 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThought-Like-Pro: Enhancing Reasoning of Large Language Models through Self-Driven Prolog-based Chain-of-Though
Paper and Code
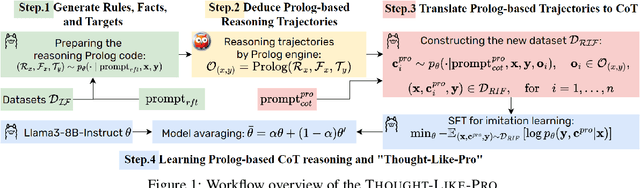
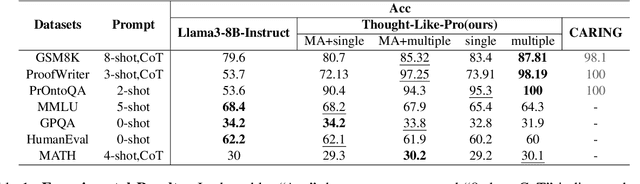
Large language models (LLMs) have shown exceptional performance as general-purpose assistants, excelling across a variety of reasoning tasks. This achievement represents a significant step toward achieving artificial general intelligence (AGI). Despite these advancements, the effectiveness of LLMs often hinges on the specific prompting strategies employed, and there remains a lack of a robust framework to facilitate learning and generalization across diverse reasoning tasks. To address these challenges, we introduce a novel learning framework, THOUGHT-LIKE-PRO In this framework, we utilize imitation learning to imitate the Chain-of-Thought (CoT) process which is verified and translated from reasoning trajectories generated by a symbolic Prolog logic engine. This framework proceeds in a self-driven manner, that enables LLMs to formulate rules and statements from given instructions and leverage the symbolic Prolog engine to derive results. Subsequently, LLMs convert Prolog-derived successive reasoning trajectories into natural language CoT for imitation learning. Our empirical findings indicate that our proposed approach substantially enhances the reasoning abilities of LLMs and demonstrates robust generalization across out-of-distribution reasoning tasks.