 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpenHalDet: A Unified Benchmark for Hallucination Detection across Diverse Generation Scenarios
Jun 05, 2026Hallucination detection is essential for the reliable deployment of large language models (LLMs). However, existing evaluations face two core challenges: inconsistent inference configuration and evaluation, and limited coverage of downstream domains and tasks. Consequently, reported detector performance is often difficult to compare, reproduce, and generalize beyond specific experimental settings. We introduce OpenHalDet, a unified benchmark for hallucination detection across diverse generation scenarios. OpenHalDet standardizes the evaluation pipeline, from prompt construction and response generation to truthfulness annotation, detector scoring, and metric computation. It supports heterogeneous detector families under different access settings, including black-box methods that use only generated outputs, gray-box methods that rely on probability-based signals, and white-box methods that exploit internal model signals. By bringing diverse tasks, models, and detectors into a shared framework, OpenHalDet enables controlled comparison and provides a systematic view of how different detection paradigms behave in LLM applications. We release OpenHalDet as an open and extensible codebase to facilitate reproducible evaluation and future development of hallucination detection methods. The code and datasets are available at https://github.com/Nellie179/Hallucination-Detection.
Beyond In-Domain Detection: SpikeScore for Cross-Domain Hallucination Detection
Jan 27, 2026Hallucination detection is critical for deploying large language models (LLMs) in real-world applications. Existing hallucination detection methods achieve strong performance when the training and test data come from the same domain, but they suffer from poor cross-domain generalization. In this paper, we study an important yet overlooked problem, termed generalizable hallucination detection (GHD), which aims to train hallucination detectors on data from a single domain while ensuring robust performance across diverse related domains. In studying GHD, we simulate multi-turn dialogues following LLMs initial response and observe an interesting phenomenon: hallucination-initiated multi-turn dialogues universally exhibit larger uncertainty fluctuations than factual ones across different domains. Based on the phenomenon, we propose a new score SpikeScore, which quantifies abrupt fluctuations in multi-turn dialogues. Through both theoretical analysis and empirical validation, we demonstrate that SpikeScore achieves strong cross-domain separability between hallucinated and non-hallucinated responses. Experiments across multiple LLMs and benchmarks demonstrate that the SpikeScore-based detection method outperforms representative baselines in cross-domain generalization and surpasses advanced generalization-oriented methods, verifying the effectiveness of our method in cross-domain hallucination detection.
LMGT: Optimizing Exploration-Exploitation Balance in Reinforcement Learning through Language Model Guided Trade-offs
Sep 07, 2024



The uncertainty inherent in the environmental transition model of Reinforcement Learning (RL) necessitates a careful balance between exploration and exploitation to optimize the use of computational resources for accurately estimating an agent's expected reward. Achieving balance in control systems is particularly challenging in scenarios with sparse rewards. However, given the extensive prior knowledge available for many environments, it is redundant to begin learning from scratch in such settings. To address this, we introduce \textbf{L}anguage \textbf{M}odel \textbf{G}uided \textbf{T}rade-offs (i.e., \textbf{LMGT}), a novel, sample-efficient framework that leverages the comprehensive prior knowledge embedded in Large Language Models (LLMs) and their adeptness at processing non-standard data forms, such as wiki tutorials. LMGT proficiently manages the exploration-exploitation trade-off by employing reward shifts guided by LLMs, which direct agents' exploration endeavors, thereby improving sample efficiency. We have thoroughly tested LMGT across various RL tasks and deployed it in industrial-grade RL recommendation systems, where it consistently outperforms baseline methods. The results indicate that our framework can significantly reduce the time cost required during the training phase in RL.
CogniDual Framework: Self-Training Large Language Models within a Dual-System Theoretical Framework for Improving Cognitive Tasks
Sep 05, 2024

Cognitive psychology investigates perception, attention, memory, language, problem-solving, decision-making, and reasoning. Kahneman's dual-system theory elucidates the human decision-making process, distinguishing between the rapid, intuitive System 1 and the deliberative, rational System 2. Recent advancements have positioned large language Models (LLMs) as formidable tools nearing human-level proficiency in various cognitive tasks. Nonetheless, the presence of a dual-system framework analogous to human cognition in LLMs remains unexplored. This study introduces the \textbf{CogniDual Framework for LLMs} (CFLLMs), designed to assess whether LLMs can, through self-training, evolve from deliberate deduction to intuitive responses, thereby emulating the human process of acquiring and mastering new information. Our findings reveal the cognitive mechanisms behind LLMs' response generation, enhancing our understanding of their capabilities in cognitive psychology. Practically, self-trained models can provide faster responses to certain queries, reducing computational demands during inference.
Promoting Equality in Large Language Models: Identifying and Mitigating the Implicit Bias based on Bayesian Theory
Aug 20, 2024Large language models (LLMs) are trained on extensive text corpora, which inevitably include biased information. Although techniques such as Affective Alignment can mitigate some negative impacts of these biases, existing prompt-based attack methods can still extract these biases from the model's weights. Moreover, these biases frequently appear subtly when LLMs are prompted to perform identical tasks across different demographic groups, thereby camouflaging their presence. To address this issue, we have formally defined the implicit bias problem and developed an innovative framework for bias removal based on Bayesian theory, Bayesian-Theory based Bias Removal (BTBR). BTBR employs likelihood ratio screening to pinpoint data entries within publicly accessible biased datasets that represent biases inadvertently incorporated during the LLM training phase. It then automatically constructs relevant knowledge triples and expunges bias information from LLMs using model editing techniques. Through extensive experimentation, we have confirmed the presence of the implicit bias problem in LLMs and demonstrated the effectiveness of our BTBR approach.
Thought-Like-Pro: Enhancing Reasoning of Large Language Models through Self-Driven Prolog-based Chain-of-Though
Jul 18, 2024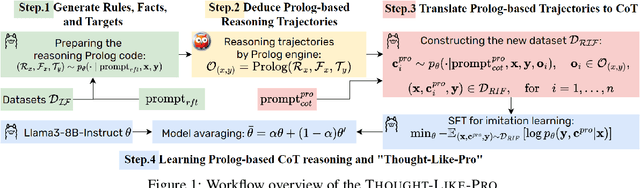
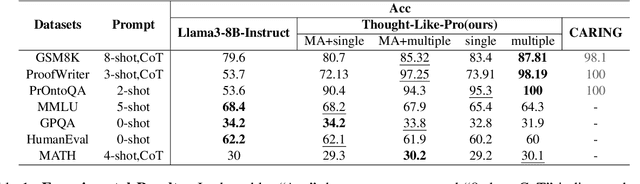
Large language models (LLMs) have shown exceptional performance as general-purpose assistants, excelling across a variety of reasoning tasks. This achievement represents a significant step toward achieving artificial general intelligence (AGI). Despite these advancements, the effectiveness of LLMs often hinges on the specific prompting strategies employed, and there remains a lack of a robust framework to facilitate learning and generalization across diverse reasoning tasks. To address these challenges, we introduce a novel learning framework, THOUGHT-LIKE-PRO In this framework, we utilize imitation learning to imitate the Chain-of-Thought (CoT) process which is verified and translated from reasoning trajectories generated by a symbolic Prolog logic engine. This framework proceeds in a self-driven manner, that enables LLMs to formulate rules and statements from given instructions and leverage the symbolic Prolog engine to derive results. Subsequently, LLMs convert Prolog-derived successive reasoning trajectories into natural language CoT for imitation learning. Our empirical findings indicate that our proposed approach substantially enhances the reasoning abilities of LLMs and demonstrates robust generalization across out-of-distribution reasoning tasks.