or Hausdorff Distance (HD). For instance, in the second task, the "explicit" implementation of our mechanism reduces the HD of the best baseline by more than $26\%$, whilst improving the IoU by more than $3\%$. We believe our proposed attention mechanism can benefit a wide range of medical and computer vision tasks, which suffer from over-detection of background.
Disentangling Human Error from the Ground Truth in Segmentation of Medical Images
Aug 06, 2020



Recent years have seen increasing use of supervised learning methods for segmentation tasks. However, the predictive performance of these algorithms depends on the quality of labels. This problem is particularly pertinent in the medical image domain, where both the annotation cost and inter-observer variability are high. In a typical label acquisition process, different human experts provide their estimates of the 'true' segmentation labels under the influence of their own biases and competence levels. Treating these noisy labels blindly as the ground truth limits the performance that automatic segmentation algorithms can achieve. In this work, we present a method for jointly learning, from purely noisy observations alone, the reliability of individual annotators and the true segmentation label distributions, using two coupled CNNs. The separation of the two is achieved by encouraging the estimated annotators to be maximally unreliable while achieving high fidelity with the noisy training data. We first define a toy segmentation dataset based on MNIST and study the properties of the proposed algorithm. We then demonstrate the utility of the method on three public medical imaging segmentation datasets with simulated (when necessary) and real diverse annotations: 1) MSLSC (multiple-sclerosis lesions); 2) BraTS (brain tumours); 3) LIDC-IDRI (lung abnormalities). In all cases, our method outperforms competing methods and relevant baselines particularly in cases where the number of annotations is small and the amount of disagreement is large. The experiments also show strong ability to capture the complex spatial characteristics of annotators' mistakes.