 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDPFlow: Adaptive Optical Flow Estimation with a Dual-Pyramid Framework
Mar 19, 2025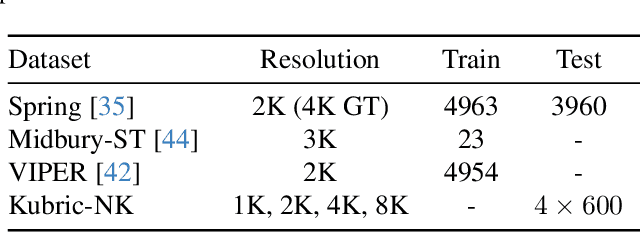
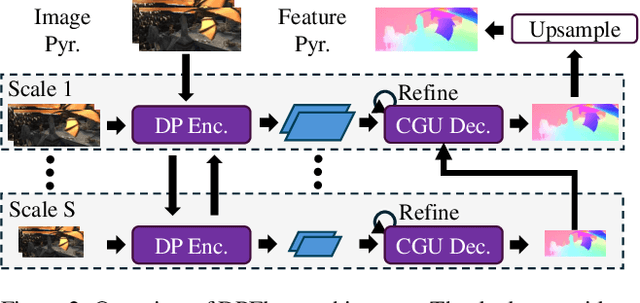
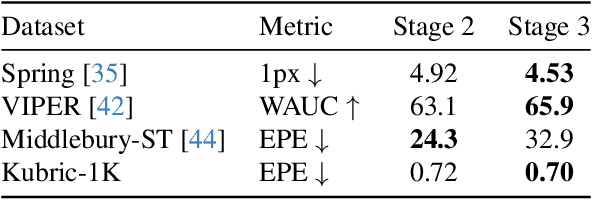
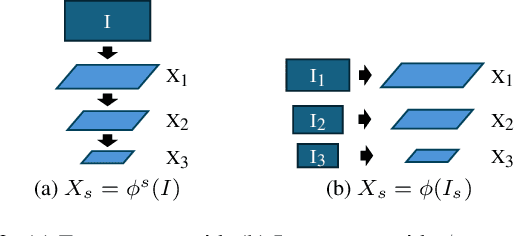
Optical flow estimation is essential for video processing tasks, such as restoration and action recognition. The quality of videos is constantly increasing, with current standards reaching 8K resolution. However, optical flow methods are usually designed for low resolution and do not generalize to large inputs due to their rigid architectures. They adopt downscaling or input tiling to reduce the input size, causing a loss of details and global information. There is also a lack of optical flow benchmarks to judge the actual performance of existing methods on high-resolution samples. Previous works only conducted qualitative high-resolution evaluations on hand-picked samples. This paper fills this gap in optical flow estimation in two ways. We propose DPFlow, an adaptive optical flow architecture capable of generalizing up to 8K resolution inputs while trained with only low-resolution samples. We also introduce Kubric-NK, a new benchmark for evaluating optical flow methods with input resolutions ranging from 1K to 8K. Our high-resolution evaluation pushes the boundaries of existing methods and reveals new insights about their generalization capabilities. Extensive experimental results show that DPFlow achieves state-of-the-art results on the MPI-Sintel, KITTI 2015, Spring, and other high-resolution benchmarks.
Zero and R2D2: A Large-scale Chinese Cross-modal Benchmark and A Vision-Language Framework
May 08, 2022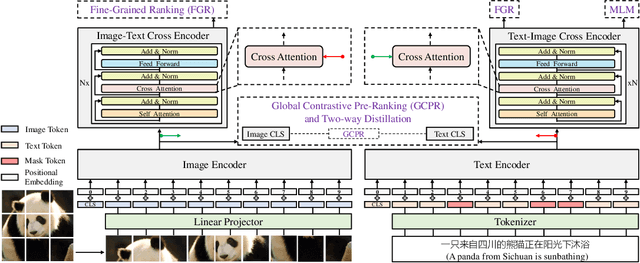
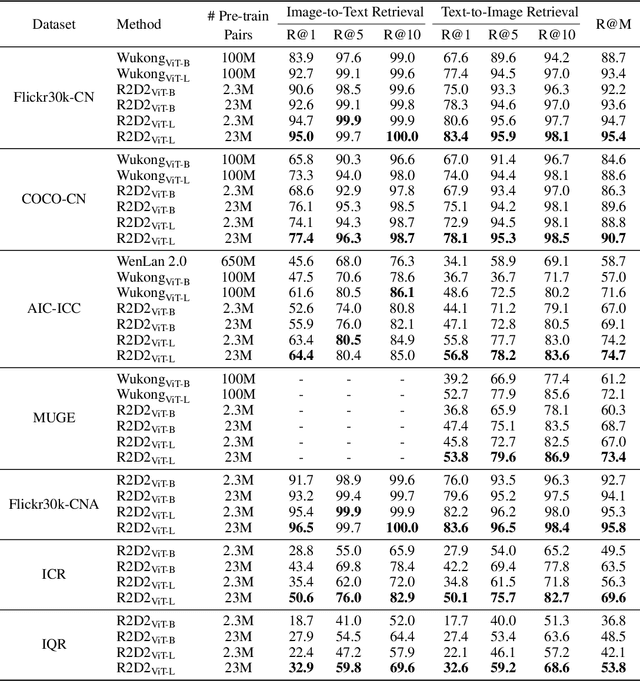

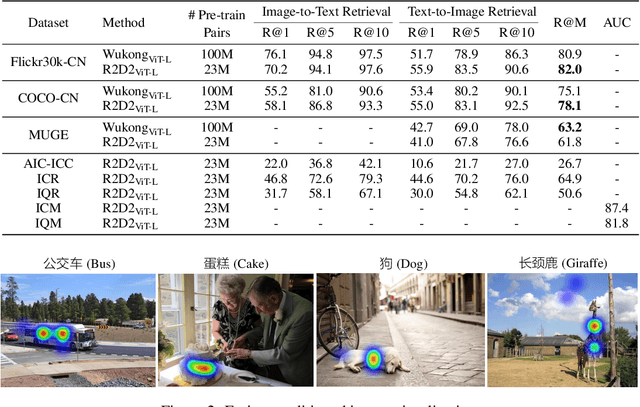
Vision-language pre-training (VLP) relying on large-scale pre-training datasets has shown premier performance on various downstream tasks. In this sense, a complete and fair benchmark (i.e., including large-scale pre-training datasets and a variety of downstream datasets) is essential for VLP. But how to construct such a benchmark in Chinese remains a critical problem. To this end, we develop a large-scale Chinese cross-modal benchmark called Zero for AI researchers to fairly compare VLP models. We release two pre-training datasets and five fine-tuning datasets for downstream tasks. Furthermore, we propose a novel pre-training framework of pre-Ranking + Ranking for cross-modal learning. Specifically, we apply global contrastive pre-ranking to learn the individual representations of images and Chinese texts, respectively. We then fuse the representations in a fine-grained ranking manner via an image-text cross encoder and a text-image cross encoder. To further enhance the capability of the model, we propose a two-way distillation strategy consisting of target-guided Distillation and feature-guided Distillation. For simplicity, we call our model R2D2. We achieve state-of-the-art performance on four public cross-modal datasets and our five downstream datasets. The datasets, models and codes will be made available.
Exploring Structure for Long-Term Tracking of Multiple Objects in Sports Videos
Dec 19, 2016


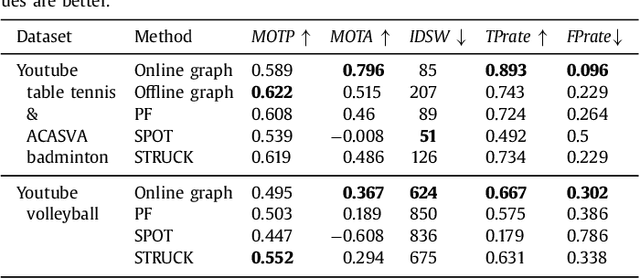
In this paper, we propose a novel approach for exploiting structural relations to track multiple objects that may undergo long-term occlusion and abrupt motion. We use a model-free approach that relies only on annotations given in the first frame of the video to track all the objects online, i.e. without knowledge from future frames. We initialize a probabilistic Attributed Relational Graph (ARG) from the first frame, which is incrementally updated along the video. Instead of using the structural information only to evaluate the scene, the proposed approach considers it to generate new tracking hypotheses. In this way, our method is capable of generating relevant object candidates that are used to improve or recover the track of lost objects. The proposed method is evaluated on several videos of table tennis, volleyball, and on the ACASVA dataset. The results show that our approach is very robust, flexible and able to outperform other state-of-the-art methods in sports videos that present structural patterns.